Java基础
资料内容大部分来自技术博客,仅作个人学习参考使用。
前言
底层基础决定上层建筑
对于半路转行到计算机软件编程行业的非科班,或者在大学时期没有认真学习和真正掌握技术知识的科班生,又或者毕业前参加培训班的应届生,这样一批人的基础功底是相对比较薄弱的,毕竟Java是一门容易入门的编程语言,比C、C++、Python都容易,报个培训班,或者看视频教程和资料书籍自学3~6个月,轻松入门,再到网上找几个工作项目,梳理下项目中的技术要点,再做一些面试、笔试题目,拿到中小公司offer的几率还是比较大的。
说到培训班,很想补充几句。培训班可不可以报?网上的云课堂是否建议报名?
名师出高徒,好的老师,好的教学资源,肯定是对学生有利的。但问题是,现在的培训班教学质量参差不齐,很多同学没有项目经验;老师讲的技术点又脱离实际工作项目;教学技术要点不会太深入,太难会导致很多人听不懂,反而影响教学质量和同学信心;老师带进门,修行靠个人;报班学费通常也不便宜,少则好几千,多则好几万;即使学费不是问题,学习的周期跨度也会影响到找工作的时机。想要技术真正有提升,时间精力投入肯定是不能少的,培训班能提供一个比较好的学习氛围,这个是肯定的。很多人同样花几个月的学习时间,在宿舍自学却被各种生活琐事缠绕,饮食不健康、起居作息不规律,严重影响学习效率和进展。
至于网上的云课堂,有的教学技术内容确实比较硬核,技术前沿,深度广度都涉及,当然好的教学资源收费高一点是值得的,跟买产品一样,大牌子难免价格会高一点。只要不是注水参假的低质量教学内容,或者教学内容没有达到宣传级别,水货买高价,这是最令人反感的。
个人觉得工作三年以上的朋友,应该是对行业内涉及到的技术栈有所了解的了,到哪学,怎么学,已经是烙在脑海里的行为习惯了,学习习惯和学习方法才是真正提升技术能力水平的关键。工作三五年,绝大部分工作时间在做重复繁杂的CRUD,工作之余的零碎时间和周末假期,也大多数没花在技术学习上,呆在舒适圈里,“温水煮青蛙”,不到疼痛要命的关键时刻,是不会轻易醒来的。毕业三五年,确实是拉开差距的关键时期。但多数人道理都懂,然而该玩还是玩,游戏娱乐,懒散放纵,相比于别人,优秀的人都还在奔跑,而贫困的人却在原地享乐。别人每天都投入几个小时学习,周末假期也不放松进度,根本不用三年,差距很快就拉开了。
“温水煮青蛙”,三五年一转眼就过去了,你终于感受到了疼痛,开始觉醒了。发现原来自己已经严重脱轨,白白浪费了好几年最宝贵的年轻年华。身边的同年人多数工作稳定了;买房了;有对象准备结婚了,再看看自己,还窝在破旧的出租房,懒散放纵。你是真的不知道死字怎么写吗?别再安逸地窝在舒适圈里了,还不抓住最后一两年的冲刺机会,马上就接近35岁中年危机了,真到那个时候,还是一事无成的话,这辈子就真的玩完了!
技术学习记忆有主干和重点
技术学习跟高中、大学的课程学习一样,高中九门课程,每门课都有知识主干及重难点,真正的高分拉分题也往往就是这些主干要点,其他概念记忆内容,通常只要整体过一遍,就能对这些细枝末节的知识内容有个印象(这里说的是理科生,对于文科生,该背该记的知识内容分数比重也不小),考试或者面试的时候,凭着脑海里的印象,结合主干知识点内容,也能推理出答案。至于那些就是要背要记的概念知识,没记自然就只能猜了。
到了工作中,如果你不是做老师教学的话,技术栈里面的纯概念的内容真的没有重复记忆必要。技术领域发展迅速,今年很热门很流行的技术框架,可能明年就走下坡路了。对于想要进阶技术架构师的人来说,要掌握的技术栈内容真的多,技术深度和广度都要达到领先水平。
工作中先要掌握的应该是技术栈中经常用到或者需要用到的技术点,以及那些可能出问题的,或者可以优化的点,实践运用为主,梳理记忆为辅,练习和记忆都重要,相辅相成。对于其中纯概念的语言描述,用自己的话表达就可以了。那些基本不会出问题的或者已经不能优化的参数配置,工作中根本不会去接触和改动,谁没事去做那些改了只有坏处没有好处的事情?
如果你是面试官,你会问什么类型性质的问题?最反感哪些类型问题?
偏好问题类型
- 不知道很可能会导致生产事故的技术点
- 知道会达到事半功倍效果的技术点
- 能体现个人真正爱钻研的问题,并且钻研的事情有意义(大厂面试官喜欢沿着一个技术点不停地深挖)
- 明确公司职位需求和技能要求,突出主干和重点,不刻意问那些偏门冷门题目刁难求职者,显得自己不够大气
- 限定 30 秒让求职者自我介绍,简历事先花几分钟看一遍,听求职者表达的内容和特点
- 根据公司规模和招人紧迫程度,适当调整技术难度,人才,人,才。
反感问题类型
- 平时工作根本用不到的大篇幅的理论概念
- 不知道也不会影响日常工作的技术点
- 公司不用,但可以体现公司技术前瞻性的技术点(碍于面子)
- 面试官自己没有明确要点,看到什么问什么,甚至瞎扯瞎聊,被求职者带着走,最后凭聊天过程感觉舒适程度做决定
- 让人自我介绍,自己埋头看简历(不是为了避免尴尬假装在看简历实际在听,而是真的没看简历)
基础概念
理论概念是认识熟悉一样东西的前提,学习的过程都是从基本概念开始。
可能是因为理科生的缘故,本人非常不喜欢那些通篇长段的概念文字,一是难记,二是很容易忘,三是记了也几乎没什么用!
工作越久就反感那些考查文字概念背诵的应试,如果我是出题人或面试官,一定不会把理论概念作为考查重点,作用意义真的不大!
应对措施:
原文概念先自己理解几遍,然后用自己的实践或生活经历,转述表达就好了。
文科生的话,背诵记忆的内容还是很多的,高中那会我背诵和记忆力也不错,但还是选择了理科。
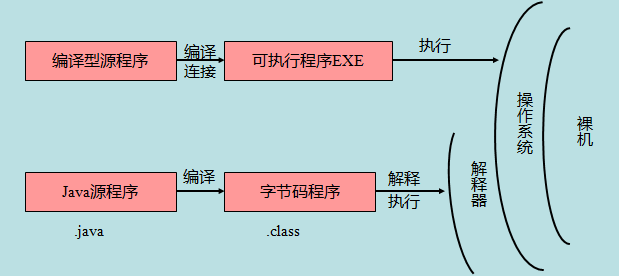
Java 源程序与编译型运行区别
数据类型
8 种基础数据类型
| 数据类型 | 关键字 | 占用字节 | 取值范围 | 默认值 |
|---|---|---|---|---|
| 布尔型 | boolean | 1|4 | true/false | false |
| 字节型 | byte | 1 | -128 ~ 127 (-27 ~ 27-1) | 0 |
| 短整型 | short | 2 | -215 ~ 215-1 | 0 |
| 字符型 | char | 2 | 0 ~ 216-1 char 类型是一个单一的 16 位 Unicode 字符;最小值是 \u0000(十进制等效值为 0);最大值是 \uffff(即为 65535) | ‘\u0000’ |
| 整型 | int | 4 | -231 ~ 231-1(10位) | 0 |
| 单精度浮点型 | float | 4 | 1.4013E-45 (2的-149次方)~3.4028235E38 (2的128次方-1)有效位数为 6 ~ 7 位 | 0.0F |
| 双精度浮点型(小数类型默认) | double | 8 | 4.9E-324 (2的-1074次方)~1.7977E308 (2的1024次方-1)有效位数为 15 位 | 0.0D |
| 长整型 | long | 8 | -263 ~ 263-1 | 0L |
Java 中各种空(""、\u0000、null)的区别
String s1 = "";
String s2 = "\u0000";
String s3 = null;s1、s2、s3的区别,分别在字符串常量池和栈中的储存情况?
从class字节码的角度来理解吧 1.String s1 = ""的情况,下面是编译后的字节码,可以看到,这种情况s1="aaa"其实没什么区别的,都是从常量池推一个字符串到栈顶,并赋给本地变量。
0: ldc #16 // String
2: astore_1
3: return2.String s2=null的情况,这个时候,并没有在常量池中生成任何的字符串常量,仅仅是将null推送到栈顶赋值给变量。
0: aconst_null
1: astore_1
2: return3.String s3 = "u0000"的情况,会在常量池生成一个表示NUL的一个字符串,也就是所谓的Control Character。
0: ldc #16 // String NUL
2: astore_1
3: returnfloat、double 精度范围计算
数据存储的底层原理,有些难理解,也很容易忘,毕竟用得很少。知道一些底层实现原理可以提高编程境界,也可以面试加分。
float、double 为什么会丢失精度
有效位数长度是固定的,当一个十进制数转二进制,存在无限循环的时候,有效位数自然就不够用了,这就造成了精度丢失。
就跟十进制无法用小数完全表示1/3一样。
单精度与双精度是什么意思,有什么区别
单精度是这样的格式,1位符号,8位指数,23位小数。

双精度是1位符号,11位指数,52位小数。
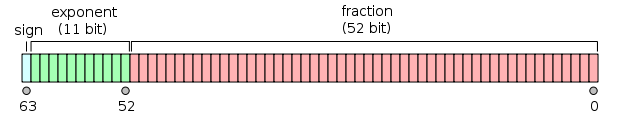
含义:表明单精度和双精度精确的范围不一样,单精度,也即float,一般在计算机中存储占用4字节,也32位,有效位数为7位;双精度(double)在计算机中存储占用8字节,64位,有效位数为16位。
原因:不管float还是double 在计算机上的存储都遵循IEEE规范,使用二进制科学计数法,都包含三个部分:符号位,指数位和尾数部分。其中float的符号位,指数位,尾数部分分别为1, 8, 23. 双精度分别为1, 11, 52。
精度主要取决于尾数部分的位数,float为23位,除去全部为0的情况以外,最小为2的-23次方,约等于1.19乘以10的-7次方,所以float小数部分只能精确到后面6位,加上小数点前的一位,即有效数字为7位。 类似,double 尾数部分52位,最小为2的-52次方,约为2.22乘以10的-16次方,所以精确到小数点后15位,有效位数为16位。
float 初始化赋值
float类型的数值有一个后缀F或f (例如,3.14 F),没有后缀F的浮点数值(例如,3.14)默认为double类型,double类型的后缀为D或d(例如,3.14D)。
(考试、面试就喜欢考这些只要没记住就会犯错的小问题,然而实际开发中,float赋值不加后缀F,编译器自然就会报错提示,现在很多这类靠记住的小问题,编译器都能帮你校验了,人类文明在飞速地向前发展,新一代的小孩子要掌握的知识内容越来越多,人类文明上千年的历史,总不能一直在背诵记忆吧,从小到大背啊记啊的内容还不多吗,毕业工作几年后,那些工作中用不到的知识,还有几个人能记得住?!用进废退,学以致用,应需主动学习,学习成果驱动,才是最高效地学习方式,那些为了应付考试、面试,“应试教育”学过的知识内容,一旦出了学校,工作中用不到,分分钟忘得干干净净!)
浮点运算小数位注意事项
二进制要能精确表示一个数的前提是,这个数要能写成 x*2^n的组合。
二进制不能精确表示1/10,就好像十进制不能精确表示1/3一样。
因为1/10不能写成 x*2^n的组合。
举例
0(十进制)=0*2^0=0000(二进制)
1(十进制)=1*2^0=0001(二进制)
2(十进制)=1*21+0*20=0010(二进制)
3(十进制)=1*21+1*20=0011(二进制)
4(十进制)=122+0*21+02^0=0100(二进制)
1/2(十进制)=1*2^-1=(这个转换就要用补码和反码了吧 记不住怎么表示了)
《Effective Java》中提到一个原则,那就是float和double只能用来作科学计算或者是工程计算,但在商业计算中我们要用java.math.BigDecimal,通过使用BigDecimal类可以解决上述问题,java的设计者给编程人员提供了一个很有用的类BigDecimal,他可以完善float和double类无法进行精确计算的缺憾。
使用BigDecimal,但一定要用BigDecimal(String)构造器,而千万不要用BigDecimal(double)来构造(也不能将float或double型转换成String再来使用BigDecimal(String)来构造,因为在将float或double转换成String时精度已丢失)。
3*0.1 == 0.3 true 还是 false?
false,因为有些浮点数不能完全精确的表示出来。0.3 用二进制不能完全表示。
BigDecimal 怎样保证精度
BigDecimal保证精度的解决思路其实极其的简单朴素:(小数转成整数运算,最后还原精度位数)
十进制整数在转化成二进制数时不会有精度问题,那么把十进制小数扩大N倍让它在整数的维度上进行计算,并保留相应的精度信息。
注意:
MySql中的统计函数:sum()、avg()等等,给JAVA应用默认返回的是Double类型!在处理小数的时候可能产生精度问题,此时把预处理的字段数据用cast强转成decimal类型,那么MySql给JAVA应用返回的就是BigDecimal类型。
int 和 Integer 的区别
类型:基础类型 vs 封装类型
内存:栈 vs 堆
取值:直接取值 vs -128~127缓存
传递:值传递 vs 引用传递
比较:>、<、== vs >、<、equals
int是基础数据类型,字节长度为4,它的创建不会在堆内存中开辟空间,一般保存在栈内存里,可以用算术运算符进行加减乘除等操作。在参数传递的时候,直接传递它的值。
Integer是int的包装类,本质是一个类,它的创建会在堆内存中开辟一块新的空间。它的含义也是表示整型的数字,但是,算术运算符不能操作它,需要进行自动拆装箱之后才能运算。在参数传递的时候,传递的是它所代表的对象的一个引用。
缓存池
new Integer(123) 与 Integer.valueOf(123) 的区别
- new Integer(123) 每次都会新建一个对象
- Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false
Integer z = Integer.valueOf(123);
Integer k = Integer.valueOf(123);
System.out.println(z == k); // truevalueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}基本类型对应的缓冲池如下:
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
在使用这些基本类型对应的包装类型时,就可以直接使用缓冲池中的对象。
数字可以加下划线表示
JDK1.7开始,数字字面量可以加下划线,便于按习惯阅读,编译器会自动去掉这些下划线。比如,int最大值可以表示为2_147_483_647。
char 类型
Java中,char占2字节,16位,可以存放汉字。
char赋值
char a='a'; // 任意单个字符,加单引号。
char a='中'; // 任意单个中文字,加单引号。
char a=111; // 整数。0~65535。十进制、八进制、十六进制均可。输出Unicode字符编码表中对应的字符。
注:只能放单个字符。
char运算
char类型是可以运算的因为char在ASCII等字符编码表中有对应的数值。
在Java中,对char类型字符运行时,直接当做ASCII表对应的整数来对待。
示例:
char m='a'; ——a。
char m='a'+'b'; ——Ã。 //char类型相加,提升为int类型,输出对应的字符。注,在CMD.exe用输出结果是问题?,不同的编码输出显示不一样。Eclipse中须改成UTF-8。
int m='a'+'b'; ——195。//195没有超出int范围,直接输出195。
char m='a'+b; ——报错。//因为b是一个赋值的变量。
char m=197; ——Ã。 //输出字符编码表中对应的字符。
char m='197; ——报错。//因为有单引号,表示是字符,只允许放单个字符。
char m='a'+1; ——b。//提升为int,计算结果98对应的字符是b。
char m='中'+'国'; ——42282。
char m='中'+'国'+'国'+'国'; ——报错。int转char有损失。因为结果已经超出char类型的范围。
int m='中'+'国'+'国'+'国'; ——86820
char m='中'+1; ——丮。//1是int,结果提升为int,输出对应的字符。
char m='中'+"国"; ——报错。String无法转换为char。
System.out.println('中'+"国"); ——中国。//没有变量附值的过程。String与任何字符用“+”相连,转换为String。
总结:
用单引号''标识,只能放单个字符。
char+char,char+int——类型均提升为int,附值char变量后,输出字符编码表中对应的字符。
变量类型
- https://www.runoob.com/java/java-variable-types.html
在Java语言中,所有的变量在使用前必须声明。声明变量的基本格式如下:
type identifier [ = value][, identifier [= value] ...] ;
例:
int a, b, c; // 声明三个int型整数:a、 b、c
int d = 3, e = 4, f = 5; // 声明三个整数并赋予初值
byte z = 22; // 声明并初始化 z
String s = "runoob"; // 声明并初始化字符串 s
double pi = 3.14159; // 声明了双精度浮点型变量 pi
char x = 'x'; // 声明变量 x 的值是字符 'x'。Java语言支持的变量类型有:
- 类变量:独立于方法之外的变量,用 static 修饰。
- 实例变量:独立于方法之外的变量,不过没有 static 修饰。
- 局部变量:类的方法中的变量。注意,局部变量需要声明且初始化值之后才能使用!
public class Variable{
static int allClicks=0; // 类变量
String str="hello world"; // 实例变量
public void method(){
int i =0; // 局部变量
}
}类变量(静态变量)
理论概念结合实例代码理解记忆,死记硬背费时费精力且回报小,过段时间不重复记忆,肯定忘得一干二净!!
- 类变量也称为静态变量,在类中以 static 关键字声明,但必须在方法之外。
- 无论一个类创建了多少个对象,类只拥有类变量的一份拷贝。
- 静态变量除了被声明为常量外很少使用,静态变量是指声明为 public/private,final 和 static 类型的变量。final 修饰的静态变量初始化后不可改变。
- 静态变量储存在静态存储区。经常被声明为常量,很少单独使用 static 声明变量。
- 静态变量在第一次被访问时创建,在程序结束时销毁。
- 与实例变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为 public 类型。
- 默认值和实例变量相似。数值型变量默认值是 0,布尔型默认值是 false,引用类型默认值是 null。变量的值可以在声明的时候指定,也可以在构造方法中指定。此外,静态变量还可以在静态语句块中初始化。
- 静态变量可以通过:ClassName.VariableName的方式访问。
- 类变量被声明为 public static final 类型时,类变量名称一般建议使用大写字母。如果静态变量不是 public 和 final 类型,其命名方式与实例变量以及局部变量的命名方式一致。
实例变量
- 实例变量声明在一个类中,但在方法、构造方法和语句块之外;
- 当一个对象被实例化之后,每个实例变量的值就跟着确定;
- 实例变量在对象创建的时候创建,在对象被销毁的时候销毁;
- 实例变量的值应该至少被一个方法、构造方法或者语句块引用,使得外部能够通过这些方式获取实例变量信息;
- 实例变量可以声明在使用前或者使用后;
- 访问修饰符可以修饰实例变量;
- 实例变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把实例变量设为私有。通过使用访问修饰符可以使实例变量对子类可见;
- 实例变量具有默认值。数值型变量的默认值是0,布尔型变量的默认值是false,引用类型变量的默认值是null。变量的值可以在声明时指定,也可以在构造方法中指定;
- 实例变量可以直接通过变量名访问。但在静态方法以及其他类中,就应该使用完全限定名:ObejectReference.VariableName。
局部变量
- 局部变量声明在方法、构造方法或者语句块中;
- 局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,变量将会被销毁;
- 访问修饰符不能用于局部变量;
- 局部变量只在声明它的方法、构造方法或者语句块中可见;
- 局部变量是在栈上分配的。
- 局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
Java 运算符
运算符优先级

位运算
位运算符作用在所有的位上,并且按位运算。假设 A = 60,B = 13;它们的二进制格式表示将如下:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~A= 1100 0011下表列出了位运算符的基本运算,假设整数变量 A 的值为 60 和变量 B 的值为 13:
| 操作符 | 描述 | 例子 |
|---|---|---|
| & | 如果相对应位都是1,则结果为1,否则为0 | (A&B),得到12,即0000 1100 |
| | | 如果相对应位都是 0,则结果为 0,否则为 1 | (A | B)得到61,即 0011 1101 |
| ^ | 如果相对应位值相同,则结果为0,否则为1 | (A ^ B)得到49,即 0011 0001 |
| 〜 | 按位取反运算符翻转操作数的每一位,即0变成1,1变成0。 | (〜A)得到-61,即1100 0011 |
| << | 按位左移运算符。左操作数按位左移右操作数指定的位数。 | A << 2得到240,即 1111 0000 |
| >> | 按位右移运算符。左操作数按位右移右操作数指定的位数。 | A >> 2得到15即 1111 |
| >>> | 按位右移补零操作符。左操作数的值按右操作数指定的位数右移,移动得到的空位以零填充。 | A>>>2得到15即0000 1111 |
2 << 2 = 8,将值每左移1次,就相当于该值乘以2,这里左移2,则是2乘以2的2次方。
35 >> 2 = 8,将值每右移1次,就相当于该值除以2并且舍弃余数,这里右移2,则是35除以2的2次方。
注意,无符号右移>>>与带符号右移>>的区别就是,无符号始终补0,另外,没有“无符号左移 <<<”这个运算符,因为不需要。
自增自减
自增(++)自减(--)运算符是一种特殊的算术运算符,在算术运算符中需要两个操作数来进行运算,而自增自减运算符是一个操作数。
前缀自增自减法(++a,--a): 先进行自增或者自减运算,再进行表达式运算
后缀自增自减法(a++,a--): 先进行表达式运算,再进行自增或者自减运算
Java 中 ++ 操作符是线程安全的吗?
