Java设计模式
挑几个重点模式理解记忆就行了,把23种模式都记住,没这个必要,过几天不用,就全忘了!
七大原则
各模式类型重点记两三个,9个左右,还是能记住的!
前言
设计模式背景
1995年,GoF(Gang of Four,四人组/四人帮)合作出版了《设计模式:可复用面向对象软件的基础》一书,共收录了 23 种设计模式,从此树立了软件设计模式领域的里程碑,人称「GoF设计模式」。
什么是设计模式
设计模式(Design Pattern)是前辈们对代码开发经验和技巧的总结,是解决特定问题的一系列策略与套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。
说白了就好比
- 游戏王者把他们的玩法总结成技巧攻略,供低段位玩家模仿学习。
- 大厨把做菜技巧写成菜谱,供厨房小白学习。
设计模式到目前为止,肯定不止23种,23种只不过是得到广泛认知,并写进了书籍当中地,几年前就23种设计模式在教学了,现在和未来一直在完善更新。
游戏大神可能会不断地推出的攻略技巧,程序大佬们自然也会不断完善更新并推出新的设计模式,没有一成不变的地东西,保守陈旧意味着被淘汰埋没了。
上层社会的人占着优质资源的优势,制定出一系列有利于他们的规则条例,下层的人还屁颠屁颠地追赶者他们的步伐。马云说他对钱没有兴趣,你也追着学吗?
规则只是用来指导你的,不是用来限制你的,只要设计合理,你的设计就是规则!
设计模式的作用/意义/目的
编写软件过程中,程序员面临着来自耦合性,内聚性以及可维护性,可扩展性,重用性,灵活性等多方面的挑战。
可靠性:当我们增加新的功能后,对原来的功能没有影响。
可读性:编程规范性,便于其他程序员的阅读和理解。
可扩展:当需要增加新的功能时,非常的方便,也称为可维护。
重用性:相同功能的代码,不用多次编写,使程序呈现“高内聚,低耦合”的特性。
当然,设计模式只是一个引导,在实际开发中,需要根据具体的需求来选择:
对于简单的程序,可能写一个简单的算法要比引入某种设计模式更加容易;
但是对于大型项目开发或者框架设计,用设计模式来组织代码显然更好。
为什么要掌握设计模式
为什么要学习设计模式,学习总要有个驱动力。
有过工作经验的人应该都知道,特别是那些在维护一个项目的人更是体会的贴切,有时候,一个很简单的需求,或者说,本来应该是很快就可以实现的需求,但是由于系统当初设计的时候没有考虑这些需求的变化,或者随着需求的累加,系统越来越臃肿,导致随便修改一处会出现“牵一发而动全身”的问题,甚至可能造成不可预料的后果。
设计模式可以帮助我们改善系统的设计,增强系统的健壮性、可扩展性,为以后铺平道路。
但是,这些是我当初第一次接触设计模式时的感受,现在我并不这么认为,设计模式可以改善系统的设计是没错,但是过多的模式也会系统变的复杂。所以当我们第一次设计一个系统时,请将你确定的变化点处理掉,不确定的变化点千万不要假设它存在,如果你曾经这么做过,那么请改变你的思维,让这些虚无的变化点在你脑子中彻底消失。
因为我们完全可以使用另外一种手法来容纳我们的变化点,那就是重构,不过这是我们在讨论过设计模式之后的事情,现在我们就是要把这些设计模式全部理解,来锻炼我们的设计思维,而不是做一个只会“搬砖”的码农。
怎样学习掌握设计模式
**学习方法最大的通病:**大篇幅整理笔记,导致缺乏实践训练!
以为自己掌握了很多知识技术点,实则仅仅接触到了皮毛,稍微问深入一点的问题,就直接傻逼了!
很少有人会把 23 种设计模式全部记在脑海里,“用进废退”是生物的本能,学了不用或者用的少,就算你再怎么遵循“艾宾浩斯记忆遗忘曲线”重复记忆,工作用不着,还死记硬背,成本远远大于回报的事,慈善家都不会做!
着重熟练理解自己用过的,以及技术框架内使用频繁的,也就六七个左右,其他就按自己理解的描述就行了。
面试官自己几乎也不会全记住,都是挑使用频率高的,重点理解记忆就行了!
“重实践,后概念”,学习先得有一个整体的结构脉络,先有主干,细枝末节后续补充完善。突出“重难点”,小的概念理论题目,在“重难点”的学习突破过程中,也会随着加深印象,主干通了,细节内容也基本能串联起来。
把所有的细节理论内容都摘抄下来,你是准备出书吗?摘抄算侵权的哦,就算引用,全篇都是引用,没意义的!也就自己看,整理自己的学习笔记,帮助知识体系构建、重难点内容突破、常碰到的理论概念记忆,说白了就是为了应付考试、面试,或者工作中遇到坑了总结经验教训。把自己的笔记当学习资料看的,是网上的资料书籍不香吗?你的笔记能把市面上所有的资料书都整理一遍?
不停地做笔记,甚至大段大段地摘抄整理知识点,建立自己的知识结构体系,不是把书本资料上的知识内容都整理记录到自己的笔记上,这个过程是非常非常耗费时间和精力的,等你整理好了,整个高三就结束了!!!这是亲身经历的两次GK失利的惨痛教训啊,还不够深刻吗?还要整理?整理了看得懂?看得完?记得住?会做题?能运用?
看着各个设计模式模板化的概念内容,一个个硬生生、脱离实际生活的例子,就感受到一股强烈校园考试周看书备考的气息,这是主动学习吗?摘抄大篇大段的书本式内容,不容易看懂,也不好理解,可为什么还要摘抄啊?就是为了建立自己的知识内容体系?按自己的理解组织语言它不香吗?简明扼要的概括,比通篇摘抄书本概念更有效果啊!都工作了,谁还问你概念内容啊,面试官自己都不记这些玩意了,都是按自己的理解组织语言了啊~
实际成果驱动才是最有效的学习方式,而理论概念根本驱不动。这里无意挑起文理科争论,只是讲述人类的本能规律,相比死记硬背,实践理解的记忆更加深刻,并且不必担心过几天就忘掉的情况。应试教育啊,从小学到大学,学的知识内容,现在还记得多少呢,毕业工作生活用不到的,几乎都忘得一干二净了!
一个有趣的(正常)现象:
很多人都认为自己整理的资料是最完整的,网上其他人整理的都乱七八糟的,很不习惯。这个现象很正常啊,个人的习惯和喜好都不尽相同,你以为的完美,在别人眼中可能也是乱七八糟的的东西。
那怎么办?看资料内容的完整程度,达到60%以上的就可以保存下来,作为基础参考资料,不够完整的,就摘取其中写得好的部分,整理到自己的笔记内容体系中。
整理目标:
把生僻拗口又难懂的书本概念按自己的理解重新描述。
把那些偏离实际生活的例子,换成生活中常见的案例,程序本来就是服务于生活的,找不到生活案例的程序,说明它已经不常见了,也就没有必要再管它了。
简化大段大段的概念内容、牢骚废话理论,重实践,后概念。
UML类图、案例、实现代码、真实场景(概念、优缺点讲得太迷糊,还是用自己的理解转述)。
23种设计模式
设计模式的分类
设计模式有两种分类方法,即根据模式的目的来分和根据模式的作用范围来分。
根据目的来分
根据模式是用来完成什么工作来划分,这种方式可分为创建型模式、结构型模式和行为型模式三种。
创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”。GoF 中提供了单例、原型、工厂方法、抽象工厂、建造者等 5 种创建型模式。
结构型模式:用于描述如何将类或对象按某种布局组成更大的结构,GoF 中提供了代理、适配器、桥接、装饰、外观、享元、组合等 7 种结构型模式。
行为型模式:用于描述类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,以及怎样分配职责。GoF 中提供了模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器等 11 种行为型模式。
创建型模式:对象实例化的模式,创建型模式用于解耦对象的实例化过程。
结构型模式:把类或对象结合在一起形成一个更大的结构。
行为型模式:类和对象如何交互,及划分责任和算法。

根据作用范围来分
根据模式是主要用于类上还是主要用于对象上来分,这种方式可分为类模式和对象模式两种。
类模式:用于处理类与子类之间的关系,这些关系通过继承来建立,是静态的,在编译时刻便确定下来了。GoF中的工厂方法、(类)适配器、模板方法、解释器属于该模式。
对象模式:用于处理对象之间的关系,这些关系可以通过组合或聚合来实现,在运行时刻是可以变化的,更具动态性。GoF 中除了以上 4 种,其他的都是对象模式。
GoF 的 23 种设计模式的分类表
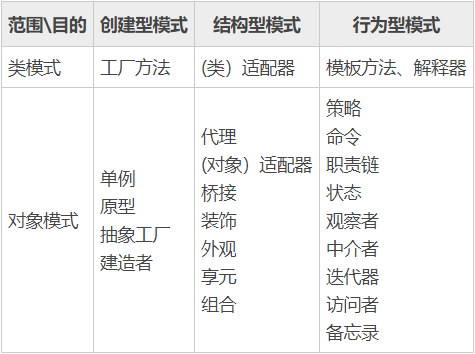
GoF的23种设计模式的功能
单例(Singleton)模式:某个类只能生成一个实例,该类提供了一个全局访问点供外部获取该实例,其拓展是有限多例模式。
原型(Prototype)模式:将一个对象作为原型,通过对其进行复制而克隆出多个和原型类似的新实例。
工厂方法(Factory Method)模式:定义一个用于创建产品的接口,由子类决定生产什么产品。
抽象工厂(AbstractFactory)模式:提供一个创建产品族的接口,其每个子类可以生产一系列相关的产品。
建造者(Builder)模式:将一个复杂对象分解成多个相对简单的部分,然后根据不同需要分别创建它们,最后构建成该复杂对象。
代理(Proxy)模式:为某对象提供一种代理以控制对该对象的访问。即客户端通过代理间接地访问该对象,从而限制、增强或修改该对象的一些特性。
适配器(Adapter)模式:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。
桥接(Bridge)模式:将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
装饰(Decorator)模式:动态的给对象增加一些职责,即增加其额外的功能。
外观(Facade)模式:为多个复杂的子系统提供一个一致的接口,使这些子系统更加容易被访问。
享元(Flyweight)模式:运用共享技术来有效地支持大量细粒度对象的复用。
组合(Composite)模式:将对象组合成树状层次结构,使用户对单个对象和组合对象具有一致的访问性。
模板方法(TemplateMethod)模式:定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
策略(Strategy)模式:定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的改变不会影响使用算法的客户。
命令(Command)模式:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。
职责链(Chain of Responsibility)模式:把请求从链中的一个对象传到下一个对象,直到请求被响应为止。通过这种方式去除对象之间的耦合。
状态(State)模式:允许一个对象在其内部状态发生改变时改变其行为能力。
观察者(Observer)模式:多个对象间存在一对多关系,当一个对象发生改变时,把这种改变通知给其他多个对象,从而影响其他对象的行为。
中介者(Mediator)模式:定义一个中介对象来简化原有对象之间的交互关系,降低系统中对象间的耦合度,使原有对象之间不必相互了解。
迭代器(Iterator)模式:提供一种方法来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
访问者(Visitor)模式:在不改变集合元素的前提下,为一个集合中的每个元素提供多种访问方式,即每个元素有多个访问者对象访问。