不是线程安全的操作。它涉及到多个指令,如读取变量值,增加,然后存储回内存,这个过程可能会出现多个线程交差。还会存在竞态条件(读取-修改-写入)。
instanceof
检查该对象是否是一个特定类型(类类型或接口类型)。
instanceof运算符使用格式如下:
( Object reference variable ) instanceof (class/interface type)String name = "James";
boolean result = name instanceof String; // 由于 name 是 String 类型,所以返回真如果被比较的对象兼容于右侧类型,该运算符仍然返回true。
public class Cat extends Animal {
private String name;
private int age;
private String color;
public static void main(String[] args) {
Animal c = new Cat();
System.out.println(c instanceof Animal); // true
System.out.println(c instanceof Cat); // true
Animal a = new Animal();
System.out.println(a instanceof Cat); // false
}
}两个 int 数值交换,不使用第三个中间变量
// 第一种方法,数学运算。(搞不明白省一个中间变量能省多少内存空间)
a = a + b;
b = a - b;
a = a - b;
// 第二种方法,位异或运算
a = a^b;
b = a^b;
a = a^b;
// 第三种方法,使用指针(java中不能直接使用指针)
int *pa = &a;
int *pb = &b;
*pa = b;
*pb = a;a = a + b 与 a += b 的区别
+= 隐式的将加操作的结果类型强制转换为持有结果的类型。如果两这个整型相加,如 byte、short 或者 int,首先会将它们提升到 int 类型,然后在执行加法操作。
byte a = 127;
byte b = 127;
a = a + b; // error : cannot convert from int to byte
a += b; // oka+b 操作会将 a、b 提升为 int 类型,所以将 int 类型赋值给 byte 就会编译出错
+= 能强制转换为最终持有的 byte 类型
“a==b”和”a.equals(b)”有什么区别?
如果 a 和 b 都是对象,则 a==b 是比较两个对象的引用,只有当 a 和 b 指向的是堆中的同一个对象才会返回 true,而 a.equals(b) 是进行逻辑比较,所以通常需要重写该方法来提供逻辑一致性的比较。例如,String 类重写 equals() 方法,所以可以用于两个不同对象,但是包含的字母相同的比较。
小结
- == 基本类型比较数值是否相等,对象比较引用地址是否相等。
- equals 比较的对象内容是否相等(前提是重写了父类的方法)。
- 一般除了自定义的类除外,大部分能够使用的类都重写了equals()方法。
十进制与二进制转换
https://www.runoob.com/w3cnote/decimal-decimals-are-converted-to-binary-fractions.html
二进制数转换成十进制数
由二进制数转换成十进制数的基本做法是,把二进制数首先写成加权系数展开式,然后按十进制加法规则求和。这种做法称为"按权相加"法。
例如把二进制数 110.11 转换成十进制数。
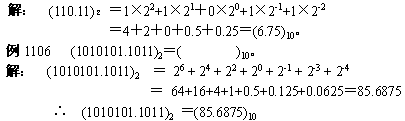
十进制数转换为二进制数
十进制数转换为二进制数时,由于整数和小数的转换方法不同,所以先将十进制数的整数部分和小数部分分别转换后,再加以合并。
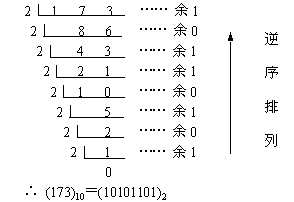
十进制整数转换为二进制整数
十进制整数转换为二进制整数采用"除2取余,逆序排列"法。具体做法是:用2去除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为零时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。
例如把 (173)10 转换为二进制数。
解:
十进制小数转换为二进制小数
十进制小数转换成二进制小数采用乘2取整,顺序排列法。具体做法是:用2乘十进制小数,可以得到积,将积的整数部分取出,再用2乘余下的小数 部分,又得到一个积,再将积的整数部分取出,如此进行,直到积中的小数部分为零,或者达到所要求的精度为止。
然后把取出的整数部分按顺序排列起来,先取的整数作为二进制小数的高位有效位,后取的整数作为低位有效位。
例如把(0.8125)转换为二进制小数。
解:

例:
(173.8125)10=( )2解:
在上个例子中得(173)10=(10101101)2
得(0.8125)10=(0.1101)2把整数部分和小数部分合并得:
(173.8125)10=(10101101.1101)2十进制小数转换成二进制小数采用"乘2取整,顺序排列"法。具体做法是:用2乘十进制小数,可以得到积,将积的整数部分取出,再用2乘余下的小数部分,又 得到一个积,再将积的整数部分取出,如此进行,直到积中的整数部分为零,或者整数部分为1,此时0或1为二进制的最后一位。或者达到所要求的精度为止。
然后把取出的整数部分按顺序排列起来,先取的整数作为二进制小数的高位有效位,后取的整数作为低位有效位。
十进制小数转二进制
如:0.625=(0.101)B
0.625*2=1.25======取出整数部分1
0.25*2=0.5========取出整数部分0
0.5*2=1==========取出整数部分1再如:0.7=(0.1 0110 0110...)B
0.7*2=1.4========取出整数部分1
0.4*2=0.8========取出整数部分0
0.8*2=1.6========取出整数部分1
0.6*2=1.2========取出整数部分1
0.2*2=0.4========取出整数部分0
0.4*2=0.8========取出整数部分0
0.8*2=1.6========取出整数部分1
0.6*2=1.2========取出整数部分1
0.2*2=0.4========取出整数部分0String 字符串
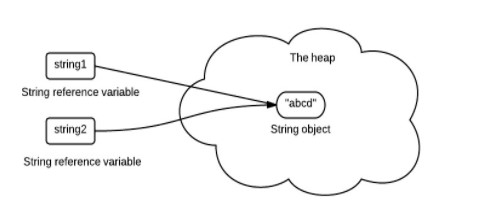
Java中为什么把String类设计为final类型?有什么优势和弊端?
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];String 被声明为 final,因此它不可被继承。
内部使用 char 数组存储数据,该数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
不可变的好处
1. 可以缓存 hash 值
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
2. String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
3. 安全性
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 对象的那一方以为现在连接的是其它主机,而实际情况却不一定是。
4. 线程安全
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
一个final是修饰了String类,而另一个final修饰了char数组。
都是为了安全和效率。
final char value[] 的final 要抓住几个关键点是:value[] 数组的 final 用于限制字符数组的修改。字符串将会被大量使用,从性能上考虑迫使Java语言的设计者将 char[] 设计为共享的,又因为字符串是共享的再次迫使设计者考虑到线程安全性,这才需要用final来修饰,避免并发场景下的行为不可预测。
final class 的final 要抓住几个关键点是:类上的final用于限制产生子类(或限制多态/或限制行为的变化)。字符串的使用是频繁的,如果通过多态的方式使用String子类对象及其方法将会一定程度上导致性能下降(多态的实现原理:底层的虚函数表),同时String中的方法也可能面临被Override重写的危险导致程序语义不安全、甚至是逻辑错误,与Java自始至终强调的安全性理念相违背。
String 的 hashCode 方法
/**
* Returns a hash code for this string. The hash code for a
* {@code String} object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using {@code int} arithmetic, where {@code s[i]} is the
* <i>i</i>th character of the string, {@code n} is the length of
* the string, and {@code ^} indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i]; // 降低哈希算法的冲突率
}
hash = h;
}
return h;
}String类中的hashCode计算方法是以31为权,每一位为字符的ASCII值进行运算,用自然溢出来等效取模。
为什么以31为权?其他数值可以吗?
选择31的理由。从网上的资料来看,一般有如下两个原因:
第一,31是一个不大不小的质数,是作为 hashCode 乘子的优选质数之一。另外一些相近的质数,比如37、41、43等等,也都是不错的选择。那么为啥偏偏选中了31呢?请看第二个原因。
第二,31可以被 JVM 优化
31 * i = (32 - 1) * i = 32 * i - i = (i << 5) - iString、StringBuilder、StringBuffer 三者的区别
这三个类之间的区别主要是在两个方面,即运行速度和线程安全这两方面。
首先说运行速度,或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer > String
String最慢的原因:
String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的。
在线程安全上,StringBuilder是线程不安全的,而 StringBuffer 是线程安全的。
总之
String:适用于少量的字符串操作的情况。
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况。
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况。
Java 从一个文本文件里面统计某个字符串出现的次数
package com.jn.test;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.Scanner;
public class StringTimes {
public static int getKeyStringCount(String str, String key) {
int count = 0;
int index = 0;
while((index = str.indexOf(key,index))!=-1){
index = index + key.length();
count++;
}
return count;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
File file = new File("D:/设计模式.txt");
FileInputStream fis = null;
try{
fis = new FileInputStream(file);
int len = 0;
byte[] buf = new byte[1024];
String str = null;
while((len = fis.read(buf)) !=-1){
str = new String(buf, 0, len,"GBK");
}
Scanner sc = new Scanner(System.in);
System.out.println("请输入你要查询字符串:");
String key = sc.nextLine();
int count = getKeyStringCount(str,key);
System.out.println("文件中此字符串出现次数为:"+count+"次");
}catch(FileNotFoundException e){
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
fis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}package com.xixi.test02;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//从文件(D:\\test.txt)中查出字符串”test”出现的次数?
public class Test03 {
public static void main(String[] args) {
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader("D:\\test.txt"));
StringBuffer sb = new StringBuffer();
String str = null;
while((str = br.readLine()) != null) {
sb.append(str);
}
String regex = "test";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(sb);
int num = 0;
while(matcher.find()) {
num++;
}
System.out.println("次数为: " + num);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
if(null != br) {
//关闭资源
br.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}String 细节补充
- 从JDK1.7开始,switch条件语句支持String类型。
String 考查要点
- intern() 方法存入常量池的内容
下面的代码输入什么
String s1 = "abc";
String s2 = new String("abc");
s2.intern();
System.out.println(s1 == s2); // false,一个在字符串常量池,一个在堆中
s2 = s2.intern();
System.out.println(s1 == s2); // 1.6 true;1.7+ false
注意:intern()方法存入常量池的内容,jdk1.6 存字符串值,jdk1.7+存的是堆中对象的引用地址。
这题目。。属于是给出题人自己增加记忆量。应试教育的影响,传递多少代人啊- 字符串对象创建
下面的代码将创建几个字符串对象
String s1 = new String("Hello");
String s2 = new String("Hello");
答案是3个对象。
第一,行1 字符串池中的“hello”对象。
第二,行1,在堆内存中带有值“hello”的新字符串 s1。
第三,行2,在堆内存中带有“hello”的新字符串 s2。这里“hello”字符串池中的字符串被重用。下面这句话在内存中创建了几个对象?
String s1 = new String(“abc”);
两个。
“abc”在方法区/元空间的常量池。
new创建的对象s1,在堆内存。Enum 枚举
public enum PayChannel {
ALIPAY(1, "微信支付"),
WECAHT(2, "支付宝"),
CHINAUNION(3, "银联支付"),
CREDITCARD(4, "信用卡支付");
// 字段定义只能放到上述常量后面
int chCode;
String chName;
// 有定义字段时,构造函数必须写
PayChannel(int chCode, String chName) {
this.chCode = chCode;
this.chName = chName;
}
}枚举的格式特点
枚举类默认有final修饰符,不能被继承。
枚举类默认继承了枚举类型:java.lang.Enum。
枚举类的第一行罗列的是枚举类的对象,并且是静态常量对象。
枚举类的构造器默认是私有的。
枚举类相当于是多例设计模式。
枚举类主要用于信息标志和信息分类。
比如,用户资金交易涉及到的支付通道(通道名称简称、通道编号)。
枚举考查要点
- 枚举允许继承类吗?
- 枚举允许实现接口吗?
- 枚举可以用等号比较吗?
- 可以继承枚举吗?
- 枚举可以实现单例模式吗?
- 当使用compareTo()比较枚举时,比较的是什么?
- 当使用equals()比较枚举的时候,比较的是什么?
枚举不允许继承类。Jvm在生成枚举时已经继承了Enum类,由于Java语言是单继承,不支持再继承额外的类(唯一的继承名额被Jvm用了)。
枚举允许实现接口。因为枚举本身就是一个类,类是可以实现多个接口的。
枚举可以用等号比较。Jvm会为每个枚举实例对应生成一个类对象,这个类对象是用public static final修饰的,在static代码块中初始化,是一个单例。
不可以继承枚举。因为Jvm在生成枚举类时,将它声明为final。
枚举本身就是一种对单例设计模式友好的形式,它是实现单例模式的一种很好的方式。
枚举类型的compareTo()方法比较的是枚举类对象的ordinal的值。
枚举类型的equals()方法比较的是枚举类对象的内存地址,作用与等号等价。
日期操作及格式化
JDK1.7 日期格式化(工具类)
JDK1.8 之前的日期API操作较为繁琐,不太好用。
SimpleDateFormat 日期格式化存在多线程安全问题。
public class TestDateTime {
public static void main(String[] args) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// 创建线程池
ExecutorService threadPool = new ThreadPoolExecutor(5,20,5, TimeUnit.MINUTES,
new LinkedBlockingQueue<>(15), Executors.defaultThreadFactory(), new ThreadPoolExecutor.DiscardOldestPolicy());
// 创建带返回值的任务
Callable<Date> task = new Callable<Date>() {
@Override
public Date call() throws Exception {
return sdf.parse("2020-12-03"); // 如果是sdf.format(new Date()),操作String类型,不报错
}
};
// 创建接收结果集合
List<Future<Date>> results = new ArrayList<>();
// 提交任务到线程池
for (int i = 0; i < 5; i++) {
results.add(threadPool.submit(task));
}
// 获取执行结果
for (Future<Date> rt : results) {
try {
System.out.println(rt.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 结束线程池,否则程序不会结束
threadPool.shutdown(); // 等待所有任务执行完成后,再停止线程池
}
}
执行报错:
Files\Java\jdk1.8.0_251\jre\lib\rt.jar;E:\IDEA_WK\JUC\out\production\JUC" com.vegetables.date.TestDateTime
java.util.concurrent.ExecutionException: java.lang.NumberFormatException: multiple points
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.vegetables.date.TestDateTime.main(TestDateTime.java:37)
Caused by: java.lang.NumberFormatException: multiple points
多线程环境处理方案:
1.使用ThreadLocal创建每个线程独享的SimpleDateFormat方法。
2.SimpleDateFormat格式化方法加锁同步。JDK1.8 新日期 API
JDK1.8 新日期API更加标准规范,使用更简便。
日期类是不可变的,不存在多线程安全问题。
public class TestDateTime {
public static void main(String[] args) {
//SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// JDK1.8日期格式化
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd");
// 创建线程池
ExecutorService threadPool = new ThreadPoolExecutor(5,20,5, TimeUnit.MINUTES,
new LinkedBlockingQueue<>(15), Executors.defaultThreadFactory(), new ThreadPoolExecutor.DiscardOldestPolicy());
// 创建带返回值的任务
Callable<LocalDate> task = new Callable<LocalDate>() {
@Override
public LocalDate call() throws Exception {
//return sdf.parse("2020-12-03");
return LocalDate.parse("2020-12-03", dtf);
}
};
// 创建接收结果集合
List<Future<LocalDate>> results = new ArrayList<>();
// 提交任务到线程池
for (int i = 0; i < 5; i++) {
results.add(threadPool.submit(task));
}
// 获取执行结果
for (Future<LocalDate> rt : results) {
try {
System.out.println(rt.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 结束线程池,否则程序不会结束
threadPool.shutdown(); // 等待所有任务执行完成后,再停止线程池
}
}面向对象(类与对象)
UML 类图
(截图来自《大话设计模式》)
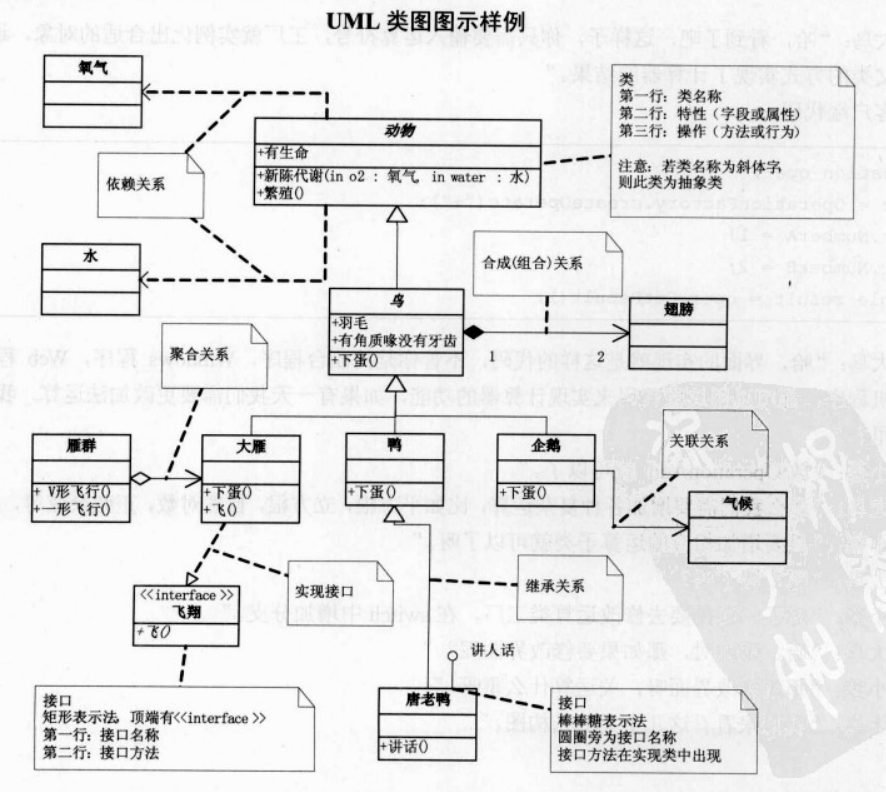

类图工具 PlantUML,更多语法及使用请参考: http://plantuml.com/ 。
关系符号
| 符号 | 关系 |
|---|---|
| ------> | 依赖(使用) 类的成员属性 方法返回类型 方法参数类型 方法中使用到 |
| —— | 关联 单向一对一(人对应身份证) 双向一对一(人与身份证双向对应) 一对多 多对一 多对多 |
| ——▷ | 泛化(继承) |
| ------▷ | 实现 |
| ◇—— | 聚合 整体与部分可以分开 电脑与鼠标、键盘、显示器等 |
| ◆—— | 组合(实心的,固实了,不可分开) 整体与部分不可以分开 鸟与翅膀 |
Java 面向对象三大特征
封装、继承、多态
封装
封装的概念,简单理解就是“隐藏对象的信息,提供外部访问操作的接口”。
就像黑盒模型,设备零件模块,能通过提供的外部接口进行访问和操作,但不能直接修改内部信息。
继承
继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。当然,如果在父类中拥有私有属性(private修饰),则子类是不能被继承的。
父类的方法子类也需要用,为避免子类重新写一套,直接继承过来就可以用了。
“马云的千万亿资产,他的子女肯定是要继承的吧”,“父亲的老婆(情人),这些私有的属性,子类是不能继承的”。
多态
多态的概念
同一个类型的对象,执行同一个行为,在不同的状态下会表现出不同的行为特征。
多态的识别技巧
对于方法的调用:编译看左边,运行看右边
对于变量的调用:编译看左边,运行看左边
原因理解:方法存在重写的概念,而变量不存在重写。跟继承类似,“用父亲的钱(变量),但饭(方法)还是自己吃。”
多态的使用前提
必须存在继承或实现关系
必须存在父类类型的变量引用子类类型的对象
需要存在方法重写
多态的优势
在多态形式下,右边的对象可以实现组件化切换,便于扩展和维护。可以实现类与类之间的解耦。
在实际开发过程中,父类类型作为方法的形式参数,传递子类对象给方法。简单理解,方法参数给出最大范围(比如动物),那方法入参对象则可以是所有动物的子类对象。
多态的劣势
多态形式下,不能直接调用子类特有的方法。编译看左边,左边父类没有子类特有的功能方法,在编译阶段会报错。
多态类型转换
// 多态的引用,就是向上转型
Animals dog = new Dog();
dog.eat();
Animals cat = new Cat();
cat.eat();
// 如果要调用父类中没有的方法,则要向下转型
Dog dogDown = (Dog)dog;
dogDown.watchDoor();
// 如果向下转换类型错误,编译不报错,运行时才会报ClassCastException类型转换异常的错误
Cat catDown = (Cat)dog; // 编译不报错,运行ClassCastException
Java建议在进行类型强转之前,先判断变量的真实类型。
变量 instanceof 类型:判断前面的变量是否为后面的类型或子类类型

Java 修饰符访问权限
| 修饰符 | 当前类 | 同包 | 子类 | 其他包 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default/friendly | √ | √ | × | × |
| private | √ | × | × | × |
引用传递和值传递
《Java程序员面试笔试宝典》中的解答

Java 本质上只有值传递
如果是对基本数据类型的数据进行操作,由于原始内容和副本都是存储实际值,并且是在不同的栈区,因此形参的操作,不影响原始内容。
如果是对引用类型的数据进行操作,分两种情况,一种是形参和实参保持指向同一个对象地址,则形参的操作,会影响实参指向的对象的内容。一种是形参被改动指向新的对象地址(如重新赋值引用),则形参的操作,不会影响实参指向的对象的内容。
引用传递和值传递
这里要用实际参数和形式参数的概念来帮助理解,
值传递:
方法调用时,实际参数把它的值传递给对应的形式参数,函数接收的是原始值的一个copy,此时内存中存在两个相等的基本类型,即实际参数和形式参数,后面方法中的操作都是对形参这个值的修改,不影响实际参数的值。
引用传递:
也称为传地址。方法调用时,实际参数的引用(地址,而不是参数的值)被传递给方法中相对应的形式参数,函数接收的是原始值的内存地址。
在方法执行中,形参和实参内容相同,指向同一块内存地址,方法执行中对引用的操作将会影响到实际对象。
这里要特殊考虑String,以及Integer、Double等几个基本类型包装类,它们都是immutable类型,因为没有提供自身修改的函数,每次操作都是新生成一个对象,所以要特殊对待,可以认为是和基本数据类型相似,传值操作。
结合上面的分析,关于值传递和引用传递可以得出这样的结论:
值传递的时候,将实参的值,copy一份给形参,对形参的修改不会影响实参。
引用传递的时候,将实参的地址值,copy一份给形参,形参和实参指向同一个内存地址(同一个对象),所以对参数的修改会影响到实际的对象。
String、Integer、Double等immutable的类型特殊处理,可以理解为传值,最后的操作不会修改实参对象。
对象的初始化顺序
父子类初始化 -> 父子对象初始化 (类和对象,分别由父及子)
静态优先,由父及子
- 父类静态资源(代码块、属性赋值)
- 子类静态资源
- 父类非静态代码块
- 父类构造方法
- 子类非静态代码块
- 子类构造方法
实例验证:
package cn.m1yellow.base;
/**
* 对象的初始化顺序
*/
public class TestObjInit {
public static void main(String[] args) {
ClsZi zi = new ClsZi("老明", 62, 200000, "小明", 30, -20000);
zi.making();
}
}
class ClsFu {
private String name;
private int age;
protected double balance;
static {
System.out.println(">>>> ClsFu static code.");
}
{
System.out.println(">>>> ClsFu not static code.");
}
public ClsFu() {
}
public ClsFu(String name, int age, double balance) {
System.out.println(">>>> ClsFu constructor.");
this.name = name;
this.age = age;
this.balance = balance;
}
}
class ClsZi extends ClsFu {
private String name;
private int age;
protected double balance;
static {
System.out.println(">>>> ClsZi static code.");
}
{
System.out.println(">>>> ClsZi not static code.");
}
public ClsZi() {
}
public ClsZi(String name, int age, double balance, String name1, int age1, double balance1) {
super(name, age, balance);
System.out.println(">>>> ClsZi constructor.");
this.name = name1;
this.age = age1;
this.balance = balance1;
}
public void making() {
System.out.println(">>>> 身家余额:" + balance);
}
}输出结果:
>>>> ClsFu static code.
>>>> ClsZi static code.
>>>> ClsFu not static code.
>>>> ClsFu constructor.
>>>> ClsZi not static code.
>>>> ClsZi constructor.
>>>> 身家余额:-20000.0对象的 hashCode
hashCode 的作用
Set 怎样保证不重复? 通过迭代使用equals方法来判断,数据量小还可以接受,数据量大怎么解决? 引入hashcode,实际上hashcode扮演的角色就是寻址,大大减少查询匹配次数。
什么情况需要重写对象的 hashCode 和 equals 方法
自定义的对象,需要去重的场景。
HashSet 和 TreeSet 集合对象去重。
去重很耗性能,尤其是大量数据去重,逐个比较判断。
有没有高效的方案?
布隆过滤器,但是会有一点点误差。【存在肯定判断存在,不存在可能判断为存在】
其实还有比去重更耗性能的,那就是【核酸检测】,日复一日,年复一年,十几亿中筛选百十万
final 关键字
final、finally、finalize 三者区别
final是一个修饰符:
当final修饰一个变量的时候,变量变成一个常量,它不能被二次赋值。
当final修饰的变量为静态变量(即由static修饰)时,必须在声明这个变量的时候给它赋值。
当final修饰方法时,该方法不能被重写。
当final修饰类时,该类不能被继承。
final不能用于修饰构造方法。
final不能修饰抽象类,因为抽象类中会有需要子类实现的抽 象方法,(抽象类中可以有抽象方法,也可以有普通方法,当一个抽象类中没有抽象方法时,这个抽象类也就没有了它存在的必要)。
final不能修饰接口,因为接口中有需要其实现类来实现的方法。
finally:
finally只能与try/catch语句结合使用,finally语句块中的语句一定会执行,并且会在return,continue,break关键字之前执行。
finalize:
finalize是一个 GC 回调方法,属于java.lang.Object类,finalize()方法是GC(garbage collector垃圾回收)运行机制的一部分,finalize()方法是在GC清理它所从属的对象时被调用。
static 关键字
使用场景
静态变量
作为共享变量使用
减少对象的创建
保留唯一副本
静态方法
不用创建对象,直接通过类调用
静态代码块
静态代码块通常是为了对静态变量做一些初始化操作,比如单例模式、定义枚举等。
静态内部类
静态内部类可以脱离外部类对象创建实例
多线程场景下,避免内部类创建过多实例而导致内存溢出
静态导入
影响代码的可读性,一般不建议使用。
抽象类
定义
[public] abstract class ClassName {
abstract void fun();
}特点
抽象类不能被实例化,即不能创建对象,如果被实例化,编译无法通过而报错。只有抽象类的非抽象子类可以创建对象。
(理解:假设创建了抽象类对象,调用抽象方法,而抽象方法没有具体的方法体,没有意义。)
抽象类一定有而且是必须有构造器,是供子类创建对象时,初始化父类成员使用。
(理解:子类的构造器中,有默认的super(),需要访问父类构造器。)
抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
抽象类的子类必须实现抽象类中的抽象方法,除非该子类也是抽象类。
抽象类的存在意义,是为了被子类继承,抽象类体现的是模板思想。
(理解:抽象类中已实现的是模板中确定的成员,不能确定如何实现的定义成抽象方法,交给具体的子类去实现。)
抽象类中的抽象方法只是声明,不包含方法体(没有{}),不给出方法的具体实现也就是方法的具体功能。
构造方法,类方法(用 static 修饰的方法)不能声明为抽象方法。
总结:抽象类不能创建对象,可以包含抽象方法。除此之外,类有的成分,抽象类都具备。
考查要点
抽象类是否有构造器,抽象类是否可以创建对象,为什么?
抽象类作为类一定有构造器,而且抽象类必须有构造器,提供给子类创建对象时调用父类构造器使用。
抽象类有构造器,但不能new对象。
接口没有构造器,但是接口可以new。
抽象类虽然有构造器,但是不能创建对象。
反证法:假如抽象类可以创建对象
Animal a = new Animal();
a.run(); // 抽象方法不能执行,因为它没有方法体,所以抽象类不能创建对象。接口
定义
修饰符 interface 接口名称 {
// 抽象方法
// 接口中的抽象方法可以省略public abstract不写,默认会加上
// public abstract void run();
void run();
// 常量
// 接口中的常量可以省略public static final不写,默认会加上
// public static final String TEST_NAME = “测试名字”;
String TEST_NAME = “测试名字”;
// JDK1.8开始新增了三个方法
// 默认方法:就是类的实例方法,只不过必须用default修饰,默认会加public修饰。只能用接口实现类的对象来调用。
// 静态方法:直接加static修饰,默认会加public修饰。接口的静态方法只能用本接口的类名调用(官方规定),这一点跟类的静态方法可以用类的实例对象或者子类对象调用有差别,为了避免出现实现多个接口,静态方法重复不知道调哪个的情况。实现多个接口,接口中包含同名的静态方法也不会冲突报错,原因是接口的静态方法只能通过接口本身调用。
// 私有方法(JDK1.9开始):其实就是私有的实例方法,必须加private修饰。
}接口多实现注意事项
实现多个接口,接口中包含同名的静态方法也不会冲突报错,原因是接口的静态方法只能通过接口本身调用。
一个类继承了一个父类,又实现了多个接口,父类中的成员方法与接口中的默认方法重名,子类就近选择执行父类的成员方法。
一个类实现多个接口,多个接口中存在同名的方法,不会报错,实现类重写实现一次同名的方法即可。
接口没有构造器,不能创建对象。
实现接口的类或者子接口不会继承接口中的静态方法。
抽象类与接口的区别
相同点: 实例化、实现、引用
不同点: 构造器、成员(属性、方法)、代码块、修饰符。注意,JDK1.8开始接口做了较大的调整(可以有多个 default、static 方法)。
JDK 1.8 以后,接口里可以有静态方法和方法体了。
JDK 1.8 以后,接口允许包含具体实现的方法,该方法称为"默认方法",默认方法使用 default 关键字修饰。更多内容可参考 Java 8 默认方法。
JDK 1.9 以后,允许将方法定义为 private,使得某些复用的代码不会把方法暴露出去。更多内容可参考 Java 9 私有接口方法。
什么时候使用接口,什么时候使用抽象类
当功能需要积累时,用抽象类,不需要积累则用接口。
如果你想拥有一些方法,并且这些方法有默认实现,那么可以使用抽象类。
如果你想实现多继承,那么就是用接口吧,java不支持多继承,但是可以实现多个接口。
接口主要用于模块与模块之间的调用。
抽象类主要用于当做基础类使用,即基类。
抽象类:功能继承、基类(有默认实现)
接口:模块
内部类
作用
可以提供更好的封装性,内部类能private修饰,可以体现出组件的思想。
比如,汽车的内部组件有发动机等;电脑里面有 CPU、内存、硬盘等。
分类
静态内部类
成员内部类(实例内部类)
局部内部类
匿名内部类(重点)
静态内部类
有static修饰,属于外部类本身,跟外部类一起加载一次。它的特征跟外部类完全一样,只是位置在别人内部而已。(外部类=宿主,内部类=寄生)
静态内部类创建对象的格式:
外部类名称.内部类名称 对象变量名称 = new 外部类名称.内部类构造器
Outer.Inner in = Outer.new Inner();
静态内部类的反问扩展:
静态内部类是否可以直接访问外部类的静态成员?可以,外部类的静态成员只有一份,可以被共享。
静态内部类是否可以直接访问外部类的实例成员?不可以,外部类的非静态成员属于外部类的实例对象,只能外部类的对象可以访问。
成员内部类
无static修饰,属于外部内的每个对象,与对象一起加载,因此,成员内部类不能定义静态成员。但是能定义常量(static final),因为常量存放在方法区的常量池。只有一份内容,不会随对象被创建而产生多次。
成员内部类创建对象的格式:
外部类名称.内部类名称 对象变量名称 = new 外部类构造器.new 内部类构造器
Outer.Inner in = new Outer().new Inner();
成员内部类的反问扩展:
成员内部类是否可以直接访问外部类的静态成员?可以,外部类的静态成员可以被共享访问。
成员内部类是否可以直接访问外部类的实例成员?可以,成员内部类属于外部类实例对象,可以直接访问外部类对象的实例成员。
局部内部类
定义在方法中、构造器中、代码块中,for循环中的内部类,内部类不按常理乱放位置就成了局部内部类。所以,实际开发中很少使用。
局部内部类只能定义实例成员,不能定义静态成员。但可以定义常量。
匿名内部类
就是一个没有名字的局部内部类。
匿名内部类可以简化代码,实际开发中比较常见,特别是Android开发。
匿名内部类的格式:
new 类名|抽象类名|接口名(形参) {
// 方法重写
}
匿名内部类的特点:
没有名称。
一旦传入匿名内部类参数,就会立即创建一个匿名内部类的对象返回。
匿名内部类的对象类型,相当于是当前new的那个类型的子类型。(没太明白)
匿名内部类也会产生一个class文件(外部类$1.class、外部类$2.class,按出现顺序命名)。
泛型
什么是泛型
泛型就是一个标签:<数据类型>
泛型可以在编译阶段约束只能操作某种数据类型。
注意:
JDK1.7开始之后,泛型后面的申明可以不写。
ArrayList<String> userIdList = new ArrayList<>();
ArrayList<String> userIdList = new ArrayList();泛型和集合都只能支持引用数据类型,不支持基本数据类型。
泛型的好处
让代码更通用、简洁
适用于多种数据类型执行相同的代码(代码复用)
泛型在编译阶段约束了操作的数据类型,从而不会出现类型转换异常。
泛型的使用
泛型变量建议使用:E、T、K、V
泛型类
编程代码最枯燥乏味的就是引用的实例很生硬、与生活毫无关联、不好理解。教小孩子都知道先从有趣的童话故事开始。
如果选用的实例源自日常生活、游戏、玩乐等有趣的真实案例,会让人有很强的代入感,更容易理解。
没有笨学生,只是没有遇到合适的老师。除了名师能出高徒,因材施教的老师也能教出厉害的学生。
修饰符 class 类名<泛型变量> {}
public class MyArrayList<E> {}
https://www.pdai.tech/md/java/basic/java-basic-x-generic.html
// 简单泛型类
class Point<T>{ // 此处可以随便写标识符号,T是type的简称
private T var ; // var的类型由T指定,即:由外部指定
public T getVar(){ // 返回值的类型由外部决定
return var ;
}
public void setVar(T var){ // 设置的类型也由外部决定
this.var = var ;
}
}
public class GenericsDemo06{
public static void main(String args[]){
Point<String> p = new Point<String>() ; // 里面的var类型为String类型
p.setVar("it") ; // 设置字符串
System.out.println(p.getVar().length()) ; // 取得字符串的长度
}
}
// 多元泛型
class Notepad<K,V>{ // 此处指定了两个泛型类型
private K key ; // 此变量的类型由外部决定
private V value ; // 此变量的类型由外部决定
public K getKey(){
return this.key ;
}
public V getValue(){
return this.value ;
}
public void setKey(K key){
this.key = key ;
}
public void setValue(V value){
this.value = value ;
}
}
public class GenericsDemo09{
public static void main(String args[]){
Notepad<String,Integer> t = null ; // 定义两个泛型类型的对象
t = new Notepad<String,Integer>() ; // 里面的key为String,value为Integer
t.setKey("汤姆") ; // 设置第一个内容
t.setValue(20) ; // 设置第二个内容
System.out.print("姓名;" + t.getKey()) ; // 取得信息
System.out.print(",年龄;" + t.getValue()) ; // 取得信息
}
}泛型方法
修饰符 <泛型变量> 返回值类型 方法名称(形参列表) {}
public static <T> String arr2String(T[] nums) {}- 定义泛型方法语法格式

- 调用泛型方法语法格式

泛型接口
修饰符 interface 接口名<泛型变量> {}
public interface Data<E> {
void add(E e);
void delete(E e);
void update(E e);
void query(int id);
}泛型通配符
例子:
Bmw、Benz继承了Car
ArrayList<Bmw>和ArrayList<Benz>与ArrayList<Car>没有关系,**泛型没有继承关系**。导致ArrayList<Bmw>和ArrayList<Benz>传不进形参为ArrayList<Car>的方法。通配符?
可以在使用泛型的时候,代表一切类型。
T、K、V是在定义泛型的时候使用,代表一切类型。
泛型的上下限
? extends Car 表示?必须是Car或者其子类。?最高能到Car。(泛型的上限)
? super Car 表示?必须是Car或者其父类。?最低必须是Car。(泛型的下限)
? extends Car
car
/ \
BENZI BMW
? super Car
object
|
vehicle
|
car// 使用原则《Effictive Java》
// 为了获得最大限度的灵活性,要在表示 生产者或者消费者 的输入参数上使用通配符,使用的规则就是:生产者有上限、消费者有下限
- 如果参数化类型表示一个 T 的生产者,使用 < ? extends T>;
- 如果它表示一个 T 的消费者,就使用 < ? super T>;
- 如果既是生产又是消费,那使用通配符就没什么意义了,因为你需要的是精确的参数类型。
类型擦除
可能新手不太清楚,Java 的泛型是伪泛型,这是因为Java在编译期间,所有的泛型信息都会被擦掉,正确理解泛型概念的首要前提是理解类型擦除。Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。
如在代码中定义List<Object>和List<String>等类型,在编译后都会变成List,JVM看到的只是List,而由泛型附加的类型信息对JVM是看不到的。Java编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法在运行时刻出现的类型转换异常的情况,类型擦除也是 Java 的泛型与 C++ 模板机制实现方式之间的重要区别。
因为种种原因,Java不能实现真正的泛型,只能使用类型擦除来实现伪泛型,这样虽然不会有类型膨胀问题,但是也引起来许多新问题,所以,SUN对这些问题做出了种种限制,避免我们发生各种错误。
- 先检查再编译
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("123");
list.add(123);//编译错误
}public class Test {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList();
list1.add("1"); //编译通过
list1.add(1); //编译错误
String str1 = list1.get(0); //返回类型就是String
ArrayList list2 = new ArrayList<String>();
list2.add("1"); //编译通过
list2.add(1); //编译通过
Object object = list2.get(0); //返回类型就是Object
new ArrayList<String>().add("11"); //编译通过
new ArrayList<String>().add(22); //编译错误
String str2 = new ArrayList<String>().get(0); //返回类型就是String
}
}注解
JDK1.5开始支持注解。
可以被编译器(如:编译器)读取。
个人理解:一个人身上的“标签”,比如:“老实人”、“精明”、“屌丝”、“技术宅”,等。别人可以通过一个人身上的标签,大概地了解这个人一些信息,为后续地交流合作做好准备。
反射 reflect
网上有很多人总结了反射相关知识点,自己梳理理解,然后加强运用实践即可,用进废退,学了长时间都用不到,过不了几天就忘掉了!