备忘录(Memento)模式:在不破坏封装性的前提下,获取并保存一个对象的内部状态,以便以后恢复它。
解释器(Interpreter)模式:提供如何定义语言的文法,以及对语言句子的解释方法,即解释器。
必须指出,这23种设计模式不是孤立存在的,很多模式之间存在一定的关联关系,在大的系统开发中常常同时使用多种设计模式。
UML中的类图及类图之间的关系
计算长方形和圆形的周长Perimeter[pəˈrɪmɪtər]与面积Area的类图。
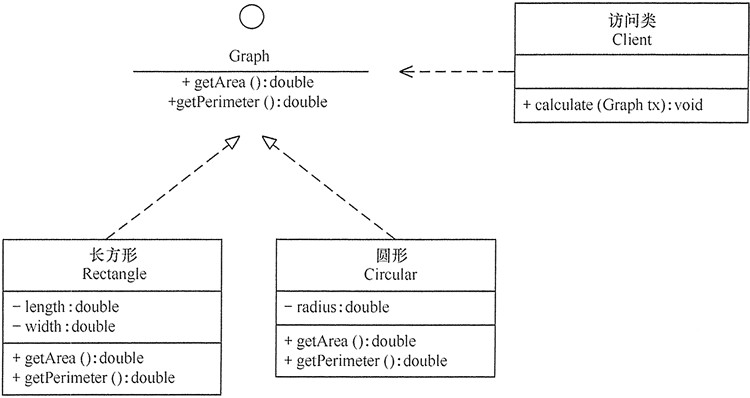
实体表示
实体类

可见性表示该属性对类外的元素是否可见,包括公有(Public)、私有(Private)、受保护(Protected)和朋友(Friendly)4 种,在类图中分别用符号+、-、#、~表示。
抽象类
接口
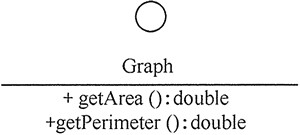
关系符号
| 符号 | 关系 |
|---|---|
| ------> | 依赖(使用) 类的成员属性 方法返回类型 方法参数类型 方法中使用到 |
| —— | 关联 单向一对一(人对应身份证) 双向一对一(人与身份证双向对应) 一对多 多对一 多对多 |
| ——▷ | 泛化(继承) |
| ------▷ | 实现 |
| ◇—— | 聚合 整体与部分可以分开 电脑与鼠标、键盘、显示器等 |
| ◆—— | 组合(实心的,固实了,不可分开) 整体与部分不可以分开 鸟与翅膀 |
设计模式七大原则
设计模式原则,其实就是程序员在编程时,应当遵守的原则,也是各种设计模式的基础。
设计模式常用的七大原则:
开闭原则
里氏替换原则
依赖倒置原则
单一职责原则
接口隔离原则
迪米特法则
合成复用原则
开闭原则(Open-Closed Principle, OCP)
定义:
当应用的需求改变时,在不修改软件实体的源代码或者二进制代码的前提下,可以扩展模块的功能,使其满足新的需求。
这是系统设计的理想境界,但是没有任何一个系统可以做到这一点,哪怕是Spring框架也做不到,虽说它的扩展性已经强到变态。
在《大话设计模式》一书中,提到用抽象构建框架,用细节实现扩展。
作用:
**对软件测试的影响。**软件遵守开闭原则的话,软件测试时只需要对扩展的代码进行测试就可以了,因为原有的测试代码仍然能够正常运行。
**可以提高代码的可复用性。**粒度越小,被复用的可能性就越大;在面向对象的程序设计中,根据原子和抽象编程可以提高代码的可复用性。
**可以提高软件的可维护性。**遵守开闭原则的软件,其稳定性高和延续性强,从而易于扩展和维护。
里氏替换原则(Liskov Substitution Principle, LSP)
这种按人名定义的概念,没什么好说的,肯定是为了应付考试面试才记,记了不用,分分钟忘得一干二净。前辈们很喜欢搞一大堆理论概念,后辈们免不了要背要记,想想十年百年后的子孙吧,他们要学要记的知识体系犹如星辰大海。理论概念这种东西,没人能原封不动地照着书上一字不差地记个十年二十年的,就算有人能记住,理论概念也是会随着年份推移和认知改善而变化的,所以,按自己的理解说就是了,考试没记住的内容,不就是按自己的理解随便写吗?工作面试官也不会变态到在概念上为难你跟你死磕细节,如果真的为难你了,那就是他对你的(第一)印象不满意(看人、看脸、看说话语气、看精神面貌,面试不过,原因多了去了),面试官看你不顺眼,根本没打算好好面试,就想着赶紧把你打发走了事。遇到这种面试官,你应该兴庆自己没被看中,不然进了公司,说不定还要遭受更多偏见和不公平待遇。
定义:
所有引用基类(父类)的地方必须能透明地使用其子类的对象。
通俗的说,子类可以扩展父类的功能,但不能改变父类原有的功能。
子类一般不该重写父类的方法,因为父类的方法一般都是对外公布的接口,是具有不可变性的,你不该将一些不该变化的东西给修改掉。
很多情况下,我们不必太理解里氏替换这个文静的妹子,比如模板方法模式,缺省适配器,装饰器模式等一些设计模式,就完全不搭理这个文静的妹子。
分析:
子类可以实现父类的抽象方法,但是不能覆盖父类的非抽象方法;
子类中可以增加自己特有的方法;
当子类覆盖或实现父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松;
当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
如果子类不能完整地实现父类的方法,或者父类的一些方法在子类中已经发生畸变,则建议断开继承关系,采用依赖,聚合,组合等关系代替继承。
里氏替换原则是实现开闭原则的重要方式之一,由于使用基类对象的地方都可以使用子类对象,因此在程序中尽量使用基类类型来对对象进行定义,而在运行时再确定其子类类型,用子类对象来替换父类对象。
作用:
避免系统继承体系被破坏。
举例说明继承的风险
https://www.cnblogs.com/pony1223/p/7594803.html
我们需要完成一个两数相减的功能,由类A来负责。
class A{
public int func1(int a, int b){
return a-b;
}
}
public class Client{
public static void main(String[] args){
A a = new A();
System.out.println("100-50="+a.func1(100, 50));
System.out.println("100-80="+a.func1(100, 80));
}
}
运行结果:
100-50=50
100-80=20
后来,我们需要增加一个新的功能:完成两数相加,然后再与100求和,由类B来负责。即类B需要完成两个功能:
两数相减。
两数相加,然后再加100。
由于类A已经实现了第一个功能【两数相减】,所以类B继承类A后,只需要再完成第二个功能【两数相加,然后再加100】就可以了,代码如下:
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
public class Client{
public static void main(String[] args){
B b = new B();
System.out.println("100-50="+b.func1(100, 50));
System.out.println("100-80="+b.func1(100, 80));
System.out.println("100+20+100="+b.func2(100, 20));
}
}
类B完成后,运行结果:
100-50=150
100-80=180
100+20+100=220
我们发现原本运行正常的相减功能发生了错误。原因就是类B在给方法起名时无意中重写了父类的方法,造成所有运行相减功能的代码全部调用了类B重写后的方法,造成原本运行正常的功能出现了错误。在本例中,引用基类A完成的功能,换成子类B之后,发生了异常。在实际编程中,我们常常会通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的几率非常大。如果非要重写父类的方法,比较通用的做法是:原来的父类和子类都继承一个更通俗的基类,原有的继承关系去掉,采用依赖、聚合,组合等关系代替。看上去很不可思议,因为我们会发现在自己编程中常常会违反里氏替换原则,程序照样跑的好好的。所以大家都会产生这样的疑问,假如我非要不遵循里氏替换原则会有什么后果?
后果就是:你写的代码出问题的几率将会大大增加。
依赖倒置原则(Dependency Inversion Principle, DIP)
定义:
高层模块不应该依赖低层模块,它们都应该依赖抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
分析:
代码要依赖于抽象的类,而不要依赖于具体的类;要面向接口或抽象类编程,而不是面向具体类编程。
通过面向接口编程,使用接口或者抽象类制定好规范和契约,而不去涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成。
作用:
避免需求变化导致过多的维护工作。
注意:
依赖注入,就是将一个类的对象传入另一个类,注入时应该尽量注入父类对象,而在程序运行时再通过子类对象来覆盖父类对象。
继承时遵循里氏替换原则。
依赖倒置原则应用实例
疫情期间,全国各大城市开启网购促销活动
实例中用到“顾客类”,“促销产品类”
顾客类
public class Customer {
public void shopping(WuhanSellGoods goods) {
// 购物
System.out.println(goods.sell());
}
}
这样设计的缺陷是,过几天云南也搞促销活动,顾客类里面的代码要改动
public class Customer {
public void shopping(YunnanSellGoods goods) {
// 购物
System.out.println(goods.sell());
}
}
可想而知,后面全国各省市都搞促销活动,那岂不是每个都要改,改来改去,还容易出错。解决方法,定义单独的促销产品接口SellGoods,各地促销产品类实现这个接口。
public interface SellGoods {
public String sell();
}
public Class WuhanSellGoods implements SellGoods {
public String sell() {
return “武汉促销产品:电器、木耳、热干面...”;
}
}
public Class YunnanSellGoods implements SellGoods {
public String sell() {
return “云南促销产品:菠萝、椰子、木瓜、芒果、香蕉...”;
}
}
public class Customer {
public void shopping(SellGoods goods) {
// 购物
System.out.println(goods.sell());
}
}单一职责原则(Single Responsibility Principle, SRP)
定义:
类的职责要单一,一个类只负责一项职责。
分析:
一个类(或者大到模块,小到方法)承担的职责越多,它被复用的可能性越小,而且如果一个类承担的职责过多,就相当于将这些职责耦合在一起,当其中一个职责变化时,可能会影响其他职责的运作。
作用:
降低代码复杂度、系统解耦合、提高可读性。
注意:
通常情况下,我们应当遵守单一职责原则。只有逻辑足够简单,才可以在代码级别上违反单一职责原则;只有类中方法数量足够少,才可以在方法级别上违反单一职责原则。
说白了就是你写个屁大点的工具类或者方法,平时也就自己用,怎么简单快速怎么来就可以了。如果你真的是时间充裕,那你可以按标准原则来,但程序员一般手里的任务都偏重,天天加班都做不完。不要过于追求完美不出问题,所有细节内容都能预见,不可能的,你全身的毛发都掉光都不可能达到完美!微软、苹果、Linux等大厂的系统照样每月发布更新补丁!