定义
反射 (Reflection) 是 Java 的特征之一,它允许运行中的 Java 程序获取自身的信息,并且可以操作类或对象的内部属性。
通过反射,我们可以在运行时获得程序或程序集中每一个类型的成员和成员的信息。程序中一般的对象的类型都是在编译期就确定下来的,而 Java 反射机制可以动态地创建对象并调用其属性,这样的对象的类型在编译期是未知的。所以我们可以通过反射机制直接创建对象,即使这个对象的类型在编译期是未知的。
反射的核心是 JVM 在运行时才动态加载类或调用方法/访问属性,它不需要事先(写代码的时候或编译期)知道运行对象是谁。
Java 反射主要提供以下功能:
在运行时判断任意一个对象所属的类;
在运行时构造任意一个类的对象;
在运行时判断任意一个类所具有的成员变量和方法(通过反射甚至可以调用private方法);
在运行时调用任意一个对象的方法。
重点:是运行时而不是编译时。
应用场景
很多人都认为反射在实际的 Java 开发应用中并不广泛,其实不然。当我们在使用 IDE(如Eclipse,IDEA)时,当我们输入一个对象或类并想调用它的属性或方法时,一按点号,编译器就会自动列出它的属性或方法,这里就会用到反射。
反射最重要的用途就是开发各种通用框架。很多框架(比如 Spring)都是配置化的(比如通过 XML 文件配置 Bean),为了保证框架的通用性,它们可能需要根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射,运行时动态加载需要加载的对象。
对与框架开发人员来说,反射虽小但作用非常大,它是各种容器实现的核心。而对于一般的开发者来说,不深入框架开发则用反射用的就会少一点,不过了解一下框架的底层机制有助于丰富自己的编程思想,也是很有益的。
基本使用
public class Apple {
private int price;
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
public static void main(String[] args) throws Exception{
//正常的调用
Apple apple = new Apple();
apple.setPrice(5);
System.out.println("Apple Price:" + apple.getPrice());
//使用反射调用
Class clz = Class.forName("com.test.reflect.Apple");
Method setPriceMethod = clz.getMethod("setPrice", int.class);
Constructor appleConstructor = clz.getConstructor();
Object appleObj = appleConstructor.newInstance();
setPriceMethod.invoke(appleObj, 14);
Method getPriceMethod = clz.getMethod("getPrice");
System.out.println("Apple Price:" + getPriceMethod.invoke(appleObj));
}
}获得 Class 对象
三种方法:
- 根据全限定类名:Class.forName(全限定类名)
- 根据类名:类名.class
- 根据对象:对象.getClass()
第一种,使用 Class.forName 静态方法。
当你知道该类的全路径名时,你可以使用该方法获取 Class 类对象。
Class clz = Class.forName("java.lang.String");第二种,使用 类名.class 方法。
这种方法只适合在编译前就知道操作的 Class。
Class clz = String.class;第三种,使用 对象.getClass() 方法。
String str = new String("Hello");
Class clz = str.getClass();创建实例对象
通过反射创建类对象主要有两种方式:通过 Class 对象的 newInstance() 方法、通过 Constructor 对象的 newInstance() 方法。
第一种:通过 Class 对象的 newInstance() 方法。
Class clz = Apple.class;
Apple apple = (Apple)clz.newInstance();第二种:通过 Constructor 对象的 newInstance() 方法
Class clz = Apple.class;
Constructor constructor = clz.getConstructor();
Apple apple = (Apple)constructor.newInstance();通过 Constructor 对象创建类对象可以选择特定构造方法,而通过 Class 对象则只能使用默认的无参数构造方法。
下面的代码就调用了一个有参数的构造方法进行了类对象的初始化。
Class clz = Apple.class;
Constructor constructor = clz.getConstructor(String.class, int.class);
Apple apple = (Apple)constructor.newInstance("红富士", 15);怎么选择特定的构造方法,参数个数不同,你怎么知道哪个构造方法有哪几个参数?
// 获取本类构造方法及参数,包括私有构造方法
Constructor[] cMethods = mClass.getDeclaredConstructors();
List<Constructor> cList = Arrays.asList(cMethods);
cList.forEach(c -> System.out.println(c));获取类属性、方法、构造器
通过 Class 对象的 getFields() 方法可以获取 Class 类的属性,但无法获取私有属性。
Class clz = Apple.class;
Field[] fields = clz.getFields();
for (Field field : fields) {
System.out.println(field.getName());
}输出结果是:
price
而如果使用 Class 对象的 getDeclaredFields() 方法则可以获取包括私有属性在内的所有属性:
Class clz = Apple.class;
Field[] fields = clz.getDeclaredFields();
for (Field field : fields) {
System.out.println(field.getName());
}输出结果是:
name
price
与获取类属性一样,当我们去获取类方法、类构造器时,如果要获取私有方法或私有构造器,则必须使用有 declared 关键字的方法。
// 获取本类构造方法及参数,不能获取私有构造方法
Constructor[] cMethods = mClass.getConstructors();
List<Constructor> cList = Arrays.asList(cMethods);
cList.forEach(c -> System.out.println(c));
System.out.println();
// 获取本类构造方法及参数,包括私有构造方法
Constructor[] cMethods2 = mClass.getDeclaredConstructors();
List<Constructor> cList2 = Arrays.asList(cMethods2);
cList2.forEach(c -> System.out.println(c));访问或操作类的私有变量和方法
/**
* 访问对象的私有方法
* 为简洁代码,在方法上抛出总的异常,实际开发别这样
*/
private static void getPrivateMethod() throws Exception{
//1. 获取 Class 类实例
TestClass testClass = new TestClass();
Class mClass = testClass.getClass();
//2. 获取私有方法
//第一个参数为要获取的私有方法的名称
//第二个为要获取方法的参数的类型,参数为 Class...,没有参数就是null
//方法参数也可这么写 :new Class[]{String.class , int.class}
Method privateMethod =
mClass.getDeclaredMethod("privateMethod", String.class, int.class);
//3. 开始操作方法
if (privateMethod != null) {
//获取私有方法的访问权
//只是获取访问权,并不是修改实际权限
privateMethod.setAccessible(true);
//使用 invoke 反射调用私有方法
//privateMethod 是获取到的私有方法
//testClass 要操作的对象
//后面两个参数传实参
privateMethod.invoke(testClass, "Java Reflect ", 666);
}
}
需要注意,第3步中的 setAccessible(true) 方法,是获取私有方法的访问权限,如果不加会报异常 IllegalAccessException,因为当前方法访问权限是private的,如下:
java.lang.IllegalAccessException: Class MainClass can not access a member of class obj.TestClass with modifiers "private"
正常运行后,打印如下,调用私有方法成功:
Java Reflect 666修改私有变量
/**
* 修改对象私有变量的值
* 为简洁代码,在方法上抛出总的异常
*/
private static void modifyPrivateFiled() throws Exception {
//1. 获取 Class 类实例
TestClass testClass = new TestClass();
Class mClass = testClass.getClass();
//2. 获取私有变量
Field privateField = mClass.getDeclaredField("MSG");
//3. 操作私有变量
if (privateField != null) {
//获取私有变量的访问权
privateField.setAccessible(true);
//修改私有变量,并输出以测试
System.out.println("Before Modify:MSG = " + testClass.getMsg());
//调用 set(object , value) 修改变量的值
//privateField 是获取到的私有变量
//testClass 要操作的对象
//"Modified" 为要修改成的值
privateField.set(testClass, "Modified");
System.out.println("After Modify:MSG = " + testClass.getMsg());
}
}
此处代码和访问私有方法的逻辑差不多,就不再赘述,从输出信息看出 修改私有变量 成功:
Before Modify:MSG = Original
After Modify:MSG = Modified修改私有常量
常量是指使用 final 修饰符修饰的成员属性,与变量的区别就在于有无 final 关键字修饰。在说之前,先补充一个知识点。
Java 虚拟机(JVM)在编译 .java 文件得到 .class 文件时,会优化我们的代码以提升效率。其中一个优化就是:JVM 在编译阶段会把引用常量的代码替换成具体的常量值,如下所示(部分代码)。
编译前的 .java 文件:
//注意是 String 类型的值
private final String FINAL_VALUE = "hello";
if(FINAL_VALUE.equals("world")){
//do something
}
编译后得到的 .class 文件(当然,编译后是没有注释的):
private final String FINAL_VALUE = "hello";
//替换为"hello"
if("hello".equals("world")){
//do something
}
但是,并不是所有常量都会优化。经测试对于 int、long、boolean这些基本类型以及String,JVM会优化,而对于 Integer、Long、Boolean这种包装类型,或者其他诸如Date、Object类型则不会被优化。反射修改能力范围
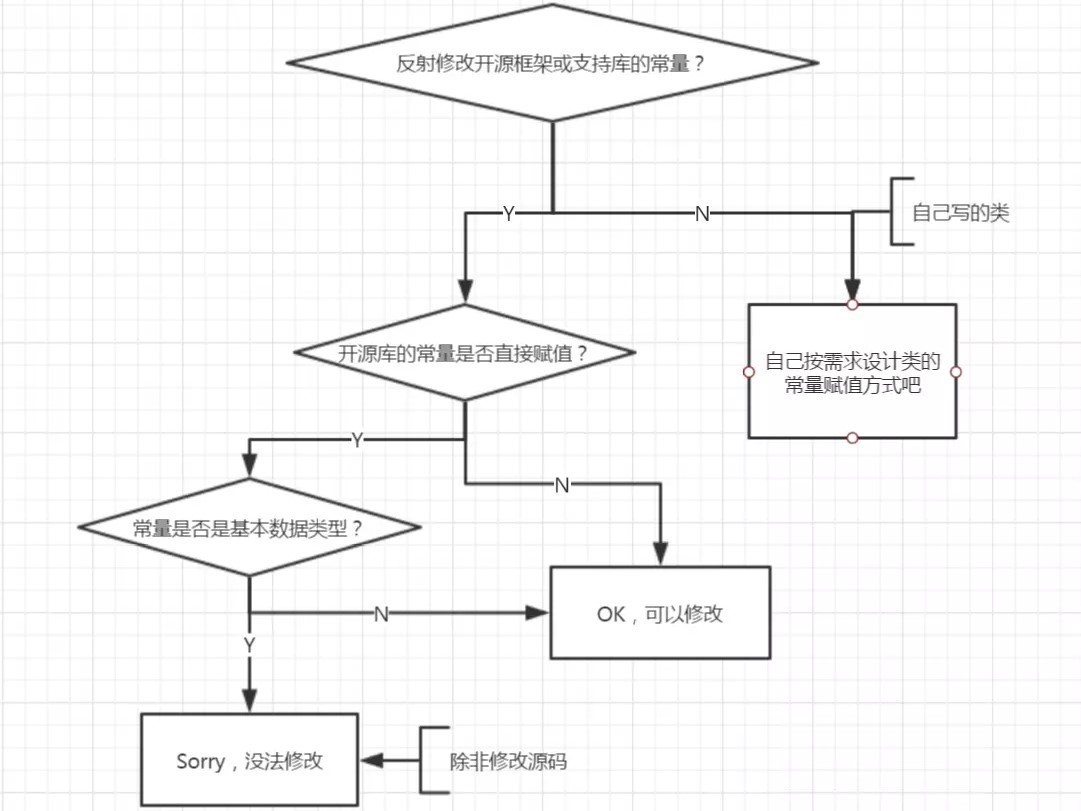
注意事项
由于反射会额外消耗一定的系统资源,因此如果不需要动态地创建一个对象,那么就不需要用反射。
另外,反射调用方法时可以忽略权限检查,因此可能会破坏封装性而导致安全问题。
克隆
为什么要克隆对象
想要使用这个对象的数据,但又不想改变原始的数据。
新建一份对象的副本,防止原对象数据内容被改变,导致后续想要用原对象数据的时候,发现原对象数据内容已被修改,就好像PS修图一样,修图第一步创建原图片的副本,是良好的习惯。
对象赋值其实是复制引用地址,采用将原对象赋给新对象,新对象的引用地址依然指向原对象,一旦新对象修改数据,原对象的数据自然也被修改了。
对象克隆方式
浅克隆:被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。
深克隆:除去那些引用其他对象的变量,被复制对象的所有变量都含有与原来的对象相同的值。那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。换言之,深复制把要复制的对象所引用的对象都复制了一遍。
如何实现对象克隆
对象的类实现 Cloneable 接口;
覆盖Object类的clone()方法(覆盖clone()方法,访问修饰符设为public,默认是protected,但是如果所有类都在同一个包下protected是可以访问的);
在clone()方法中调用super.clone()。
浅克隆
按照上述操作步骤,实现的就是浅克隆。
深克隆
方式一:clone函数的嵌套调用,即克隆对象内部的对象也要逐个实现克隆。
方式二:序列化。
方式一已经足够满足我们的需要,但是如果类之间的关系很多,对象内包含对象,嵌套层次太多,或者是有的属性是数组呢,数组可无法实现Cloneable接口(我们可以在clone方法中手动复制数组),但是每次都得手写clone方法,很麻烦,而序列化方式只需要给每个类都实现一个Serializable接口,也是标记接口,最后同序列化和反序列化操作达到克隆的目的(包括数组的复制)。
使用建议
其实现在不推荐大家用Cloneable接口,实现比较麻烦,现在借助Apache Commons或者 springframework可以直接实现:
浅克隆:
BeanUtils.cloneBean(Object obj);
BeanUtils.copyProperties(S,T);
深克隆:
SerializationUtils.clone(T object);
BeanUtils 是利用反射原理获得所有类可见的属性和方法,然后复制到target类。
SerializationUtils.clone() 就是使用我们的前面讲的序列化实现深克隆,当然你要把要克隆的类实现Serialization接口。
序列化与反序列化
序列化的含义、意义及使用场景
序列化:将对象写入到IO流中
反序列化:从IO流中恢复对象
意义:序列化机制允许将实现序列化的Java对象转换位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
使用场景:所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method invoke,即远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错;所有需要保存到磁盘的java对象都必须是可序列化的。通常建议:程序创建的每个JavaBean类都实现Serializeable接口。
序列化实现的方式
如果需要将某个对象保存到磁盘上或者通过网络传输,那么这个类应该实现Serializable接口或者Externalizable接口之一。
实现Serializable接口
Serializable接口是一个标记接口,不用实现任何方法。一旦实现了此接口,该类的对象就是可序列化的。
注意:
反序列化并不会调用构造方法。反序列的对象是由JVM自己生成的对象,不通过构造方法生成。
如果一个可序列化的类的成员不是基本类型,也不是String类型,那这个引用类型也必须是可序列化的;否则,会导致此类不能序列化。
同一对象序列化多次,会将这个对象序列化多次吗?不会,用编号代替。所有保存到磁盘的对象都有一个序列化编码号,当程序试图序列化一个对象时,会先检查此对象是否已经序列化过,只有此对象从未(在此虚拟机)被序列化过,才会将此对象序列化为字节序列输出,如果此对象已经序列化过,则直接输出编号即可。
java序列化算法潜在的问题,由于java序利化算法不会重复序列化同一个对象,只会记录已序列化对象的编号。如果序列化一个可变对象(对象内的内容可更改)后,更改了对象内容,再次序列化,并不会再次将此对象转换为字节序列,而只是保存序列化编号。(待验证,这么严重的问题,Oracle会不知道?)
可选自定义序列化。某些属性不需要序列化,可使用 transient 关键字修饰。使用transient修饰的属性,java序列化时,会忽略掉此字段,所以反序列化出的对象,被transient修饰的属性是默认值。对于引用类型,值是null;基本类型,值是0;boolean类型,值是false。
Externalizable:强制自定义序列化
通过实现Externalizable接口,必须实现writeExternal、readExternal方法。
注意:
Externalizable接口不同于Serializable接口,实现此接口必须实现接口中的两个方法实现自定义序列化,这是强制性的;特别之处是必须提供pulic的无参构造器,因为在反序列化的时候需要反射创建对象。
虽然Externalizable接口带来了一定的性能提升,但变成复杂度也提高了,所以一般通过实现Serializable接口进行序列化。
序列化版本号 serialVersionUID
java序列化提供了一个private static final long serialVersionUID 的序列化版本号,只有版本号相同,即使更改了序列化属性,对象也可以正确被反序列化回来。
如果反序列化使用的class的版本号与序列化时使用的不一致,反序列化会报InvalidClassException异常。
序列化版本号可自由指定,如果不指定,JVM会根据类信息自己计算一个版本号,这样随着class的升级,就无法正确反序列化;不指定版本号另一个明显隐患是,不利于jvm间的移植,可能class文件没有更改,但不同jvm可能计算的规则不一样,这样也会导致无法反序列化。
也就是由于类中属性字段的改动,导致序列号版本变化,历史已经序列化的对象数据将无法正确反序列化。通常解决办法是更新历史数据,比如序列化数据存在缓存中,就需要更新缓存。
什么情况下需要修改 serialVersionUID 呢?(新增或改了字段、方法的名称和修饰等属性,影响了反序列化识别)
分三种情况。
如果只是修改了方法,反序列化不受影响,则无需修改版本号;
如果只是修改了静态变量,瞬态变量(transient修饰的变量),反序列化不受影响,无需修改版本号;
如果修改了非瞬态变量,则可能导致反序列化失败。如果新类中实例变量的类型与序列化时类的类型不一致,则会反序列化失败,这时候需要更改serialVersionUID。如果只是新增了实例变量,则反序列化回来新增的是默认值;如果减少了实例变量,反序列化时会忽略掉减少的实例变量。
设置 serialVersionUID = 1L 的目的
便于分布式项目的兼容。
比如,同一个数据库实体类可能存在多个不同的服务器上,如果 serialVersionUID 不一致,会导致分布式项目不能正常交互。
private static final long serialVersionUID = 1L;serialVersionUID有两种显示的生成方式:
一个是默认的1L,比如:private static final long serialVersionUID = 1L;
一个是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,
比如:private static final long serialVersionUID = xxxxL;
变量 serialVersionUID 称为序列化版本号,这个变量多用于实现了Serializable的类中,试用场景是类的序列化。 当我们没有定义这个变量的时候,虚拟机会根据类的属性算出一个独一无二的该变量值,在序列化的时候对该变量赋值,并随类一同序列化。
反序列化的时候,虚拟机同样会先读取该变量值,然后再当前读取的类中寻找同样的变量值,如果找到,那么反序列话成功,找不到即会报异常。
使用虚拟机默认计算的serialVersionUID就会有一个明显的劣势,那就是类一旦序列化后,我们就不能修改该类了,因为计算的serialVersionUID会改变,导致后期反序列话失败。
为了避免以上情况,我们手动定义一个静态常量来人为定义serialVersionUID,因为一旦手动定义了,虚拟机就不会再进行计算了,这也就是你上面写的那就话。
总结与建议
所有需要网络传输的对象都需要实现序列化接口,通过建议所有的javaBean都实现Serializable接口。
对象的类名、实例变量(包括基本类型,数组,对其他对象的引用)都会被序列化;方法、类变量、transient实例变量都不会被序列化。
如果想让某个变量不被序列化,使用transient修饰。
序列化对象的引用类型成员变量,也必须是可序列化的,否则,会报错。
反序列化时必须有序列化对象的class文件。
当通过文件、网络来读取序列化后的对象时,必须按照实际写入的顺序读取。
单例类序列化,需要重写readResolve()方法;否则会破坏单例原则。
同一对象序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化编号,不会重复序列化。
建议所有可序列化的类加上serialVersionUID 版本号,方便项目升级。
Comparable 与 Comparator
Comparable是排序接口;若一个类实现了Comparable接口,现实 compareTo 方法,就意味着该类对象支持排序。
而Comparator是比较器;我们若需要控制某个类的次序,可以建立一个该类对象的比较器来进行排序。
Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”。
考查要点
public 类名必需与文件名一致
public class 后面的类名必需与文件名一致,一个文件中可以有多个类(class),但是只能有一个公共类(public class)。
能否重载 main() 方法
可以。一个Java类可以有任意数量的main()方法。
为了运行java类,类的main()方法应该有例如“public static void main(String[] args)”的声明。如果你对此声明做任何修改,编译也是可以成功的。但是,运行不了Java程序。你会得到运行时错误,因为找不到main方法。修改main方法的访问修饰符也会报运行时错误,也就是说 JVM 只认可 public static void main(String[] args) 声明的 mian() 方法。
简单说说你了解的 Java 类加载器,是否实现过类加载器
详细内容在 JVM 文档。
集合(容器)
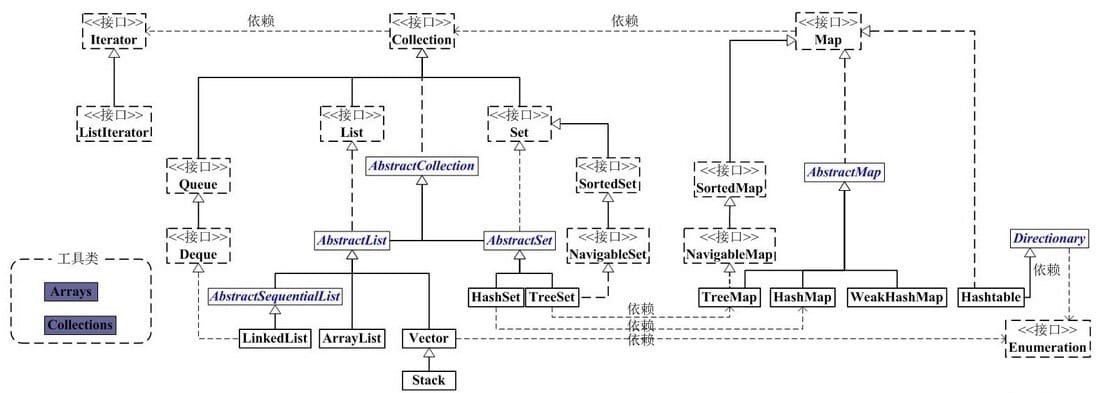
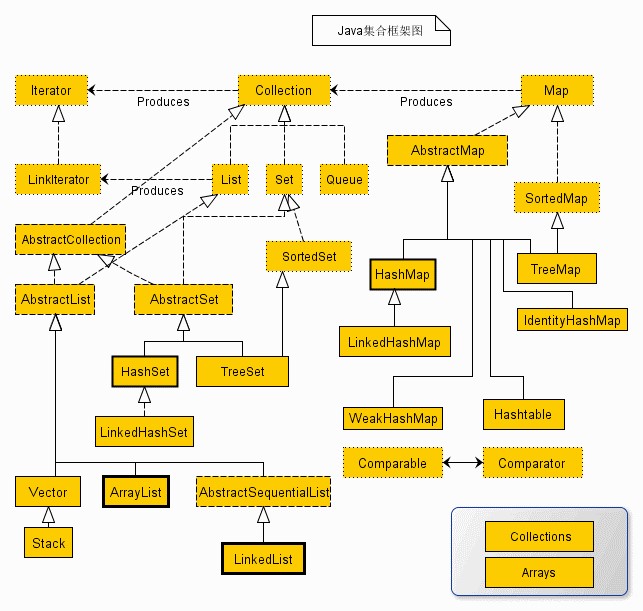
在《Java编程思想》第四版中,对Java集合框架结构的描述:

集合思维导图
.png)
Collection
List
ArrayList
默认构造的是空数组
/**
* 默认构造方法,初始为空数组。
* 只有插入一条数据后才会扩展为10,而实际默认是空的,可以节省一定的内存开销
*/
public ArrayList() {
// private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}自定义List容量
/**
* 数组最大分配容量大小
* 为什么是 Integer.MAX_VALUE - 8 (问这个问题的面试可能对你印象不好,专门问各种奇怪偏门细节内容,直接回答具体的细节工作用得少,记不清了就行)
* 一次性分配过大的容量,数组大小超出虚拟机限制,会导致内存溢出 OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}每一次看到这些源码概念就犯困!一看就想睡觉,全是为了应付面试,工作只要依葫芦画瓢照着用就行,过几个月不看,基本上全忘掉!
理论概念驱不动,兴趣成果驱动,前提饭碗得保住,再加以实战和成果反馈!
理论概念、细节内容整理真的让人犯困啊,实际成果驱动才最有效果,并且兴趣越来越浓厚,而理论概念几乎驱不动,强迫学习记忆,学了不用,或者以后工作和生活根本用不到,最后所有学科的理论知识全部忘得一干二净!你现在还记得多少高中大学的知识内容?(这可能是应试教育最大的问题,宝贵青春时间学的知识,很大一部分人毕业后基本用不到,上个大学就为了一个文凭)
扩容机制
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// oldCapacity为旧数组的容量
int oldCapacity = elementData.length;
// newCapacity为新数组的容量(oldCap+oldCap/2:即更新为旧容量的1.5倍)
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 检查新容量的大小是否小于最小需要容量,如果小于那旧将最小容量最为数组的新容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果新容量大于MAX_ARRAY_SIZE,使用hugeCapacity比较二者
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// 将原数组中的元素拷贝
elementData = Arrays.copyOf(elementData, newCapacity);
}Iterator迭代器遍历
List<String> list = new ArrayList<>();
list.add("A");
list.add("D");
list.add("E");
list.add("K1"); // list.remove(v) 单独移除 K1 竟然没有报并发修改异常,其他的都报了,害我看了半天源码
list.add("K2");
Iterator itrator = list.iterator();
// String v; // 如果只在循环内使用,定义在循环外,也还是会被优化到循环内部
while (itrator.hasNext()) {
// String v 在同一个方法中,无论写在哪,如果只有循环内这一处调用,就会被编译器优化到循环内部,整个main方法栈只有一个 v 局部变量,不会重复生成局部变量
String v = (String) itrator.next();
if (v.equals("K2")) {
itrator.remove(); // 一次迭代只能移除一个元素
}
}
System.out.println(list);Vector
LinkedList
List 考查要点
- ArrayList 添加大量元素(比如上万个)的场景,有用过手动扩容吗?
为什么需要手动扩容?试想一下,如果用户已经知道即将存入大量的元素,比如目前有20个元素,即将存入20000个。那这个时候使用自动扩容就会扩容多次。而手动扩容可以一次性扩容到20000,可以提高性能。
可以通过调用以下方法实现手动扩容:
public void ensureCapacity(int minCapacity) {
if (minCapacity > elementData.length
&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
&& minCapacity <= DEFAULT_CAPACITY)) {
modCount++;
grow(minCapacity);
}
}- ArrayList 有缩容吗?
ArrayList没有缩容。无论是remove方法还是clear方法,它们都不会改变现有数组elementData的长度。但是它们都会把相应位置的元素设置为null,以便垃圾收集器回收掉不使用的元素,节省内存。- List 如何一边遍历,一边删除?
https://blog.csdn.net/zwwhnly/article/details/104987143
新手常犯的错误
可能很多新手(包括当年的我,哈哈)第一时间想到的写法是下面这样的:
List<String> list = new ArrayList<>();
list.add("A");
list.add("D");
list.add("E");
list.add("K1"); // list.remove(v) 单独移除 K1 竟然没有报并发修改异常,其他的都报了,害我跟了半天源码
list.add("K2");
for (String v : list) {
if (v.equals("K1")) {
list.remove(v);
}
}
System.out.println(list);
然后满怀信心的去运行,结果竟然抛java.util.ConcurrentModificationException异常了,翻译成中文就是:并发修改异常。
既然不能使用foreach来实现,那么我们该如何实现呢?
主要有以下3种方法:
使用Iterator的remove()方法(不适用一次迭代remove多个的情况,一次只迭代一个元素)
使用jdk1.8 集合的removeIf()方法(推荐,底层也是用的Iterator的remove()方法)
使用for循环正序遍历(维护下标索引值)
使用for循环倒序遍历(不用维护下标)
Iterator itrator = list.iterator();
// String v; // 如果只在循环内使用,定义在循环外,也还是会被优化到循环内部
while (itrator.hasNext()) {
// String v 在同一个方法中,无论写在哪,如果只有循环内这一处调用,就会被编译器优化到循环内部,整个main方法栈只有一个 v 局部变量,不会重复生成局部变量
String v = (String) itrator.next();
if (v.equals("K2")) {
itrator.remove();
}
}
System.out.println(list);
list.removeIf(v -> v.equals("K2")); // removeIf 函数式接口
System.out.println(list);- 对象排序
list 存储元素类实现 comparable 接口,并且重写 compareTo 方法,调用 Collections.sort(list)。
//普通写法,默认升序
List<Integer> list = Arrays.asList(26, 65, 13, 79, 6, 123);
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1, o2);
}
});
System.out.println(list.toString());
//Lambda表达式写法。有参有返回,“类型推断”
list.sort((o1, o2) -> Integer.compare(o1, o2));
System.out.println(list.toString());- List 集合底层排序算法
Arrays.sort() 方法会根据不同的情况使用不同的"排序算法"。
对于基本数据类型排序
具体排序算法取决于元素个数
< 47 插入排序
> 47 且 < 286 快排
> 286 归并排序
对于对象列表排序
调用带选择器的 Collections.sort()方法,可能会执行两种算法 归并排序、TimSort,
但由于 LegacyMergeSort.userRequested 默认为 false,所以最终会执行 TimSort 排序算法。
jdk 提供的排序工具类主要有两个:
java.util.Arrays
java.util.Collections可能更常用
Collections.sort() + 重写 compare 方法
的方式来基于某个属性排序
不过翻看 Collections.sort()源码会发现,
最终也是调用 Arrays.sort()方法进行排序:
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}Set
HashSet
TreeSet
基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
TreeSet排序方式
有值特性的元素可以直接进行升序排序(整型、浮点型、字符型)。
字符串类型的元素会按照首字符的编码值排序。
对于自定义的引用数据类型,TreeSet无法排序,执行时报错,因为不知道排序规则。
对于自定义的引用数据类型进行排序,需要自定义排序规则:
直接为对象的类实现比较规则接口Comparable,重写compareTo比较方法(拓展方式)。(比较者大于被比较者返回正数;比较者小于被比较者返回负数;两者相等返回0)
直接为集合设置比较器Comparator对象,重写比较方法。
注意,如果实现了类和集合两种比较方式,优先使用集合自带的比较规则,即使用设置比较器Comparator对象的规则。
LinkedHashSet
Set 考查要点
- Set 集合添加的元素是不重复的,是如何去重复的?(怎样去重复)
对于有值特性的元素(String、Integer、Long、Double、Float、Char),Set集合可以直接判断进行去重复。
对于引用数据类型的类对象,Set集合去重复分两步判断:(先地址,再内容)
Set集合会让两两对象,先调用自己的hashCode()方法得到彼此的哈希值(所谓的内存地址),比较两个对象的哈希值是否相同,如果不相同则直接认为两个对象不重复;
如果两对象的哈希值相同,会继续让两个对象调用equals()比较内容是否相同,如果内容相同则认为是重复了,内容不相同则认为不重复。
实际开发中,通常两对象内容相同,就希望集合认为它们重复了,这时候必须重写hashCode()和equals()方法。只要两个对象的内容一样,则两个对象的哈希值也要一样。- Set 集合无序的原因是什么?(为什么会是无序的)
Set集合无序的根本原因是因为底层采用了哈希表存储元素。
JDK1.8之前:哈希表=数组+链表+(哈希算法)
JDK1.8开始:哈希表=数组+链表+红黑树+(哈希算法)Queue
在两端出入的List,可以用数组或链表来实现。
Queue 考查要点
Collection 集合遍历
for 循环
for (int i = 0; i <= list.size() - 1; i++) {
}foreach(增强for循环)
for (String str : list) {}迭代器 Iterator
迭代器是一种模式,详细可见其设计模式,可以使得序列类型的数据结构的遍历行为与被遍历的对象分离,即我们无需关心该序列的底层结构是什么样子的。只要拿到这个对象,使用迭代器就可以遍历这个对象的内部。
Iterable:实现这个接口的集合对象支持迭代,是可以迭代的。实现了这个可以配合foreach使用。
Iterator:迭代器,提供迭代机制的对象,Iterator接口有定义迭代操作规范。
Iterator<String> ite = list.iterator();
while(ite.hasNext()) { // 判断下一个元素之后有值
System.out.println(ite.next());
}快速失败机制(fail—fast)就是在使用迭代器遍历一个集合对象时,如果遍历过程中对集合进行修改(增删改),则会抛出 ConcurrentModificationException 异常。
JDK1.8开始之后的 Lambda表达式
ArrayList<Person> array = new ArrayList<Person>();
Person p1 = new Person("Tom1");
Person p2 = new Person("Tom2");
Person p3 = new Person("Tom3");
array.add(p1);
array.add(p2);
array.add(p3);
array.forEach(obj -> System.out.println(obj.getName()));
lists.foreach(s -> {
System.out.println(s);
});
lists.foreach(s -> System.out.println(s));
lists.foreach(System.out::println);使用for循环还是迭代器Iterator对比:
采用ArrayList对随机访问比较快,而for循环中的get()方法,采用的即是随机访问的方法,因此在ArrayList里,for循环较快。
采用LinkedList则是顺序访问比较快,iterator中的next()方法,采用的即是顺序访问的方法,因此在LinkedList里,使用iterator较快。
从数据结构角度分析,for 循环适合访问顺序结构,可以根据下标快速获取指定元素。而 Iterator 适合访问链式结构,因为迭代器是通过 next() 和 Pre() 来定位的。可以访问没有顺序的集合。
而使用 Iterator 的好处在于可以使用相同方式去遍历集合中元素,而不用考虑集合类的内部实现(只要它实现了 java.lang.Iterable 接口),如果使用 Iterator 来遍历集合中元素,一旦不再使用 List 转而使用 Set 来组织数据,那遍历元素的代码不用做任何修改,如果使用 for 来遍历,那所有遍历此集合的算法都得做相应调整,因为List有序,Set无序,结构不同,他们的访问算法也不一样。
Map
HashMap
JDK1.7 HashMap
经典的哈希表实现:数组+链表
重要知识点
初始容量:1 << 4 = 1*2^4 = 16
负载因子:0.75(3/4) 为什么是0.75?在时间和空间复杂度上达到一个较好的折中,均衡性能和空间利用率。
哈希算法
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
// 取key的hashCode值、高位运算、取模运算
// 在JDK1.8的实现中,优化了高位运算的算法,
// 通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),
// 主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}初始化:延迟初始化,put的时候判断数组是否为空,为空才初始化。
扩容:元素超过初始容量负载因子,即16*0.75=12,就开始进行resize扩容,扩容长度为2*table.lenght,即扩容一倍。resize扩容是将当前哈希表中的元素全部重新计算哈希值(rehash),存放到新的哈希表中。效率低,线程不安全。
缩容:不会缩容。
JDK1.7 HashMap容易出现问题的点
非常容易碰到死锁。多线程同时修改HashMap,容易出现循环链表的情况。
存在安全隐患(CVE-2011-4858),参考Tomcat邮件组的讨论。hash碰撞,导致哈希表中的某一个桶下的元素特别多,形成长度过大的链表,可以通过精心构造的恶意请求引发DoS攻击,Tomcat对请求参数进行了限制。
JDK1.8 HashMap
JDK1.8 HashMap的改进:
哈希表实现:数组+链表/红黑树,链表元素达到阈值(>= 8)的时候,转换为红黑树,避免链表过长,提升性能,解决了JDK1.7的安全隐患。当红黑树元素为6的时候,会退化为链表,如果链表的元素在6~8之间徘徊,就会频繁的发生链表转树、树转链表,导致效率很低,这是比较极端的情况。
- 当链表的长度>=8且数组长度>=64时,会把链表转化成红黑树。
- 当链表长度>=8,当数组长度<64时,会优先进行扩容,而不是转化成红黑树。
- 当红黑树节点数<=6,自动转化成链表。
为什么需要数组长度到64才会转化红黑树?当数组长度较短时,如16,链表长度达到8已经是占用了最大限度的50%,意味着负载已经快要达到上限,此时如果转化成红黑树,之后的扩容又会再一次把红黑树拆分平均到新的数组中,这样非但没有带来性能的好处,反而会降低性能。所以在数组长度低于64时,优先进行扩容。
为什么要大于等于8转化为红黑树,而不是7或9?树节点的比普通节点更大,在链表较短时红黑树并未能明显体现性能优势,反而会浪费空间,在链表较短是采用链表而不是红黑树。在理论数学计算中(装载因子=0.75),链表的长度到达8的概率是百万分之一;把7作为分水岭,大于7转化为红黑树,小于7转化为链表。红黑树的出现是为了在某些极端的情况下,抗住大量的hash冲突,正常情况下使用链表是更加合适的。
扩容时插入顺序的改进:防止多线程resize出现循环链表导致死锁。
函数方法
forEach
compute系列
新API
merge
replace
HashTable
TreeMap
Map 遍历
public class Test{
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
该方法比 entrySet 遍历在性能上稍好,而且代码更加干净。
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
这种方式看起来冗余却有其优点所在,可以在遍历时调用 iterator.remove() 来删除 entries,另两个方法则不能。
从性能方面看,该方法类同于 for-each (Map.keySet)遍历的性能。
//第三种:推荐,尤其是容量大时【大大小小 entrySet】
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) { // 先拿到 entry 再遍历获取 K V
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
注意:如果遍历一个空 map 对象,for-each 循环将抛出 NullPointerException,因此在遍历前应该检查是否为空引用。
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
}
如果仅需要键(keys)或值(values),则keySet或values遍历;
如果需要在遍历时删除 entries,则iterator遍历;
如果键值都需要,则使用entrySet遍历。Map 考查要点
- HashMap默认容量,如何扩容?
默认容量为1 << 4 = 1*2^4 = 16
元素超过初始容量*负载因子,即16*0.75=12,就开始进行resize扩容,扩容长度为2*table.lenght,即扩容一倍。resize扩容是将当前哈希表中的元素全部重新计算哈希值(rehash),存放到新的哈希表中。- HashMap中的数组大小为什么一定要是2的幂?