接口隔离原则(Interface Segregation Principle, ISP)
定义:
客户端不应该依赖那些它不需要的接口。 一旦一个接口太大,则需要将它分割成一些更细小的接口,使用该接口的客户端仅需知道与之相关的方法即可。
一个接口把自己该做的事情做好,不该做的事情尽可能不要做,建议开设新的接口做对应的事情。
分析:
接口隔离原则是指使用多个专门的接口,而不使用单一的总接口。每一个接口应该承担一种相对独立的角色,不多不少,不干不该干的事,该干的事都要干。各个接口“少依赖,低耦合”。
一个接口就只代表一个角色,每个角色都有它特定的一个接口,此时这个原则可以叫做“角色隔离原则”。
接口仅仅提供客户端需要的行为,即所需的方法,客户端不需要的行为则隐藏起来,应当为客户端提供尽可能小的单独的接口,而不要提供大的总接口。
使用接口隔离原则拆分接口时,首先必须满足单一职责原则,将一组相关的操作定义在一个接口中,且在满足高内聚的前提下,接口中的方法越少越好。
可以在进行系统设计时采用定制服务的方式,即为不同的客户端提供宽窄不同的接口,只提供用户需要的行为,而隐藏用户不需要的行为。
作用:
避免接口过于臃肿职责不单一。
接口隔离原则应用实例
public interface Mobile {
public void call();//手机可以打电话
public void sendMessage();//手机可以发短信
public void playBird();//手机可以玩愤怒的小鸟?
}
上面第三个行为明显就不是一个手机应该有的,或者说不是一个手机必须有的,那么上面这个手机的接口就不是最小接口,假设我现在的非智能手机去实现这个接口,那么playBird方法就只能空着了,因为它不能玩。
所以我们更好的做法是去掉这个方法,让Mobile接口最小化,然后再建立下面这个接口去扩展现有的Mobile接口。
public interface SmartPhone extends Mobile{
public void playBird();//智能手机的接口就可以加入这个方法了
}
这样两个接口就都是最小化的了,这样我们的非智能手机就去实现Mobile接口,实现打电话和发短信的功能,而智能手机就实现SmartPhone接口,实现打电话、发短信以及玩愤怒的小鸟的功能,两者都不会有多余的要实现的方法。
最小接口原则一般我们是要尽量满足的,如果实在有多余的方法,我们也有补救的办法,而且有的时候也确实不可避免的有一些实现类无法全部实现接口中的方法,这时候缺省适配器模式就能起到作用了。迪米特法则(Law of Demeter, LoD)
定义:
只与你的直接朋友交谈,不跟“陌生人”说话(Talk only to your immediate friends and not to strangers)。其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的“朋友”是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
优缺点:
迪米特法则要求限制软件实体之间通信的宽度和深度,正确使用迪米特法则将有以下两个优点:(降低藕合,提高复用性、扩展性)
降低了类之间的耦合度,提高了模块的相对独立性。
由于亲合度降低,从而提高了类的可复用率和系统的扩展性。
但是,过度使用迪米特法则会使系统产生大量的中介类,从而增加系统的复杂性,使模块之间的通信效率降低。所以,在釆用迪米特法则时需要反复权衡,确保高内聚和低耦合的同时,保证系统的结构清晰。
实现方法:
从迪米特法则的定义和特点可知,它强调以下两点:
从依赖者的角度来说,只依赖应该依赖的对象。
从被依赖者的角度说,只暴露应该暴露的方法。
所以,在运用迪米特法则时要注意以下 6 点。
在类的划分上,应该创建弱耦合的类。类与类之间的耦合越弱,就越有利于实现可复用的目标。
在类的结构设计上,尽量降低类成员的访问权限。
在类的设计上,优先考虑将一个类设置成不变类。
在对其他类的引用上,将引用其他对象的次数降到最低。
不暴露类的属性成员,而应该提供相应的访问器(set 和 get 方法)。
谨慎使用序列化(Serializable)功能。
迪米特法则应用实例
明星与经纪人的关系
分析:明星由于全身心投入艺术,所以许多日常事务由经纪人负责处理,如与粉丝的见面会,与媒体公司的业务洽淡等。这里的经纪人是明星的朋友,而粉丝和媒体公司是陌生人,所以适合使用迪米特法则。
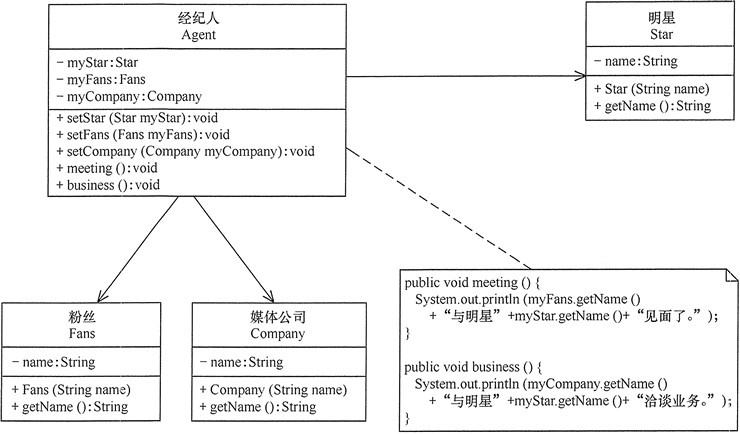 public class LoDtest {
public class LoDtest {
public class LoDtest {
public static void main(String[] args) {
Agent agent=new Agent();
agent.setStar(new Star("林心如"));
agent.setFans(new Fans("粉丝韩丞"));
agent.setCompany(new Company("中国传媒有限公司"));
agent.meeting();
agent.business();
}
}
//经纪人
class Agent {
private Star myStar;
private Fans myFans;
private Company myCompany;
public void setStar(Star myStar) {
this.myStar=myStar;
}
public void setFans(Fans myFans) {
this.myFans=myFans;
}
public void setCompany(Company myCompany) {
this.myCompany=myCompany;
}
public void meeting() {
System.out.println(myFans.getName()+"与明星"+myStar.getName()+"见面了。");
}
public void business() {
System.out.println(myCompany.getName()+"与明星"+myStar.getName()+"洽淡业务。");
}
}
//明星
class Star {
private String name;
Star(String name) {
this.name=name;
}
public String getName() {
return name;
}
}
//粉丝
class Fans {
private String name;
Fans(String name) {
this.name=name;
}
public String getName() {
return name;
}
}
//媒体公司
class Company {
private String name;
Company(String name) {
this.name=name;
}
public String getName() {
return name;
}
}合成复用原则(Composite Reuse Principle, CRP)
定义:
在软件复用时,要尽量先使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现。
如果要使用继承关系,则必须严格遵循里氏替换原则。合成复用原则同里氏替换原则相辅相成的,两者都是开闭原则的具体实现规范。
分析:
合成复用原则就是指在一个新的对象里通过关联关系(包括组合关系和聚合关系)来使用一些已有的对象,使之成为新对象的一部分;新对象通过委派调用已有对象的方法达到复用其已有功能的目的。简言之:要尽量使用组合/聚合关系,少用继承。
在面向对象设计中,可以通过两种基本方法在不同的环境中复用已有的设计和实现,即通过组合/聚合关系或通过继承。
组合/聚合可以使系统更加灵活,类与类之间的耦合度降低,一个类的变化对其他类造成的影响相对较少,因此一般首选使用组合/聚合来实现复用;其次才考虑继承,在使用继承时,需要严格遵循里氏替换原则,有效使用继承会有助于对问题的理解,降低复杂度,而滥用继承反而会增加系统构建和维护的难度以及系统的复杂度,因此需要慎重使用继承复用。
目的:
防止类的体系庞大。
合成复用原则应用实例
汽车分类管理
分析:汽车按“动力源”划分可分为汽油汽车、电动汽车等;按“颜色”划分可分为白色汽车、黑色汽车和红色汽车等。如果同时考虑这两种分类,其组合就很多。
用继承关系实现的汽车分类的类图
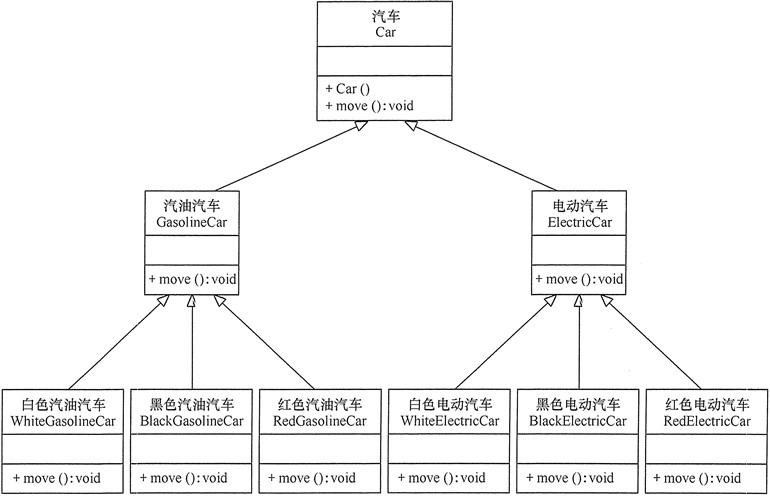
可以看出用继承关系实现会产生很多子类,而且增加新的“动力源”或者增加新的“颜色”都要修改源代码,这违背了开闭原则,显然不可取。但如果改用组合关系实现就能很好地解决以上问题。
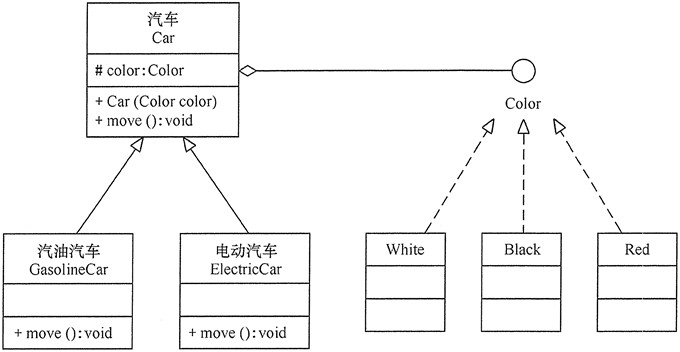 |
|
总结
七种设计原则是软件设计模式必须尽量遵循的原则,各种原则要求的侧重点不同。
开闭原则**[绝对的大姐大,其他姐妹心甘情愿臣服]**是总纲,它告诉我们要对扩展开放,对修改关闭。
里氏替换原则**[缺爱的妹子,渴望亲情]**告诉我们子类新加的方法,先要确认是否会覆盖父类的方法,否则会造成方法调用错误。
依赖倒置原则**[小鸟依人的软萌妹子,依赖接口和抽象类两位欧巴]**告诉我们要面向接口或抽象类编程。
单一职责原则**[清纯女孩,心思单纯]告诉我们实现类**要职责单一,不该管别管,别胡乱实现一大堆繁杂的业务功能。
接口隔离原则**[cool girl,高冷话少]**告诉我们接口设计要精简单一。
迪米特法则**[娇羞的妹子,不爱和陌生人说话]**告诉我们要降低类之间的耦合度,小权限、管修改。
合成复用原则**[交际花,喜欢搞聚会,不喜欢认干爹]**告诉我们要优先使用聚合或组合关系复用,少用继承关系复用。
创建型模式(5)
★单例(Singleton)模式
定义(什么是/是什么)
一个类只有一个实例,并且提供一个全局访问点。
作用目的(为什么用)
在工作过程中,接触几次单例模式之后,会发现所有可以使用单例模式的类都有一个共性,那就是这个类没有自己的状态,换句话说,这些类无论你实例化多少个,其实都是一样的,而且更重要的一点是,这个类如果有两个或者两个以上的实例的话,程序运行竟然会产生不可预知的错误或者与现实相违背的逻辑错误。
这样的话,如果我们不将这个类控制成单例的结构,应用中就会存在很多一模一样的类实例,这会非常浪费系统的内存资源,而且容易导致错误甚至一定会产生错误,所以我们单例模式所期待的目标或者说使用它的目的,是为了尽可能的节约内存空间,减少无谓的GC消耗,并且使应用可以正常运作。
总结一下,一般一个类能否做成单例,最容易区别的地方就在于,这些类,在应用中如果有两个或者两个以上的实例会引起错误,又或者换句话说,就是这些类,在整个应用中,同一时刻,有且只能有一种状态。
应用场景