HashMap初始化的时候,会调用roundUpToPowerOf2()方法,将指定的初始化容量值向上转换为2的幂次方整数,比如指定容量大小是17,向上转换为2的幂次方整数是32。
【方便以按位与的形式取余,确定下标】
定位元素具体存放位置indexFor()方法,计算方法:h & (length-1),只有当容量长度为2^n,length-1才能得到后面位数全是1的情况,这样跟哈希值进行按位与,能非常快速地拿到数组下标,并且确保元素分布还是均匀的。- HashMap为什么是线程不安全的?
HashMap设计本身就是线程不安全的,如果需要在多线程环境下使用,需要自己添加线程同步方法,或者使用线程安全的Map集合ConcurrentHashMap。- HashMap线程不安全可能导致的问题
1) 多线程put的时候可能会导致元素丢失,因为在addEntry的方法中,如果两个线程同时取得了当前元素,然后赋值的给到当前元素的时候会有一个成功,另一个则数据丢失。
2) 造成resize死循环,因为hashmap的初始容量是16,当有数据插入时 ,检查容量有没有超过大小,超过了就会增大hash的尺寸,就会进行rehash,多线程环境下造成环形链表。- HashMap从JDK1.7到JDK1.8做了哪些改进,为什么?
- HashMap的自定义初始化长度方法有使用过吗?什么场景使用?为什么使用?
resize扩容效率较低,在知道元素数量的情况下,指定初始化长度,能减少resize扩容的次数,提升性能。- HashMap在resize扩容时transfer()方法引发的线程安全问题
参考:https://coolshell.cn/articles/9606.html- JDK 8 HashMap 为什么是先插入再扩容(JDK 7 是先扩容再插入)
jdk8中hashmap为什么先插入再扩容? - 知乎用户的回答 - 知乎
https://www.zhihu.com/question/360072840/answer/1470337315
首先梳理一下jdk7和8在put方法执行流程的区别,jdk7使用头插法,也没有节点数量超过8变为红黑树,jdk8在rehash过程中计算扩容过后结点位置也做了优化。
无论是jdk7还是8,在put的时候,都会先算出key的哈希值,得到数组的位置,然后遍历这个索引上的无论是链表还是红黑树。如果在遍历过程中找到了equals的key,直接修改一下value就返回了,不涉及扩容。
如果上面遍历的过程没找到,而且容量要超过了,才涉及到扩容。
jdk7先扩容,然后使用头插法,直接把要插入的Entry插入到扩容后数组中,头插法不需要遍历扩容后的数组或者链表。而jdk8如果要先扩容,由于是尾插法,扩容之后还要再遍历一遍,找到尾部的位置,然后插入到尾部。(也没怎么节约性能)
感觉jdk8可能浪费性能的地方,在Node插入之后,如果当前数组位置上节点数量达到了8,先树化,然后再计算需不需要扩容,前面的树化可能被浪费了。【链表长度达到8,且数组长度达到64,才会转红黑树,否则是先扩容】- hash冲突你还知道哪些解决方案?
开放定址法
链地址法
再哈希法
公共溢出区域法- Hashmap用过吧?你先说说散列表的三大问题与线程安全
HashMap本质上是一个散列表,那么就离不开散列表的三大问题: 散列函数、哈希冲突、扩容方案 ;同时作为一个数据结构,必须考虑多线程并发访问的问题,也就是 线程安全 。这四大重点则为学习HashMap的重点,也是HashMap设计的重点。
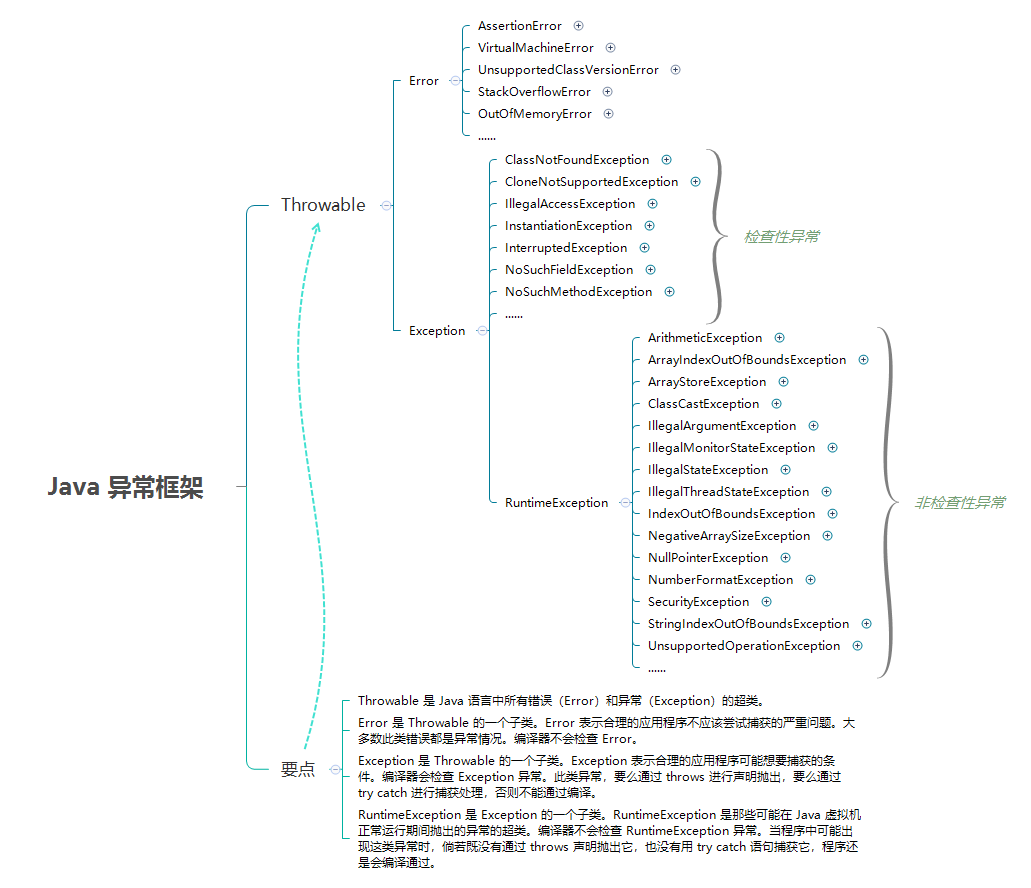
异常
异常类型
断言
什么是断言
断言是使用Java中的 assert 语句实现的。 在执行断言时,它被认为是正确的。 如果失败,JVM会抛出一个名为 AssertionError 的错误。 它主要用于开发过程中的测试目的。
assert 语句与布尔表达式一起使用,可以用两种不同的方式编写:
assert expression;
assert expression : errorMessage;
public class AssertTest {
public static void main(String[] args) {
int value = 15;
assert value >= 20 : "Underweight";
System.out.println("value is " + value);
}
}
输出:
value is 15
可以看到 assert 语句并没有起作用,这是因为Java在执行程序的时候默认是不启动断言检查的,即所有的断言语句都将被忽略。
如果要开启断言检查,则需要使用 -enableassertions 或 -ea JVM参数来开启;如果要手动忽略断言检查,则可以通过使用 -disableassertions 或 -da JVM参数来忽略断言语句。
执行命令 java -ea AssertTest 开启断言后的输出:
Exception in thread "main" java.lang.AssertionError: Underweight
at AssertTest.main(AssertTest.java:11)
使用第一种无错误信息提示的语法编写:
public class AssertTest {
public static void main(String[] args) {
int value = 15;
assert value >= 20;
System.out.println("value is " + value);
}
}
输出:
Exception in thread "main" java.lang.AssertionError
at AssertTest.main(AssertTest.java:11)
可以看到这里仅是抛出了 AssertionError,没有任何错误信息提示。为什么使用断言
确保看起来无法到达的代码实际上是无法到达的
确保假设是正确的
确保 switch case 语句的 default 分支无法到达
检查对象的状态
在方法的开始检验
在方法调用后检验
注意事项
断言主要用于检查逻辑上不可能的情况。例如,它们可用于检查代码在开始运行之前期望的状态或在代码结束运行之后的状态。与普通的异常/错误处理不同,断言通常在运行时被禁用。
在哪里使用断言
私有方法的参数。私有参数仅由开发人员的代码提供,开发人员可能希望检查其关于参数的假设
分支条件,例如 switch case 语句
方法开头的条件
哪里不使用断言
断言不应用于替换错误/异常消息
断言不应用于 public 方法中的参数,因为它们可能由用户提供
断言不应在命令行参数上使用
小结
断言是一种调试方式,断言失败会抛出 AssertionError,只能在开发和测试阶段启用断言
对可恢复的错误不能使用断言,而应该抛出异常
JAVA中断言很少被使用,更好的方法是编写单元测试
日志
Lambda 表达式
网上资料很多了,没必要自己照搬照抄一遍,最多记录一些重点就可以了,关键在于练习实战!
概念及作用
Lambda表达式本质上是一个匿名函数(方法),它没有方法名,没有权限修饰符,没有返回值声明。它看起来就是一个箭头->从左边指向右边。我们可以把Lambda表达式理解为一段可以传递的代码(将代码像数据一样进行传递),它的核心思想是将面向对象中的传递数据变成传递行为。
Lambda表达式的出现就是为了简化匿名内部类,让匿名内部类在方法中作为参数的使用更加方便。所以使用Lambda表达式可以让我们的代码更少,看上去更简洁,代码更加灵活。而Lambda表达式作为一种更紧凑的代码风格,使得Java的语言表达能力得到了提升。
但也有它的缺点所在,如果Lambda表达式用的不好的话,调试运行和后期维护非常的麻烦,尤其是调试的时候,debug模式都不会进去。
Lambda表达式对接口的要求:Lambda只能接受函数式接口(@FunctionalInterface),而函数式接口规定接口中只能有一个需要被实现的方法,意思就是只能有一个抽象方法,但不是规定接口中只能有一个方法,也可以有其它的方法,jdk8接口中可以定义普通方法,但是必须用default关键字修饰。
总结下来Lambda表达式的特点就是:
- 匿名:没有一个确定的名称
- 函数:lambda不属于一个特定的类,但是却有参数列表、函数主体、返回类型、异常列表
- 传递:可以作为参数传递给方法、或者存储在变量中
- 简洁:不需要写很多模板代码
- 接口:必须为函数式接口(@FunctionalInterface)
个人理解
作用
简化代码,基础代码都能实现
性能方面也不是很拉跨,否则早就 GG 了
基础语法
Lambda表达式在Java语言中引入了一个新的语法元素和操作符。这个操作符为->,该操作符被称为Lambda操作符或箭头操作符,它将Lambda分为两个部分:
- 左侧:指定了Lambda表达式所需要的所有参数。
- 右侧:指定了Lambda体,即Lambda表达式所要执行的功能。
Java8中的Lambda表达式的基本语法结构如下,当然,这里只是简单的Lambda 表达式的应用。后面还有使用多个简单Lambda 表达式组成的复合 Lambda 表达式。例如: 函数复合、谓词复合、比较器复合等各种形式的组合起来的Lambda表达式。对于初学者而言刚刚看到这种写法肯定是非常懵逼的,所以不要心急,慢慢来:
| 描述 | 格式 |
|---|---|
| 无参数,无返回值 void | () -> System.out.print(“Lambda…”) ; |
| 有一个参数,但无返回值 void | (String s) -> System.out.print(“Lambda…”) ; |
| 有参数,但是参数数据类型省略,由编译器推断,称为"类型推断" | (s) –> System.out.print(“Lambda…”) ; |
| 若只有一个参数,方法的括号可以省略,如果多个参数则必须写上 | s–> System.out.print(“Lambda…”) ; |
| 有参数,且有返回值,如果显式返回语句时就必须使用花括号“{}” | (s,t) –> s+t ;或 (s,t) –> {return s+t;}; |
| 如果有两个或两个以上的参数,并且有多条语句则需要加上“{}”,一条执行语句可以省略。 | (s,t) –> { System.out.print(s) ; System.out.print(t) ; return s+t; }; |
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.function.Consumer;
public class LambdaTest {
public static void main(String[] args) {
/* 创建线程 */
// 普通写法(匿名内部类)
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("匿名内部类创建线程");
}
});
t1.start();
// Lambda 写法,无参无返回
Thread t2 = new Thread(() -> System.out.println("Lambda 创建线程"));
t2.start();
/* 排序 */
// 普通写法,默认升序
List<Integer> list = Arrays.asList(32, 45, 23, 11, 55, 49, 72, 11, 20);
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1, o2); // 升序
//return Integer.compare(o1, o2); // 降序
}
});
System.out.println(list.toString());
// Lambda 表达式写法。有参有返回,“类型推断”
list.sort((o1, o2) -> Integer.compare(o1, o2)); // list.sort(Integer::compare);
System.out.println(list.toString());
/* 遍历 list */
// 普通写法
list.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
});
// lambda 写法
list.forEach(alist -> System.out.println(alist));
}
}方法引用
方法引用就是进一步的简化Lambda表达式声明的一种语法糖。也正是因为方法引用实在太简洁了,所以学习方法引用前必须要对Lambda表达式非常的熟悉,否则学习方法引用会非常的吃力😱,你可能都不知道这是在干啥😂。
方法引用使用操作符::将对象或类的名字和方法名分隔开来。方法引用有好几种形式,它们的语法如下:
| 描述 | 格式 | 方法引用示例(后面不要写括号) | 等价的Lambda表达式 |
|---|---|---|---|
| 静态方法引用 | ClassName::staticMethodName | Integer::parseInt | (a) -> Integer.parseInt(a) 或 (a, b) -> Integer.compare(a, b) |
| 实例方法引用 | instanceName::methodName | System.out::println 或 String::trim | (str) -> System.out.println(str) 或 (s) -> s.trim() |
| 类上的实例方法引用 | ClassName::methodName | String::equals 或 Person::getName | (x, y) -> x.equals(y) 或 (p) -> p.getName() |
| 父类上的实例方法引用 | super::methodName | super::toString | () -> super.toString() |
| 构造方法引用 | ClassName::new | Integer::new | (n) -> new String(n) |
| 数组构造方法引用 | TypeName[]::new | Integer[]::new | (n) -> new Integer[n] |
Stream API
list、数组等实例对象,先获取 stream 流,再进行一系列过滤、筛选、去重、映射(转换)等操作。
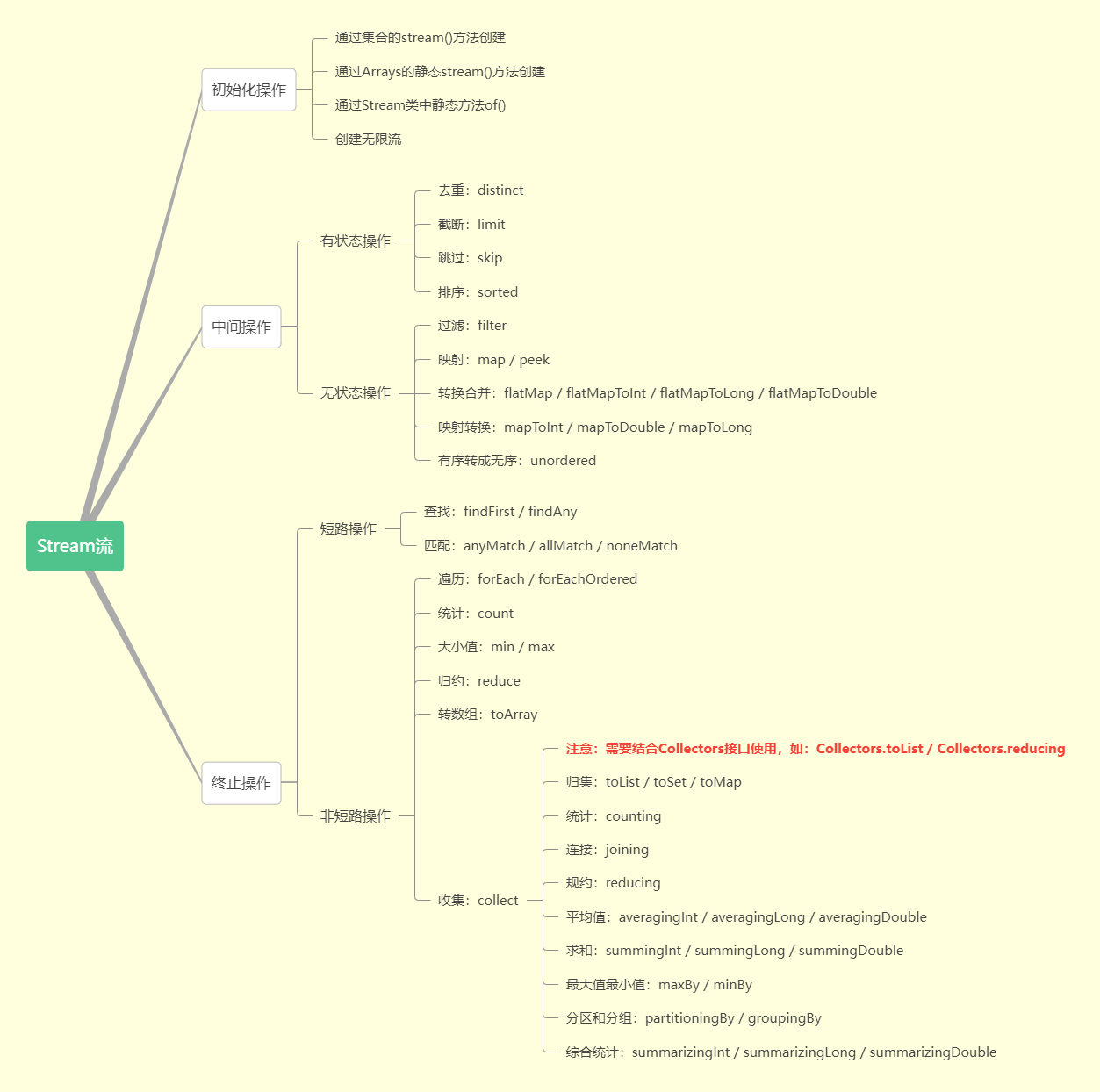
对于中间操作,又可以分为有状态的操作和无状态操作,具体如下:
- 有状态的操作是指当前元素的操作需要等所有元素处理完之后才能进行。
- 无状态的操作是指当前元素的操作不受前面元素的影响。
对于结束操作,又可以分为短路操作和非短路操作,具体如下:
- 短路操作是指不需要处理完全部的元素就可以结束。
- 非短路操作是指必须处理完所有元素才能结束。
正则表达式
正则表达式是一些特殊字符组成的校验规则,可以校验信息的正确性,校验邮箱、手机号、金额、密码等。
基本使用
简单校验邮箱
String email = “qwert123456@163.com”; // qwert123456@pic.com.cn
if (email.matches(“\\w{1,}@\\w{1,}(\\.\\w{1,}){1,}”)) {
// 邮箱校验通过
}校验 URL
public static boolean isUrl(String url) {
if(StringUtils.isBlank(url)) {
return true;
}
String regex = "(ht|f)tp(s?)\\:\\/\\/[0-9a-zA-Z]([-.\\w]*[0-9a-zA-Z])*(:(0-9)*)*(\\/?)([a-zA-Z0-9\\-\\.\\?\\,\\'\\/\\\\&%\\+\\$#_=]*)?";
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(url.trim());
boolean result = mat.matches();
return result;
}校验语法规则
在其他语言中,\\ 表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。
在 Java 中,\\ 表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如 Perl),一个反斜杠\ 就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。也可以简单的理解在 Java 的正则表达式中,两个 \\ 代表其他语言中的一个 \ ,这也就是为什么表示一位数字的正则表达式是 \\d ,而表示一个普通的反斜杠是 \\ 。
System.out.print("\\"); // 输出为 \
System.out.print("\\\\"); // 输出为 \\IO

IO 流的层次结构
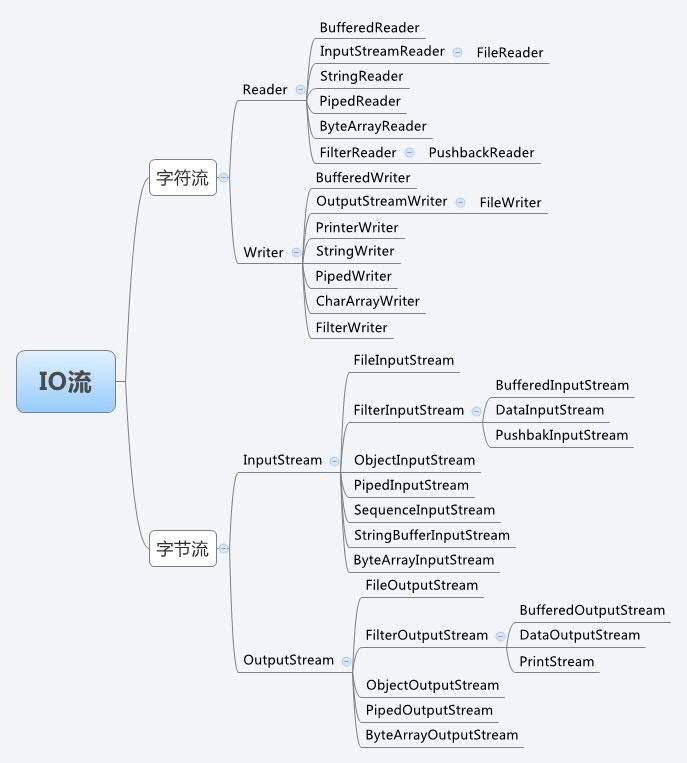
从流的方向:输入流、输出流
从流的类型上:字符流、字节流
inputstream和outputstream是抽象类
它们下面的实现包括
FileInputStream、BufferedInputStream
FileOutputStream、BufferedOutputStream
reader和writer是抽象类
子类实现包括
FileReader、BufferedReader、StringReader
FileWriter、BufferedWriter、StringWriter、PrintWriter
字节流与字符流的区别
stream结尾都是字节流,reader和writer结尾都是字符流。
两者的区别就是读写的时候一个是按字节读写,一个是按字符。
实际使用通常差不多。
在读写文件需要对内容按行处理,比如比较特定字符,处理某一行数据的时候一般会选择字符流。
只是读写文件,和文件内容无关的,一般选择字节流。
字节流注意事项
字节输入流读取一个一个字节(一滴一滴地接水)
一个一个字节读取英文和数字没问题。
一旦读取中文则会出现乱码,因为会截断中文的字节。
一个一个字节读取数据,性能也比较差,所以一般不用这种方式。
字节输入流读取一个一个字节数组(拿桶来接水)
使用字节数组读取数据,效率可以。
但使用字节数组读取文本内容输出,也无法避免中文字符输出乱码的问题。
字节流很适合作文件数据的复制。
如何实现字节流读取中文不乱码?
定义一个字节数组与文件的大小一样大,然后一桶水读取全部字节数据再输出。适合小文件内容读取,超过1G的大文件由于占内存大,不建议这样读取。(is.readAllBytes())
字节流并不适合读取文本内容输出,读写文件内容建议使用字符流。如果读取不用输出展示,只做数据复制,是没有问题的。
字符流注意事项
字符流不能用于复制非字符内容数据,比如图片、视频,因为字符流会将字节转换为字符,导致非字符文件打不开。
高级的字符缓冲流按照一个一个字节数组(1024)的形式复制性能很高,建议使用。
字符输入转换流、字符输出转换流,用于解决文件编码格式不一致导致乱码问题。中文Windows默认是GBK编码格式,新建的文本文件编码格式是GBK,如果使用UTF-8或其他编码格式读取,再输出会显示乱码。

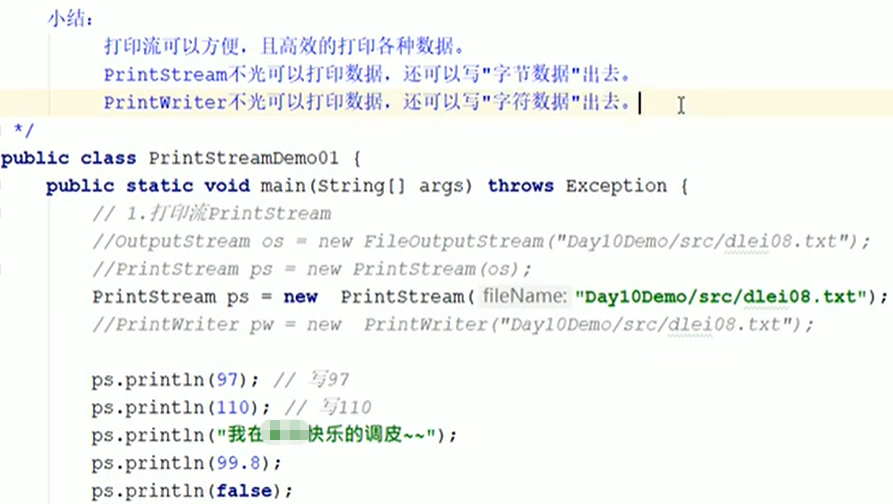
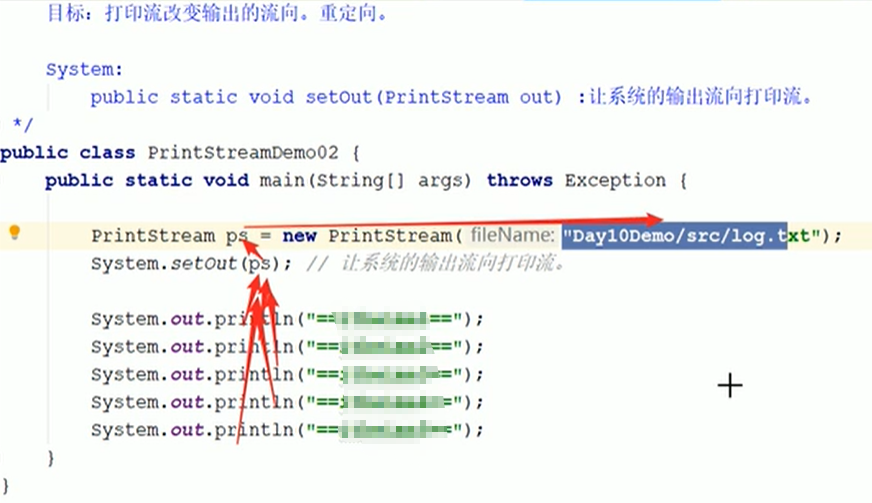
打印流
释放流资源新方式
NIO
什么是 NIO
Java NIO(New IO,Non-Blocking IO) 是从Java 1.4版本开始引入的一个新的IO API,可以替代标准的Java IO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的、基于通道的IO操作。NIO将以更加高效的方式进行文件的读写操作。
NIO 与普通 IO 的主要区别
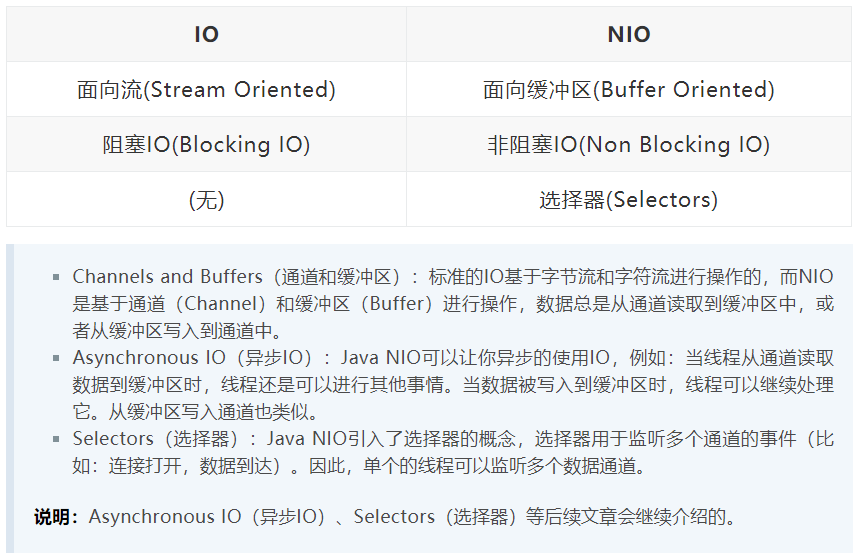
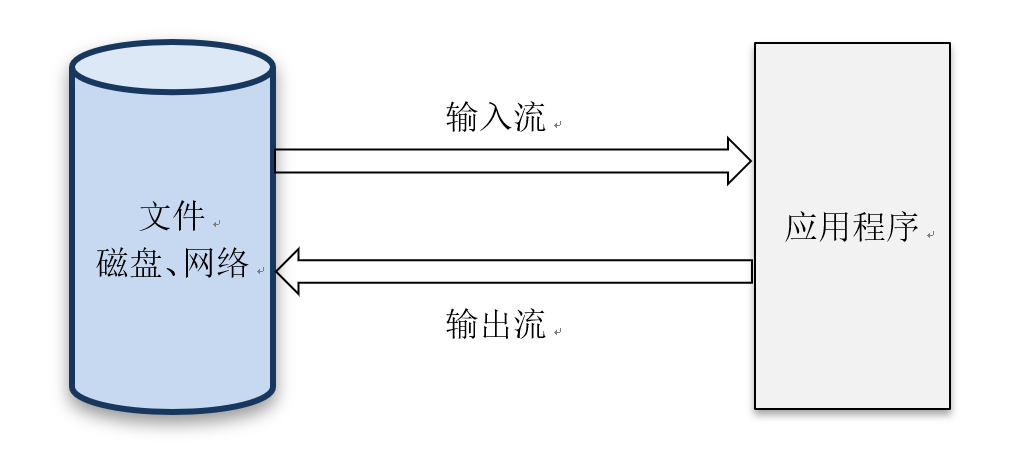
I/O 图解:
直接面对数据的流动
单向的
NIO 图解:
可以将缓冲区理解成火车
双向的
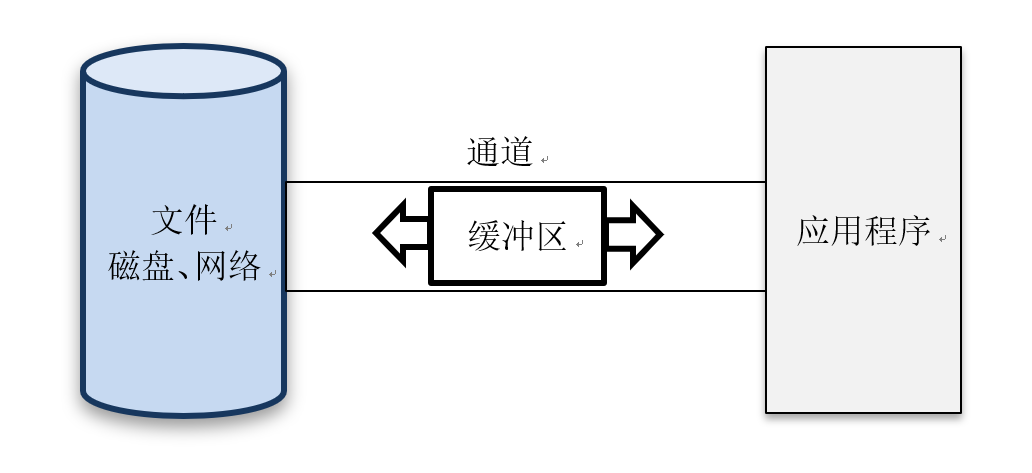
通道(Channel)和缓冲区(Buffer)
Java NIO系统的核心在于:通道(Channel)和缓冲区(Buffer)。
通道表示打开到 IO 设备(例如:文件、套接字)的连接。
若需要使用 NIO 系统,需要获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区。
然后操作缓冲区,对数据进行处理。
简而言之,Channel负责传输,Buffer负责存储。
缓冲区(Buffer)
缓冲区(Buffer):一个用于特定基本数据类型的容器。由java.nio包定义的,所有缓冲区都是Buffer抽象类的子类。
Java NIO中的Buffer主要用于与NIO通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的。
Buffer就像一个数组,可以保存多个相同类型的数据。根据数据类型不同(boolean除外) ,有以下Buffer常用子类:
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
上述Buffer类他们都采用相似的方法进行管理数据,只是各自管理的数据类型不同而已。
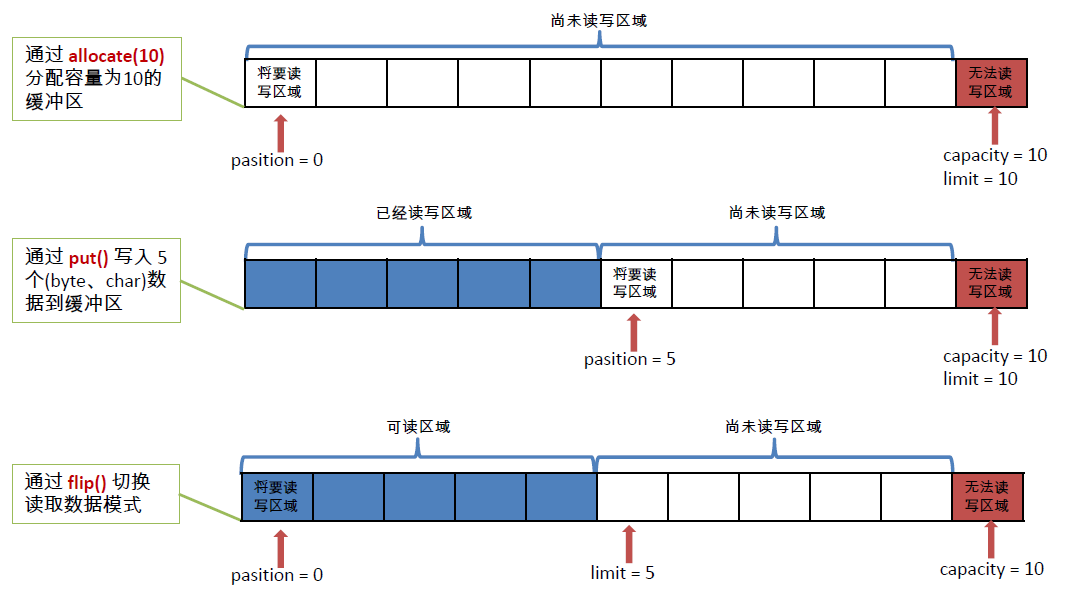
缓冲区的基本属性
容量(capacity) :表示Buffer 最大数据容量,缓冲区容量不能为负,并且创建后不能更改。
限制(limit):第一个不应该读取或写入的数据的索引,即位于limit后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量。
位置(position):下一个要读取或写入的数据的索引。缓冲区的位置不能为负,并且不能大于其限制。
标记(mark)与重置(reset):标记是一个索引,通过Buffer中的mark()方法指定Buffer中一个特定的position,之后可以通过调用reset()方法恢复到这个position。
标记、位置、限制、容量遵守以下不变式:0 <= mark <= position <= limit <= capacity
Buffer 的常用方法
| 方法 | 描述 |
|---|---|
| Buffer clear() | 清空缓冲区并返回对缓冲区的引用 |
| Buffer flip() | 将缓冲区的界限设置为当前位置,并将当前位置重置为0 |
| int capacity() | 返回Buffer的capacity大小 |
| boolean hasRemaining() | 判断缓冲区中是否还有元素 |
| int remaining() | 返回position和limit之间的元素个数 |
| int limit() | 返回Buffer的界限(limit)的位置 |
| Buffer limit(int n) | 将设置缓冲区界限为n, 并返回一个具有新limit的缓冲区对象 |
| Buffer mark() | 对缓冲区设置标记 |
| int position() | 返回缓冲区的当前位置position |
| Buffer position(int n) | 将设置缓冲区的当前位置为n , 并返回修改后的Buffer对象 |
| Buffer reset() | 将位置position转到以前设置的mark所在的位置 |
| Buffer rewind() | 将位置设为为0,取消设置的mark |
缓冲区的数据操作
Buffer所有子类提供了两个用于数据操作的方法:get() 与put() 方法。
获取Buffer中的数据
get() :读取单个字节
get(byte[] dst):批量读取多个字节到dst 中
get(int index):读取指定索引位置的字节(不会移动position)
放入数据到Buffer中
put(byte b):将给定单个字节写入缓冲区的当前位置
put(byte[] src):将src 中的字节写入缓冲区的当前位置
put(int index, byte b):将指定字节写入缓冲区的索引位置(不会移动position)
直接与非直接缓冲区
(理论概念太长不看!)