应用程序配置资源,全局只需要一个的配置。
类的对象频繁创建和销毁,比较浪费性能,可以用单例模式优化性能,如数工具类、据库连接池、多线程线程池、网络连接池等。
实现方式
单例模式的八种实现方式
饿汉式(静态常量,内存浪费)
饿汉式(静态代码块,内存浪费)
懒汉式(线程不安全)
懒汉式(线程安全,同步方法,效率低)
懒汉式(线程安全,同步代码块)
★DCL双重检查锁(JVM内存可见性volatile问题)
★静态内部类
★枚举(反射对枚举不管用,其他方式反射能创建对象)
其实本质上只有饿汉式、懒汉式、静态内部类和枚举四种方式,其他几种无非就是加了点线程同步措施,实际开发肯定是选择最不会出问题并且效率性能最好的方式。
饿汉式(静态常量)
实现步骤:
构造器私有化(防止new创建对象)
类的内部创建类的私有静态实例常量(private static final)
向外提供一个静态公共方法getInstance()获取实例对象
public class HungrySingleton {
private HungrySingleton(){}
private static final HungrySingleton instance = new HungrySingleton();
public static HungrySingleton getInstance() {
return instance;
}
}优点:
写法简单,在类装载的时候就完成了实例化,避免了线程同步的问题。
缺点:
在类装载的时候就完成了实例化,没有达到lazy load懒加载的效果,如果这个实例一直都没被使用,则会造成内存浪费问题。
结论:
如果确定单例对象肯定会用到,也就是不会造成内存浪费,可以使用这种方式,写法简单,也不用进行线程同步控制。
饿汉式(静态代码块)
public class HungrySingleton {
private HungrySingleton(){}
private static HungrySingleton instance;
static {
Instance = new HungrySingleton();
}
public static HungrySingleton getInstance() {
return instance;
}
}优缺点和结论跟饿汉式(静态常量)一样。
懒汉式(线程不安全)
public class LazySingleton {
private LazySingleton(){}
private static LazySingleton instance;
public static LazySingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
}优点:懒加载,用到的时候才创建实例。
缺点:线程不安全,多线程环境下,if (instance == null)判断会出现多个实例的情况。结论:在实际开发中,不要用这种方式。
懒汉式(线程安全,同步方法,效率低)
public class LazySingleton {
private LazySingleton(){}
private static LazySingleton instance;
public static synchronized LazySingleton getInstance() {
if(instance == null) {
instance=new LazySingleton();
}
return instance;
}
}优点:解决了线程安全问题。
缺点:效率较低,每个线程获取实例的时候,都会进行同步,其实实例化代码只要执行一次之后,后面的线程直接返回实例对象即可,所有线程不管实例对象有没有被创建,都进行同步,效率较低。
结论:实际开发中,不推荐这种方式。
懒汉式(线程安全,同步代码块)
public class LazySingleton {
private LazySingleton(){}
private static LazySingleton instance;
public static LazySingleton getInstance() {
if (instance == null) {
synchronized (LazySingleton.class) {
instance = new LazySingleton();
}
}
return instance;
}
}优点:同步代码块是对同步方法进行了改进,效率提高了。
缺点:多线程不安全,多线程执行到if (instance == null)判断时,依然会出现创建多个实例的问题。
结论:实际开发中,不要用这种方式。
★DCL双重检查锁(JVM内存可见性volatile[välədl]问题)
public class LazySingleton {
private LazySingleton(){}
private static volatile LazySingleton instance; // 如果不加volatile可能出现指令重排,导致半实例化问题
public static LazySingleton getInstance() {
if (instance == null) {
synchronized (LazySingleton.class) {
if (instance == null) {
instance = new LazySingleton(); // 注意半实例化问题
}
}
}
return instance;
}
}优点:
进行了两次if (instance == null),保证了多线程安全。
使用了volatile关键字修饰变量,保证JVM不优化语句,变量内存可见性一致。
缺点:
volatile关键字是作用在JVM层面的,不太好理解。
结论:
实际开发中,不考虑安全性,推荐使用这种方式,既能达到懒加载效果,也能保证线程安全。
volatile 使用补充
貌似双重加锁的示例看起来是没有问题了,但如果再进一步深入考虑的话,其实仍然是有问题的。
如果我们深入到JVM中去探索上面这段代码,它就有可能(注意,只是有可能)是有问题的。
因为虚拟机在执行创建实例的这一步操作的时候,其实是分了好几步去进行的,也就是说创建一个新的对象并非是原子性操作。在有些JVM中上述做法是没有问题的,但是有些情况下是会造成莫名的错误。
首先要明白在JVM创建新的对象时,主要要经过三步。
分配内存
初始化构造器
将对象指向分配的内存的地址
这种顺序在上述双重加锁的方式是没有问题的,因为这种情况下JVM是完成了整个对象的构造才将内存的地址交给了对象。但是如果2和3步骤是相反的(2和3可能是相反的是因为JVM会针对字节码进行调优,而其中的一项调优便是调整指令的执行顺序),就会出现问题了。
因为这时将会先将内存地址赋给对象,针对上述的双重加锁,就是说先将分配好的内存地址指给instance,然后再进行初始化构造器,这时候后面的线程去请求getInstance方法时,会认为instance对象已经实例化了,直接返回一个引用。如果在初始化构造器之前,这个线程使用了instance,就会产生莫名的错误。
静态的实例属性加上关键字volatile,标识这个属性是不需要优化的。
这样也不会出现实例化发生一半的情况,因为加入了volatile关键字,就等于禁止了JVM自动的指令重排序优化,并且强行保证线程中对变量所做的任何写入操作对其他线程都是即时可见的。
★静态内部类
public class Singleton {
private Singleton() {}
public static Singleton getInstance() {
return SingletonInstance.INSTANCE;
}
private static class SingletonInstance {
private static final Singleton INSTANCE= new Singleton();
}
}通过静态内部类的方式实现单例模式是线程安全的,同时静态内部类不会在Singleton类加载时就加载,而是在调用getInstance()方法时才进行加载,达到了懒加载的效果。
优点:
线程安全;延迟加载。
缺点:
依然可能通过反射或者反序列化创建实例对象。
public static void main(String[] args) throws Exception {
Singleton singleton = Singleton.getInstance();
Constructor<Singleton> constructor = Singleton.class.getDeclaredConstructor();
constructor.setAccessible(true);
Singleton newSingleton = constructor.newInstance();
System.out.println(singleton == newSingleton); // false
}
public class Singleton implements Serializable {
private static class SingletonHolder {
private static Singleton instance = new Singleton();
}
private Singleton() {
}
public static Singleton getInstance() {
return SingletonHolder.instance;
}
public static void main(String[] args) {
Singleton instance = Singleton.getInstance();
byte[] serialize = SerializationUtils.serialize(instance);
Singleton newInstance = SerializationUtils.deserialize(serialize);
System.out.println(instance == newInstance); // false
}
}结论:
不考虑安全性,推荐使用。
★枚举
public enum Singleton {
INSTANCE;
public void doSomething() {
System.out.println("doSomething");
}
}
public class Main {
public static void main(String[] args) {
Singleton.INSTANCE.doSomething();
}
}优点:不仅能避免线程安全问题,还能防止反射、反序列化创建对象。
结论:
推荐使用。直接通过Singleton.INSTANCE.doSomething()的方式调用即可。方便、简洁又安全。
为什么能防止反射创建实例?