字节缓冲区要么是直接的,要么是非直接的。如果为直接字节缓冲区,则 Java 虚拟机会尽最大努力直接在此缓冲区上执行本机 I/O 操作。也就是说,在每次调用基础操作系统的一个本机 I/O 操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容)。
直接字节缓冲区可以通过调用此类的 allocateDirect() 工厂方法来创建。此方法返回的缓冲区进行分配和取消分配所需成本通常高于非直接缓冲区。直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此,它们对应用程序的内存需求量造成的影响可能并不明显。所以,建议将直接缓冲区主要分配给那些易受基础系统的本机 I/O 操作影响的大型、持久的缓冲区。一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显好处时分配它们。
直接字节缓冲区还可以通过 FileChannel的map() 方法将文件区域直接映射到内存中来创建。该方法返回 MappedByteBuffer。Java 平台的实现有助于通过 JNI 从本机代码创建直接字节缓冲区。如果以上这些缓冲区中的某个缓冲区实例指的是不可访问的内存区域,则试图访问该区域不会更改该缓冲区的内容,并且将会在访问期间或稍后的某个时间导致抛出不确定的异常。
字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其 isDirect() 方法来确定。提供此方法是为了能够在性能关键型代码中执行显式缓冲区管理。
非直接缓冲区
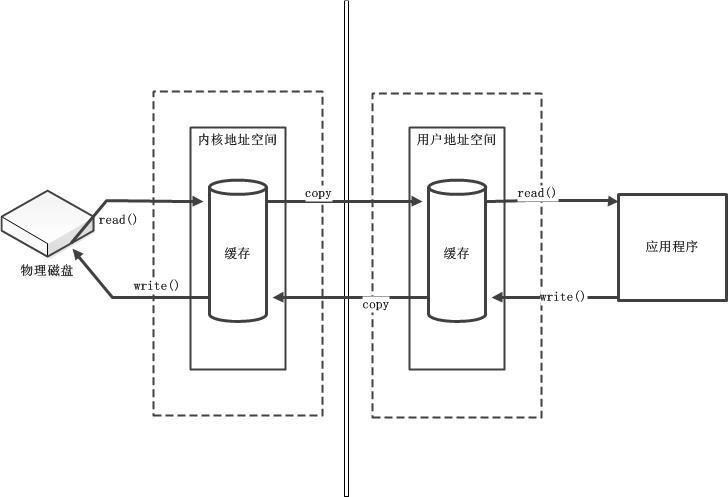
直接缓冲区
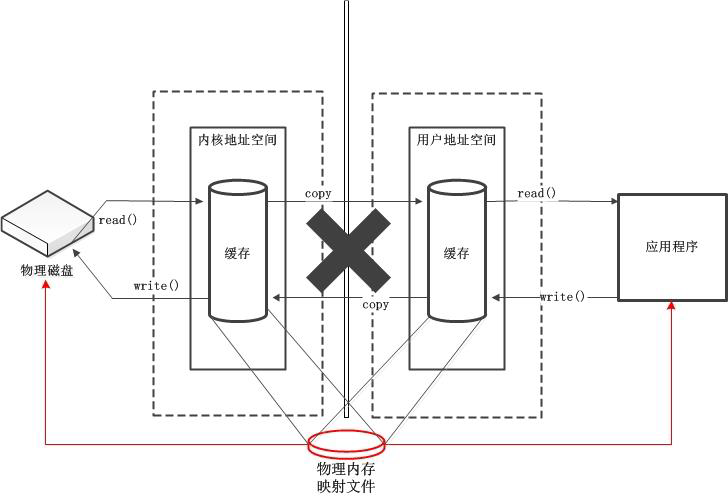
直接缓冲区的问题:
性能不是很稳定。操作系统文件操作已经完成,但程序依赖JVM管理,造成两边处理时间不一致的情况。简单的说,系统完成一个文件复制需要2秒,但程序依赖JVM释放资源可能持续10秒。
大文件可能导致高内存占用(要验证)。因为是直接使用物理映射内存,没有使用缓冲区,一次性读取几个G的大文件,很可能直接撑爆物理内存,或者导致程序内存溢出。
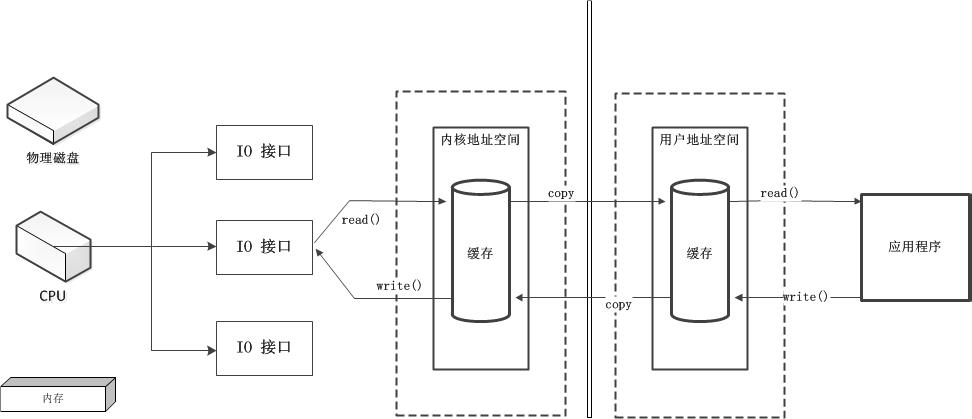
通道(Channel)
通道(Channel):由java.nio.channels 包定义的。Channel 表示 IO 源与目标打开的连接。Channel 类似于传统的“流”。只不过 Channel 本身不能直接访问数据,Channel 只能与 Buffer 进行交互。
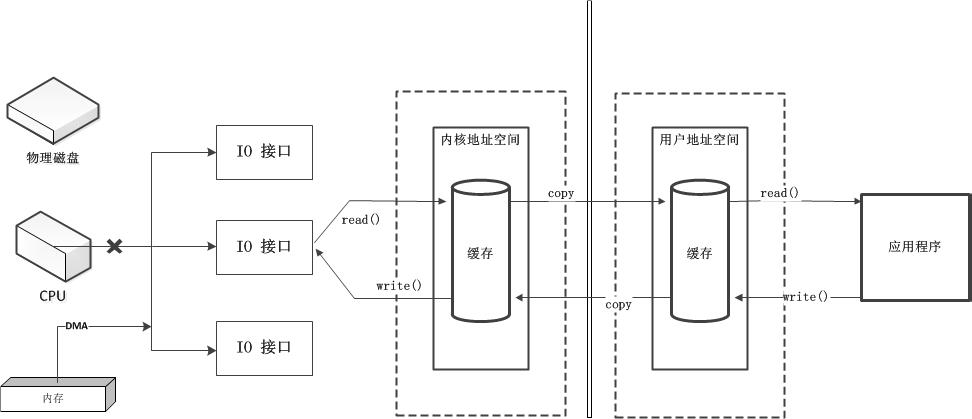
传统I/O基于DMA总线,在大批量I/O操作的场景会导致DMA总线冲突问题,最后依然需要CPU介入处理。
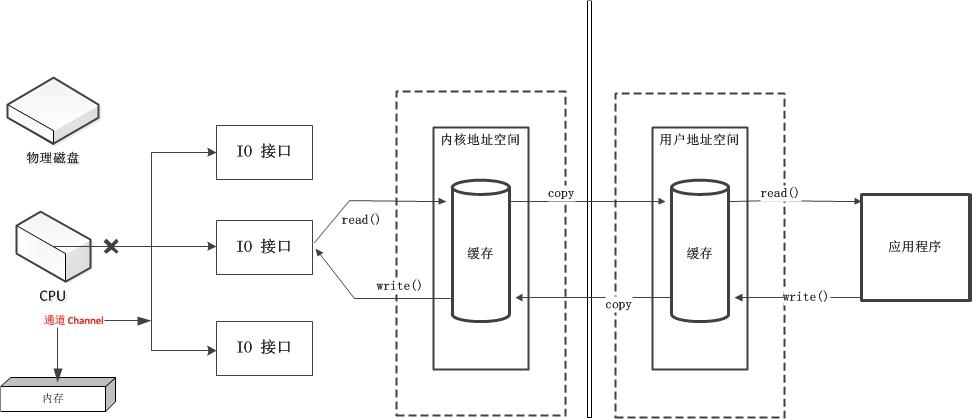
通道(Channel)拥有自己的数据处理器,可以不依赖CPU独立工作,对于大批量I/O场景能发挥很好的性能效果。
Channel 接口实现类
Java 为Channel接口提供的最主要实现类如下:
FileChannel:用于读取、写入、映射和操作文件的通道。
DatagramChannel:通过UDP 读写网络中的数据通道。
SocketChannel:通过TCP 读写网络中的数据。
ServerSocketChannel:可以监听新进来的TCP 连接,对每一个新进来的连接都会创建一个SocketChannel。
获取通道
获取通道的一种方式是对支持通道的对象调用getChannel() 方法。支持通道的类如下:
- 本地IO:
FileInputStream
FileOutputStream
RandomAccessFile
- 网络IO:
DatagramSocket
Socket
ServerSocket
JDK1.7种的NIO.2针对各个通道提供了静态方法open()。
JDK1.7种的NIO.2使用Files类的静态方法newByteChannel() 获取字节通道。
通道的数据传输
将Buffer 中数据写入Channel
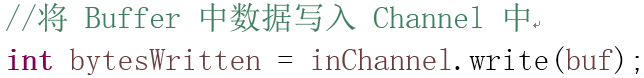
从Channel 读取数据到Buffer

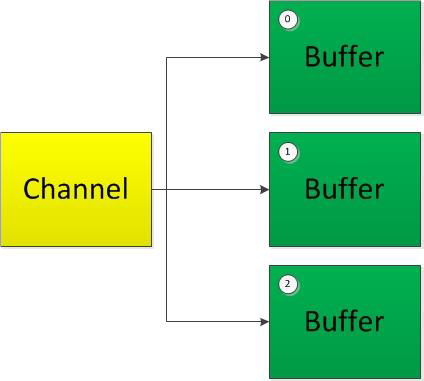
分散(Scatter)和聚集(Gather)
分散读取(Scattering Reads)是指从Channel 中读取的数据“分散”到多个Buffer 中。
注意:按照缓冲区的顺序,从Channel 中读取的数据依次将Buffer 填满。
聚集写入(Gathering Writes)是指将多个Buffer 中的数据“聚集”到Channel。
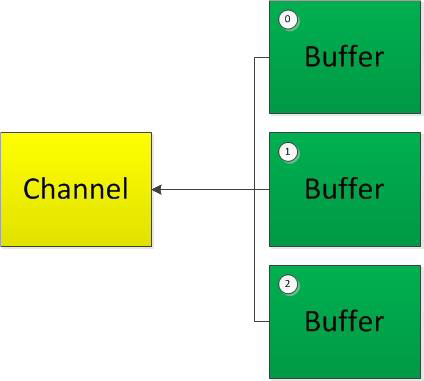
注意:按照缓冲区的顺序,写入position 和limit 之间的数据到Channel 。
transferFrom()
将数据从源通道传输到其他Channel 中。
走直接缓冲区。

transferTo()
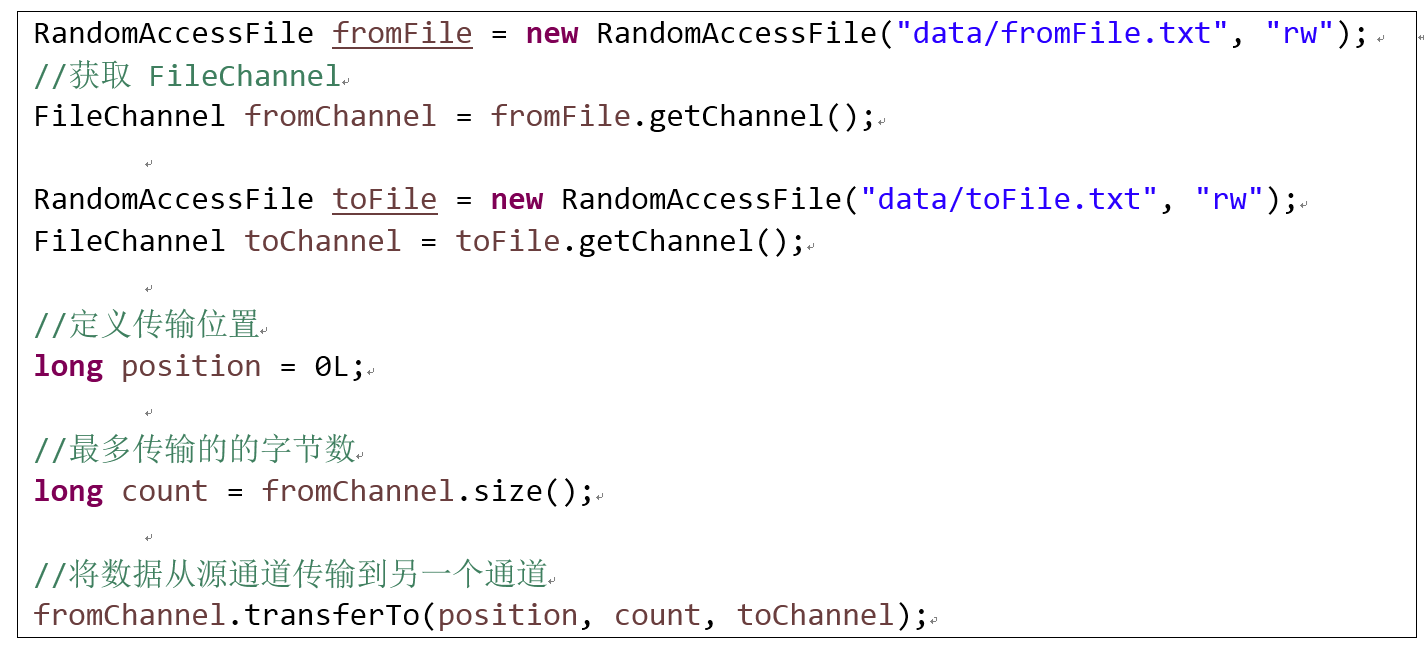
FileChannel 常用方法
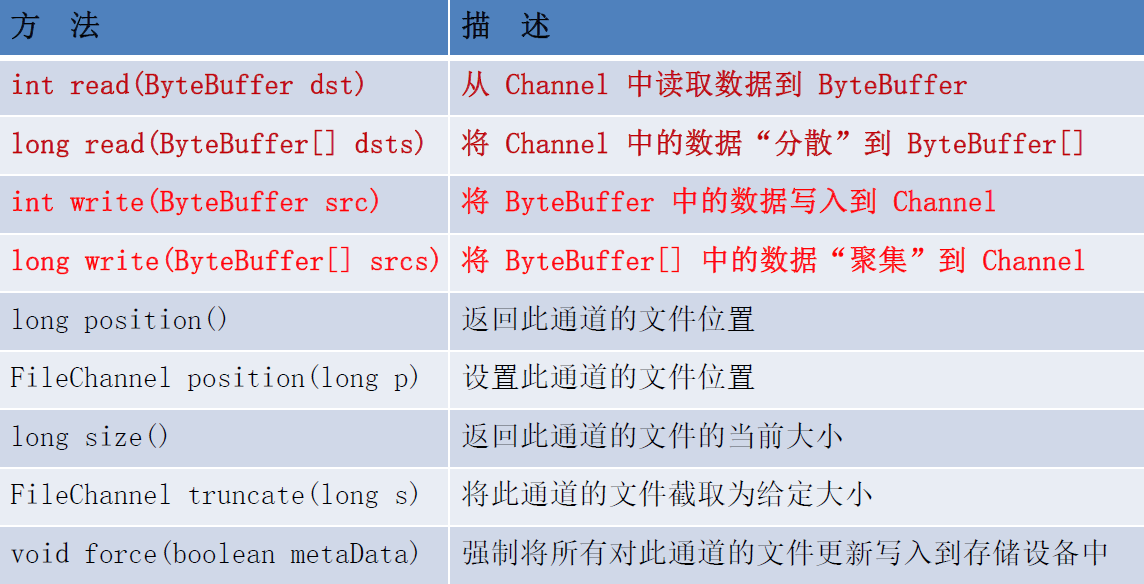
NIO 的非阻塞式网络通信
NIO.2–Path、Paths、Files
随着JDK 7的发布,Java对NIO进行了极大的扩展,增强了对文件处理和文件系统特性的支持,以至于我们称他们为NIO.2。因为NIO提供的一些功能,NIO已经成为文件处理中越来越重要的部分。
Path 与 Paths
java.nio.file.Path接口代表一个平台无关的平台路径,描述了目录结构中文件的位置。
Paths提供的get()方法用来获取Path 对象:
- Pathget(String first, String … more) : 用于将多个字符串串连成路径。
- Path常用方法:
boolean endsWith(String path) : 判断是否以path 路径结束
boolean startsWith(String path) : 判断是否以path 路径开始
boolean isAbsolute() : 判断是否是绝对路径
Path getFileName() : 返回与调用Path 对象关联的文件名
Path getName(int idx) : 返回的指定索引位置idx 的路径名称
int getNameCount() : 返回Path 根目录后面元素的数量
Path getParent() :返回Path对象包含整个路径,不包含Path 对象指定的文件路径
Path getRoot() :返回调用Path 对象的根路径
Path resolve(Path p) :将相对路径解析为绝对路径
Path toAbsolutePath() : 作为绝对路径返回调用Path 对象
String toString() :返回调用Path 对象的字符串表示形式
Files 类
java.nio.file.Files 用于操作文件或目录的工具类。
Files常用方法:
Path copy(Path src, Path dest, CopyOption … how) : 文件的复制
PathcreateDirectory(Path path, FileAttribute<?> … attr) : 创建一个目录
Path createFile(Path path, FileAttribute<?> … arr) : 创建一个文件
void delete(Path path) : 删除一个文件
Path move(Path src, Path dest, CopyOption…how) : 将src 移动到dest 位置
long size(Path path) : 返回path 指定文件的大小
- Files常用方法:用于判断
boolean exists(Path path, LinkOption … opts) : 判断文件是否存在
boolean isDirectory(Path path, LinkOption … opts) : 判断是否是目录
boolean isExecutable(Path path) : 判断是否是可执行文件
boolean isHidden(Path path) : 判断是否是隐藏文件
boolean isReadable(Path path) : 判断文件是否可读
boolean isWritable(Path path) : 判断文件是否可写
boolean notExists(Path path, LinkOption … opts) : 判断文件是否不存在
public static <A extends BasicFileAttributes> A readAttributes(Path path,Class<A> type,LinkOption... options) : 获取与path 指定的文件相关联的属性
- Files常用方法:用于操作内容
- SeekableByteChannel newByteChannel(Path path, OpenOption…how) : 获取与指定文件的连接,how 指定打开方式
- DirectoryStream newDirectoryStream(Path path) : 打开path 指定的目录
- InputStream newInputStream(Path path, OpenOption…how):获取InputStream 对象
- OutputStream newOutputStream(Path path, OpenOption…how) : 获取OutputStream 对象
自动资源管理
Java 7 增加了一个新特性,该特性提供了另外一种管理资源的方式,这种方式能自动关闭文件。这个特性有时被称为自动资源管理(Automatic Resource Management, ARM),该特性以try 语句的扩展版为基础。自动资源管理主要用于,当不再需要文件(或其他资源)时,可以防止无意中忘记释放它们。
自动资源管理基于try语句的扩展形式:
try(需要关闭的资源声明){
//可能发生异常的语句
}catch(异常类型变量名){
//异常的处理语句
}
……
finally{
//一定执行的语句
}
当try 代码块结束时,自动释放资源。因此不需要显示的调用close() 方法。该形式也称为“带资源的try 语句”。
注意:
try语句中声明的资源被隐式声明为final,资源的作用局限于带资源的try语句。
可以在一条try语句中管理多个资源,每个资源以“;”隔开即可。
需要关闭的资源,必须实现AutoCloseable接口或其自接口Closeable。
实际开发应用案例
新特性
在《JDK新版本特性》单独整理
WEB
Jsp/Servlet
Servlet 的生命周期
实例化阶段:服务器对Servlet进行实例化,调用Servlet的构造方法
初始化阶段:服务器调用Servlet的init方法进行初始化(只在第一次请求时调用)。
请求处理阶段:服务器调用Servlet的service方法,然后根据请求方式调用相应的doXXX方法。
服务终止阶段:服务器调用Servlet的destroy方法销毁Servlet实例
Servlet 执行流程
客户端发出http请求,web服务器将请求转发到servlet容器,servlet容器解析url并根据web.xml找到相对应的servlet,并将request、response对象传递给找到的servlet,servlet根据request就可以知道是谁发出的请求,请求信息及其他信息,当servlet处理完业务逻辑后会将信息放入到response并响应到客户端。
Jsp 与 Servlet 的区别
JSP的本质就是Servlet,JVM只能识别java的类,不能识别JSP的代码,Web容器将JSP的代码编译成JVM能够识别的java类。
JSP 工作原理:
JSP页面在执行的时候都会被服务器端的JSP引擎转换为Servelet(.java),然后又由JSP引擎调用Java编译器,将Servelet(.java)编译为Class文件(.class),并由Java虚拟机(JVM)解释执行。下面验证这一点:
有一个JSP页面Test.jsp,在浏览器地址栏中输入http://localhost:8080/Test.jsp,将会出现执行结果。同时在%CATALINA_HOME%/work/Catalina/localhost下多出两个文件:_Test_jsp.java和_Test_jsp.class,他们分别就是Servelet和Class文件。
JSP侧重于视图,Servlet主要用于控制逻辑。Servlet的应用逻辑是在Java文件中,从Java代码中动态输出HTML,并且完全从表示层中的HTML里分离开来。而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。
Forword(请求转发)与Redirect(重定向)
从数据共享上
Forword是一个请求的延续,可以共享request的数据
Redirect开启一个新的请求,不可以共享request的数据
从地址栏
- Forword转发地址栏不发生变化
- Redirect转发地址栏发生变化
网络编程
详细内容参考计算机网络。
TCP
UDP
HTTP
get、post、put、patch 与 delete 之间的区别
- get:从服务器端获取数据,请求参数在地址栏上。
- post:向服务器端提交数据,请求参数在报文body里。
发送一个修改数据的请求,需求数据要从新创建。
- put:向服务器端提交数据,请求参数在报文body里。
发送一个修改数据的请求,需求数据更新(全部更新)。
- patch:向服务器端提交数据,请求参数在报文body里。
发送一个修改数据的请求,需求数据更新(部分更新)。
- delete:向服务器端提交数据,请求参数在报文body里。
发送一个删除数据的请求。
HttpClient 4.5.x
- 使用单例
- 配置连接池
- 启动额外清理线程
OkHttp
- 安卓开发内置
- 性能跟HttpClient差不多
- 可能使用方面简便一点?看个人习惯
- 一样有些小问题,超时设置