JDK反射机制内部完全禁止了用反射创建枚举实例的可能性。
同样,JDK内部也对枚举反序列化进行了防护。
应用实例
- HttpClient
- 数据库连接池
应用扩展
单例模式可扩展为有限的多例(Multitcm)模式,这种模式可生成有限个实例并保存在 ArmyList 中,需要时可随机获取。
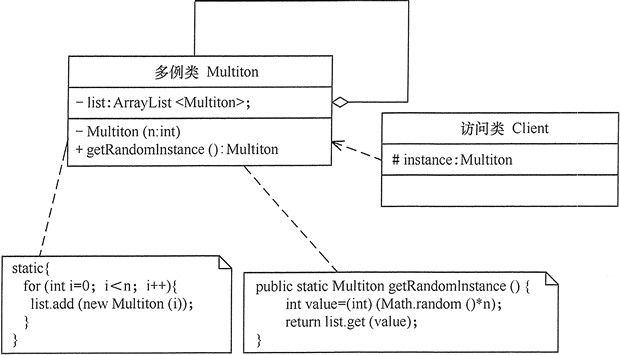
缺陷问题及规避方案
相关补充
★工厂方法(Factory Method)模式
定义(什么是/是什么)
**定义一个创建产品对象的工厂接口,将实际创建工作推迟到子类当中。**核心工厂类不再负责产品的创建,这样核心类成为一个抽象工厂角色,仅负责具体工厂子类必须实现的接口,这样进一步抽象化的好处是使得工厂方法模式可以使系统在不修改具体工厂角色的情况下引进新的产品。
我们把被创建的对象称为“产品”,把创建产品的对象称为“工厂”。如果要创建的产品不多,只要一个工厂类就可以完成,这种模式叫“简单工厂模式”,它不属于 GoF 的 23 种经典设计模式,它的缺点是增加新产品时会违背“开闭原则”。
作用目的(为什么用)
优点:
用户只需要知道具体工厂的名称就可得到所要的产品,无须知道产品的具体创建过程。
在系统增加新的产品时只需要添加具体产品类和对应的具体工厂类,无须对原工厂进行任何修改,满足开闭原则。
缺点:
每增加一个产品就要增加一个具体产品类和一个对应的具体工厂类,这增加了系统的复杂度。
假设产品数量巨多,而且需要我们亲手去逐个实现的时候,工厂方法模式就会增加系统的复杂性,到处都是工厂类和产品类,而且这里所说的工厂类和产品类只是概念上的,真正的产品可能不是一两个类就能搞定。
应用场景
我们需要一个产品帮我们完成一项任务,但是这个产品有可能有很多品牌(像这里的mysql,oracle),为了保持我们对产品操作的一致性,我们就可能要用到工厂方法模式。
工厂方法模式通常适用于以下场景:
客户只知道创建产品的工厂名,而不知道具体的产品名。如 TCL 电视工厂、海信电视工厂等。
创建对象的任务由多个具体子工厂中的某一个完成,而抽象工厂只提供创建产品的接口。
客户不关心创建产品的细节,只关心产品的品牌。
实现方式
模式的结构
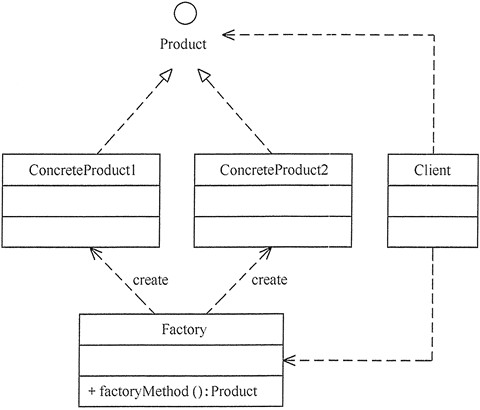
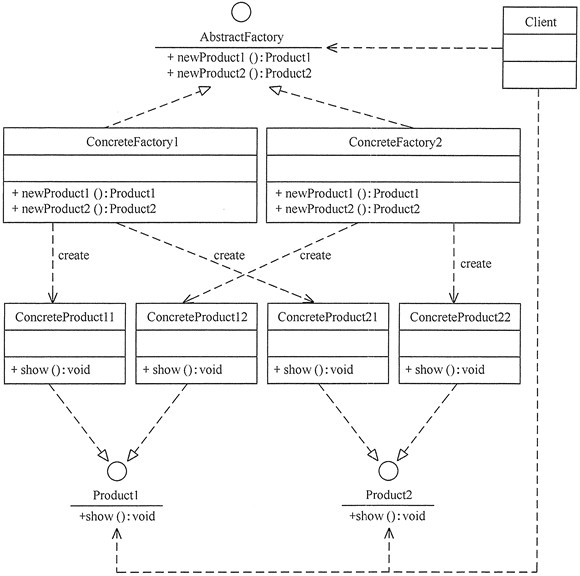
工厂方法模式的主要角色如下:
抽象工厂(Abstract Factory):提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法 newProduct() 来创建产品。
具体工厂(ConcreteFactory):主要是实现抽象工厂中的抽象方法,完成具体产品的创建。
抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能。
具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间一一对应。
工厂方法模式的结构图:
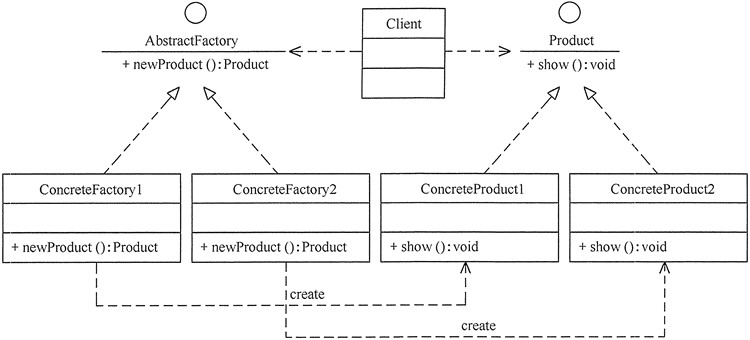
多个工厂生产多个产品,一个工厂生产一类产品,1对1。
模式的实现
public class AbstractFactoryTest {
public static void main(String[] args) {
try {
Product a;
AbstractFactory af;
// 现在都是读取配置文件配置项了
af=(AbstractFactory) ReadXML1.getObject();
a=af.newProduct();
a.show();
}
catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
//抽象产品:提供了产品的接口
interface Product {
public void show();
}
//具体产品1:实现抽象产品中的抽象方法
class ConcreteProduct1 implements Product {
public void show() {
System.out.println("具体产品1显示...");
}
}
//具体产品2:实现抽象产品中的抽象方法
class ConcreteProduct2 implements Product {
public void show() {
System.out.println("具体产品2显示...");
}
}
//抽象工厂:提供了厂品的生成方法
interface AbstractFactory {
public Product newProduct();
}
//具体工厂1:实现了厂品的生成方法
class ConcreteFactory1 implements AbstractFactory {
public Product newProduct() {
System.out.println("具体工厂1生成-->具体产品1...");
return new ConcreteProduct1();
}
}
//具体工厂2:实现了厂品的生成方法
class ConcreteFactory2 implements AbstractFactory {
public Product newProduct() {
System.out.println("具体工厂2生成-->具体产品2...");
return new ConcreteProduct2();
}
}
import javax.xml.parsers.*;
import org.w3c.dom.*;
import java.io.*;
class ReadXML1 {
//该方法用于从XML配置文件中提取具体类类名,并返回一个实例对象
public static Object getObject() {
try {
//创建文档对象
DocumentBuilderFactory dFactory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=dFactory.newDocumentBuilder();
Document doc;
doc=builder.parse(new File("src/FactoryMethod/config1.xml"));
//获取包含类名的文本节点
NodeList nl=doc.getElementsByTagName("className");
Node classNode=nl.item(0).getFirstChild();
String cName="FactoryMethod."+classNode.getNodeValue();
//System.out.println("新类名:"+cName);
//通过类名生成实例对象并将其返回
Class<?> c=Class.forName(cName);
Object obj=c.newInstance();
return obj;
} catch(Exception e) {
e.printStackTrace();
return null;
}
}
}应用实例

应用扩展
当需要生成的产品不多且不会增加,一个具体工厂类就可以完成任务时,可删除抽象工厂类。这时工厂方法模式将退化到简单工厂模式。
缺陷问题及规避方案
相关补充
简单(静态)工厂模式
定义
只有一个工厂,生产多种产品。
在工厂类中,根据识别标识判断,返回对应的产品。
优缺点
优点:业务逻辑简单,不用写过多地工厂类和产品类。
缺点:不符合开闭原则,新增一个产品,需要改动工厂生产方法。
应用场景
互联网金融-资金支付通道。支付业务接口,对应各个银行或金融机构的具体业务实现。
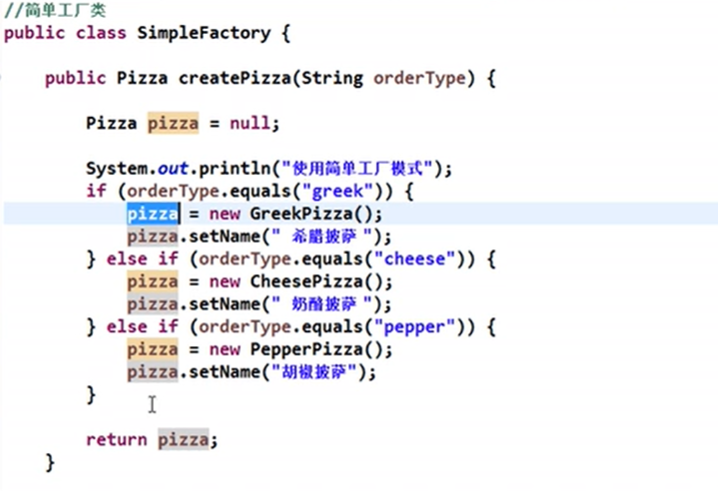
实现方式
public class Creator {
private Creator(){}
public static IProduct createProduct(String productName){
if (productName == null) {
return null;
}
if (productName.equals("A")) {
return new ProductA();
}else if (productName.equals("B")) {
return new ProductB();
}else {
return null;
}
}
}应用实例
Calendar日历类,使用了简单工厂模式
订购披萨
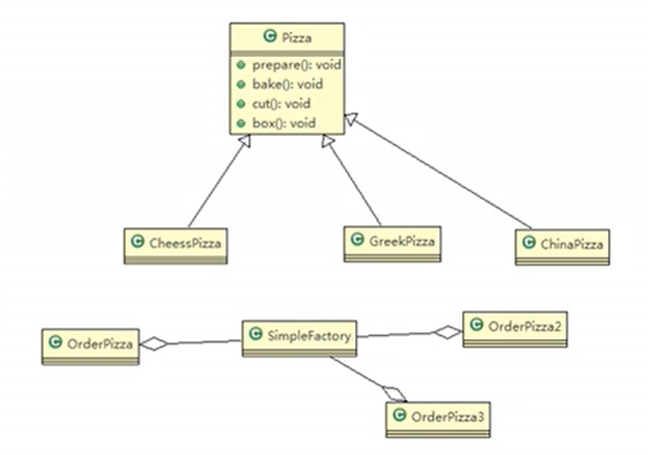
后续新增其他披萨订购,只需要新建披萨类和修改简单工厂类即可,披萨订购类不用改动。
抽象工厂(AbstractFactory)模式
定义(什么是/是什么)
一种为访问类提供一个创建一组相关或相互依赖对象的接口,且访问类无须指定所要产品的具体类就能得到同族的不同等级的产品的模式结构。
有多个工厂,且每个工厂可以生产多类产品。
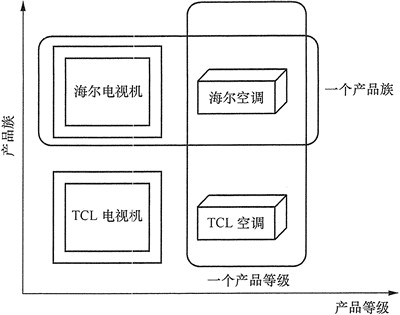
抽象工厂模式是工厂方法模式的升级版本,工厂方法模式只生产一种产品,而抽象工厂模式可生产多种产品。通俗地讲,工厂方法模式只生产一个品牌一个系列的产品,比如小米手机工厂只生产手机,小米电脑工厂只生产电脑;抽象工厂模式则生产一个品牌下所有系列的产品,比如小米生态链工厂,生产厨具、空调、平衡车、电池等等。
工厂方法模式中考虑的是一类产品的生产,如畜牧场只养动物、电视机厂只生产电视机、计算机软件学院只培养计算机软件专业的学生等。
同种类称为同等级,也就是说:工厂方法模式只考虑生产同等级的产品,但是在现实生活中许多工厂是综合型的工厂,能生产多等级(种类) 的产品,如农场里既养动物又种植物,电器厂既生产电视机又生产洗衣机或空调,大学既有软件专业又有生物专业等。
抽象工厂模式将考虑多等级产品的生产,将同一个具体工厂所生产的位于不同等级的一组产品称为一个产品族。
海尔工厂和 TCL 工厂所生产的电视机与空调对应的关系图:
作用目的(为什么用)
应用场景
抽象工厂模式通常适用于以下场景:
当需要创建的对象是一系列相互关联或相互依赖的产品族时,如电器工厂中的电视机、洗衣机、空调等。
系统中有多个产品族,但每次只使用其中的某一族产品。如有人只喜欢穿某一个品牌的衣服和鞋。
系统中提供了产品的类库,且所有产品的接口相同,客户端不依赖产品实例的创建细节和内部结构。
实现方式
模式的结构
抽象工厂(Abstract Factory):提供了创建产品的接口,它包含多个创建产品的方法 newProduct(),可以创建多个不同等级的产品。
具体工厂(Concrete Factory):主要是实现抽象工厂中的多个抽象方法,完成具体产品的创建。
抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能,抽象工厂模式有多个抽象产品。
具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它与具体工厂之间是多对一的关系。
模式的实现
应用实例
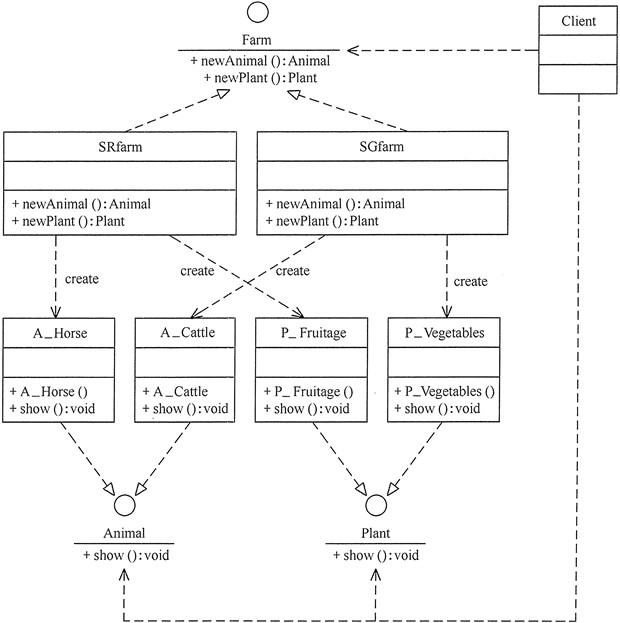
用抽象工厂模式设计农场类
分析:农场中除了像畜牧场一样可以养动物,还可以培养植物,如养马、养牛、种菜、种水果等,所以本实例比前面介绍的畜牧场类复杂,必须用抽象工厂模式来实现。
应用扩展
抽象工厂模式的扩展有一定的“开闭原则”倾斜性:
当增加一个新的产品族时(比如,新开一个小米手机工厂),只需增加一个新的具体工厂,不需要修改原代码,满足开闭原则。
当产品族中需要增加一个新种类的产品时(比如,小米又要生产无人机了),则所有的工厂类都需要进行修改,不满足开闭原则。
另一方面,当系统中只存在一个等级结构的产品时,抽象工厂模式将退化到工厂方法模式。
缺陷问题及规避方案
相关补充
原型(Prototype)模式
定义(什么是/是什么)
原型模式就是对象拷贝,用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型相同或相似的新对象。
作用目的(为什么用)
应用场景
原型模式通常适用于以下场景:
对象之间相同或相似,即只是个别的几个属性不同的时候。
对象的创建过程比较麻烦,但复制比较简单的时候。
一个对象需要被多处使用,但又不能改变原始对象数据的时候。
实现方式
模式的结构
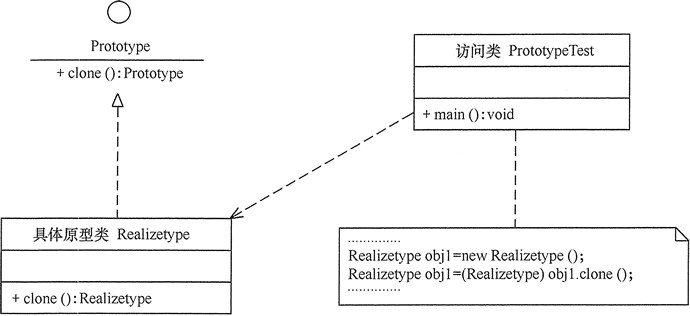
原型模式包含以下主要角色:
抽象原型类:规定了具体原型对象必须实现的接口。
具体原型类:实现抽象原型类的 clone() 方法,它是可被复制的对象。
访问类:使用具体原型类中的 clone() 方法来复制新的对象。
应用实例
Spring中原型bean(scope=”prototype”)的创建,使用了原型模式。
应用扩展
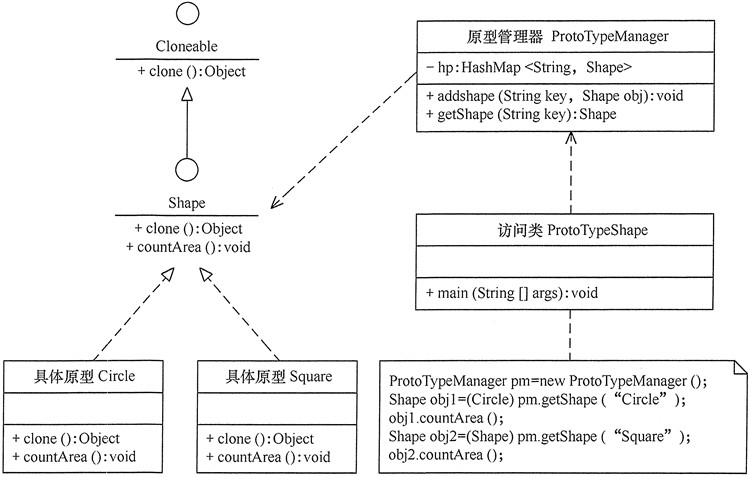
原型模式可扩展为带原型管理器的原型模式,它在原型模式的基础上增加了一个原型管理器 PrototypeManager 类。该类用 HashMap 保存多个复制的原型,Client 类可以通过管理器的 get(String id) 方法从中获取复制的原型。
例如:用带原型管理器的原型模式来生成包含“圆”和“正方形”等图形的原型,并计算其面积。分析:本实例中由于存在不同的图形类,例如,“圆”和“正方形”,它们计算面积的方法不一样,所以需要用一个原型管理器来管理它们。
缺陷问题及规避方案
相关补充
建造者(Builder)模式
定义(什么是/是什么)
将一个复杂对象分解成多个相对简单的部分,然后根据不同需要分别创建它们,最后构建成该复杂对象。
作用目的(为什么用)
应用场景
建造者(Builder)模式创建的是复杂对象,其产品的各个部分经常面临着剧烈的变化,但将它们组合在一起的算法却相对稳定,所以它通常在以下场合使用:
创建的对象较复杂,由多个部件构成,各部件面临着复杂的变化,但构件间的建造顺序是稳定的。
创建复杂对象的算法独立于该对象的组成部分以及它们的装配方式,即产品的构建过程和最终的表示是独立的。
具体的场景:
组装电脑
房屋装修
实现方式
模式的结构
建造者(Builder)模式的主要角色:
产品角色(Product):它是包含多个组成部件的复杂对象,由具体建造者来创建其各个零部件。
抽象建造者(Builder):它是一个包含创建产品各个子部件的抽象方法的接口,通常还包含一个返回复杂产品的方法 getResult()。
具体建造者(Concrete Builder):实现 Builder 接口,完成复杂产品的各个部件的具体创建方法。
指挥者(Director):它调用建造者对象中的部件构造与装配方法完成复杂对象的创建,在指挥者中不涉及具体产品的信息。

模式的实现
// 产品角色:包含多个组成部件的复杂对象
class Product
{
private String partA;
private String partB;
private String partC;
public void setPartA(String partA)
{
this.partA=partA;
}
public void setPartB(String partB)
{
this.partB=partB;
}
public void setPartC(String partC)
{
this.partC=partC;
}
public void show()
{
//显示产品的特性
}
}
// 抽象建造者:包含创建产品各个子部件的抽象方法
abstract class Builder
{
//创建产品对象
protected Product product=new Product();
public abstract void buildPartA();
public abstract void buildPartB();
public abstract void buildPartC();
//返回产品对象
public Product getResult()
{
return product;
}
}
// 具体建造者:实现了抽象建造者接口
public class ConcreteBuilder extends Builder
{
public void buildPartA()
{
product.setPartA("建造 PartA");
}
public void buildPartB()
{
product.setPartA("建造 PartB");
}
public void buildPartC()
{
product.setPartA("建造 PartC");
}
}
// 指挥者:调用建造者中的方法完成复杂对象的创建
class Director
{
private Builder builder;
public Director(Builder builder)
{
this.builder=builder;
}
//产品构建与组装方法
public Product construct()
{
builder.buildPartA();
builder.buildPartB();
builder.buildPartC();
return builder.getResult();
}
}
// 客户类
public class Client
{
public static void main(String[] args)
{
Builder builder=new ConcreteBuilder();
Director director=new Director(builder);
Product product=director.construct();
product.show();
}
}应用实例
JDK StringBuilder使用了建造者模式。
盖房子:搭框架、砌墙、刷墙、装修、置办家电…
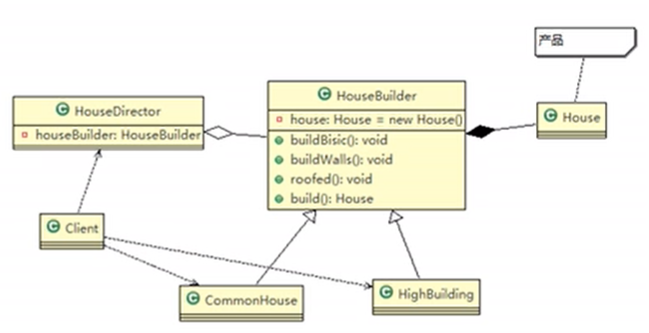
应用扩展
建造者(Builder)模式在应用过程中可以根据需要改变,如果创建的产品种类只有一种,只需要一个具体建造者,这时可以省略掉抽象建造者,甚至可以省略掉指挥者角色。
缺陷问题及规避方案
相关补充
结构型模式(7)
★代理(Proxy)模式
定义(什么是/是什么)
由于某些原因需要给某对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。
聚合原有类,实现新接口。
在有些情况下,一个客户不能或者不想直接访问另一个对象,这时需要找一个中介帮忙完成某项任务,这个中介就是代理对象。例如,购买火车票不一定要去火车站买,可以通过 12306 网站或者去火车票代售点买。又如找女朋友、找保姆、找工作等都可以通过找中介完成。
代理模式有不同的形式,主要分为静态代理、动态代理(又叫JDK代理、接口代理)和Cglib代理(可以在内存中动态创建对象,而不需要实现接口,也可以归为动态代理的范畴)。
作用目的(为什么用)
优点:
代理模式在客户端与目标对象之间起到一个中介作用和保护目标对象的作用。
代理对象可以扩展目标对象的功能。
代理模式能将客户端与目标对象分离,在一定程度上降低了系统的耦合度。
缺点:
在客户端和目标对象之间增加一个代理对象,会造成请求处理速度变慢。
增加了系统的复杂度。
应用场景
实现方式
模式的结构
代理模式的主要角色如下:
抽象主题(Subject)类:通过接口或抽象类声明真实主题和代理对象实现的业务方法。
真实主题(Real Subject)类:实现了抽象主题中的具体业务,是代理对象所代表的真实对象,是最终要引用的对象。
代理(Proxy)类:提供了与真实主题相同的接口,其内部含有对真实主题的引用,它可以访问、控制或扩展真实主题的功能。
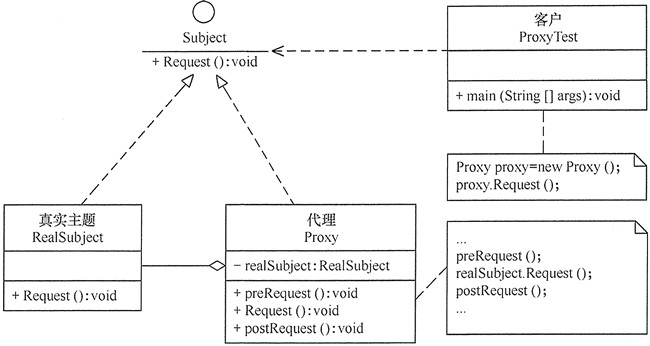
模式的实现
静态代理
具体类和代理类都需要实现上层接口或抽象类。
因此,一旦上层接口/抽象类新增方法,具体类和代理类都需要改动,不符合开闭原则。
动态代理
只有具体类需要要实现上层接口或抽象类,代理类不需要。
代理类通过反射机制,使用java.lang.reflect.Proxy中的newProxyInstance()方法动态创建具体类对象,并执行方法。
Cglib代理
具体类和代理类都不需要实现上层接口或抽象类。
代理类要实现Cglib中的MethodInterceptor接口。
Cglib包的底层是通过使用字节码处理框架ASM来转换字节码生成新的类。
注意问题:
被代理的类不能是final修饰
目标对象中的方法如果是final/static,不支持调用应用实例
科学上网代理
婚庆公司代理
租房中介
房产中介
应用扩展
缺陷问题及规避方案
相关补充
适配器(Adapter)模式
定义(什么是/是什么)
将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。适配器模式分为类结构型模式、对象结构型模式和接口适配器模式。
在现实生活中,经常出现两个对象因接口不兼容而不能在一起工作的实例,这时需要第三者进行适配。例如,讲中文的人同讲英文的人对话时需要一个翻译,用直流电的笔记本电脑接交流电源时需要一个电源适配器,用计算机访问照相机的 SD 内存卡时需要一个读卡器等。
在软件设计中也可能出现:需要开发的具有某种业务功能的组件在现有的组件库中已经存在,但它们与当前系统的接口规范不兼容,如果重新开发这些组件成本又很高,这时用适配器模式能很好地解决这些问题。
接口适配器模式
适用于一个接口不想实现其所有方法的情况。
当不需要全部实现接口中定义的方法时,可先设计一个抽象类实现接口,并为该接口中每个方法提供一个默认实现(空方法),那么该抽象类的子类可有选择地覆盖父类的某些方法来实现需求。
个人感觉有点多此一举,直接实现接口,不想要的方法,写空实现就行了啊,干嘛还要加一个抽象类去写空实现?
作用目的(为什么用)
优点:
客户端通过适配器可以透明地调用目标接口。
复用了现存的类,程序员不需要修改原有代码而重用现有的适配者类。
将目标类和适配者类解耦,解决了目标类和适配者类接口不一致的问题。
缺点:
- 对类适配器来说,更换适配器的实现过程比较复杂。
应用场景
适配器模式(Adapter)通常适用于以下场景:
以前开发的系统存在满足新系统功能需求的类,但其接口同新系统的接口不一致。
使用第三方提供的组件,但组件接口定义和自己要求的接口定义不同。
实现方式
模式的结构
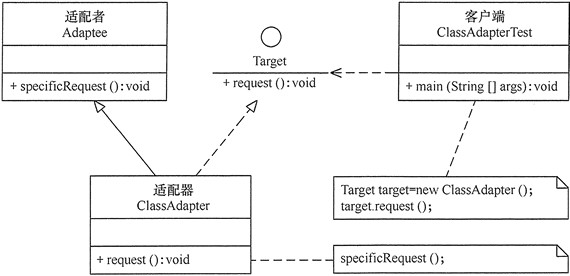
适配器模式(Adapter)包含以下主要角色:
目标(Target)接口:当前系统业务所期待的接口,它可以是抽象类或接口。
适配者(Adaptee)类:它是被访问和适配的现存组件库中的组件接口。
适配器(Adapter)类:它是一个转换器,通过继承或引用适配者的对象,把适配者接口转换成目标接口,让客户按目标接口的格式访问适配者。
类适配器模式的结构图
对象适配器模式的结构图

对象适配器符合合成复用原则,使用聚合代替继承。
模式的实现
应用实例
SpringMVC中的HandlerAdapter使用了适配器模式。
应用扩展
适配器模式(Adapter)可扩展为双向适配器模式,双向适配器类既可以把适配者接口转换成目标接口,也可以把目标接口转换成适配者接口。
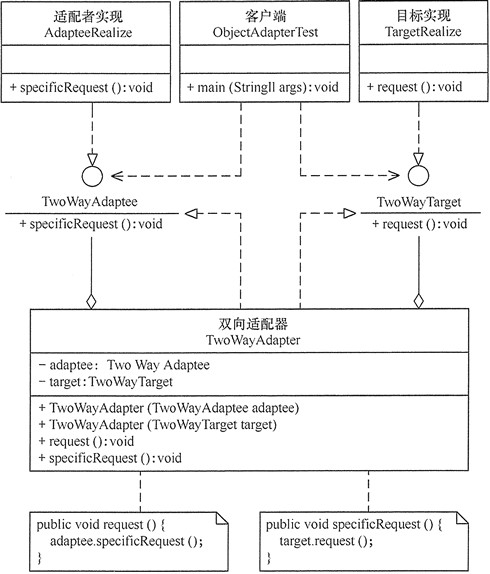
缺陷问题及规避方案
相关补充
桥接(Bridge)模式
定义(什么是/是什么)
将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
作用目的(为什么用)
优点:
由于抽象与实现分离,所以扩展能力强。
其实现细节对客户透明。
缺点:
- 由于聚合关系建立在抽象层,要求开发者针对抽象化进行设计与编程,这增加了系统的理解与设计难度。
应用场景
桥接模式通常适用于以下场景:
当一个类存在两个独立变化的维度,且这两个维度都需要进行扩展时。
当一个系统不希望使用继承或因为多层次继承导致系统类的个数急剧增加时。
当一个系统需要在构件的抽象化角色和具体化角色之间增加更多的灵活性时。
实现方式
模式的结构
桥接(Bridge)模式包含以下主要角色:
抽象化(Abstraction)角色:定义抽象类,并包含一个对实现化对象的引用。
扩展抽象化(Refined Abstraction)角色:是抽象化角色的子类,实现父类中的业务方法,并通过组合关系调用实现化角色中的业务方法。
实现化(Implementor)角色:定义实现化角色的接口,供扩展抽象化角色调用。
具体实现化(Concrete Implementor)角色:给出实现化角色接口的具体实现。
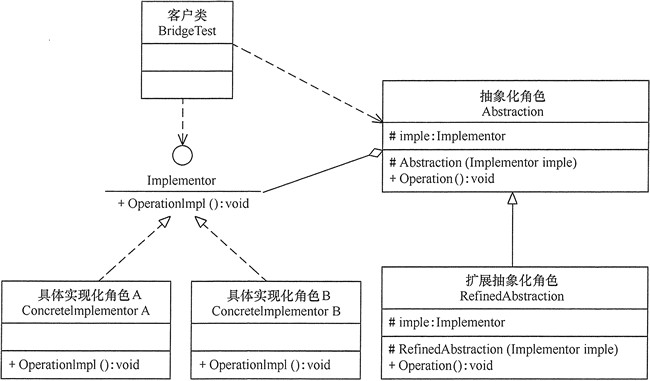
模式的实现
应用实例
应用扩展
在软件开发中,有时桥接(Bridge)模式可与适配器模式联合使用。当桥接(Bridge)模式的实现化角色的接口与现有类的接口不一致时,可以在二者中间定义一个适配器将二者连接起来。
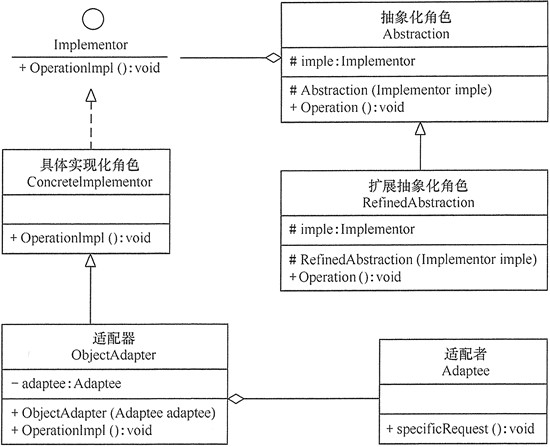
缺陷问题及规避方案
相关补充
★装饰(Decorator)模式
定义(什么是/是什么)
指在不改变现有对象结构的情况下,动态地给该对象增加一些职责(即增加其额外功能)的模式,它属于对象结构型模式。
说白了就是“套娃模式”,被装饰者在最里面,装饰者一层一层包裹下去。
把一个东西加入额外材料修饰打扮一下,呈现一个新的东西,很像小朋友玩的娃娃装扮游戏。
作用目的(为什么用)
优点:
采用装饰模式扩展对象的功能比采用继承方式更加灵活。
可以设计出多个不同的具体装饰类,创造出多个不同行为的组合。
缺点:
- 装饰模式增加了许多子类,如果过度使用会使程序变得很复杂。
应用场景
前面讲解了关于装饰模式的结构与特点,下面介绍其适用的应用场景,装饰模式通常在以下几种情况使用:
当需要给一个现有类添加附加职责,而又不能采用生成子类的方法进行扩充时。例如,该类被隐藏或者该类是终极类或者采用继承方式会产生大量的子类。
当需要通过对现有的一组基本功能进行排列组合而产生非常多的功能时,采用继承关系很难实现,而采用装饰模式却很好实现。
当对象的功能要求可以动态地添加,也可以再动态地撤销时。
实现方式
模式的结构
装饰模式主要包含以下角色:
抽象构件(Component)角色:定义一个抽象接口以规范准备接收附加责任的对象。
具体构件(Concrete Component)角色:实现抽象构件,通过装饰角色为其添加一些职责。
抽象装饰(Decorator)角色:继承抽象构件,并包含具体构件的实例,可以通过其子类扩展具体构件的功能。
具体装饰(ConcreteDecorator)角色:实现抽象装饰的相关方法,并给具体构件对象添加附加的责任。
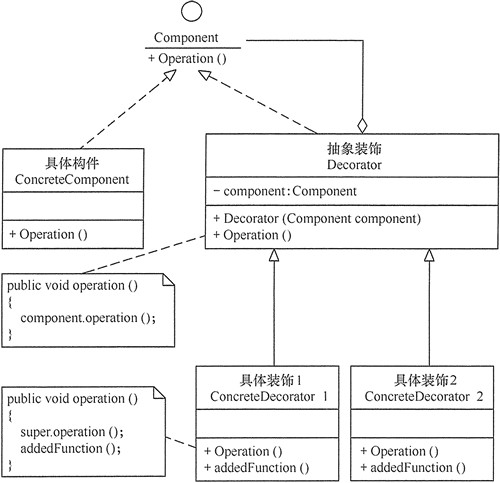
模式的实现
应用实例
装饰模式在 Java 语言中的最著名的应用莫过于 Java I/O 标准库的设计了。例如,InputStream 的子类 FilterInputStream,OutputStream 的子类 FilterOutputStream,Reader 的子类 BufferedReader 以及 FilterReader,还有 Writer 的子类 BufferedWriter、FilterWriter 以及 PrintWriter 等,它们都是抽象装饰类。
星巴克咖啡订单
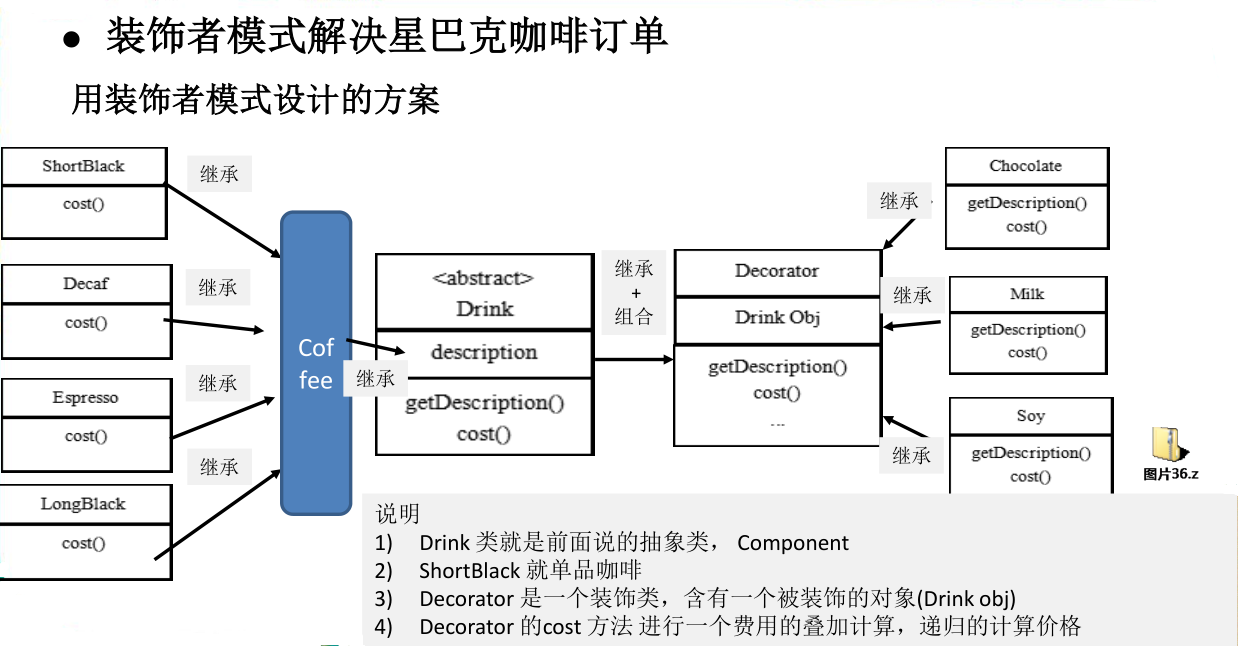
应用扩展
缺陷问题及规避方案
相关补充
外观(Facade)模式
定义(什么是/是什么)
一种通过为多个复杂的子系统提供一个一致的接口,而使这些子系统更加容易被访问的模式。该模式对外有一个统一接口,外部应用程序不用关心内部子系统的具体的细节,这样会大大降低应用程序的复杂度,提高了程序的可维护性。
个人理解:把所有子项目功能打包起来,提供一套统一的对外访问接口。
在现实生活中,常常存在办事较复杂的例子,如办房产证或注册一家公司,有时要同多个部门联系,这时要是有一个综合部门能解决一切手续问题就好了。
软件设计也是这样,当一个系统的功能越来越强,子系统会越来越多,客户对系统的访问也变得越来越复杂。这时如果系统内部发生改变,客户端也要跟着改变,这违背了“开闭原则”,也违背了“迪米特法则”,所以有必要为多个子系统提供一个统一的接口,从而降低系统的耦合度,这就是外观模式的目标。
跟代理模式、建造者模式有些相似。
客户去当地房产局办理房产证过户要遇到的相关部门:
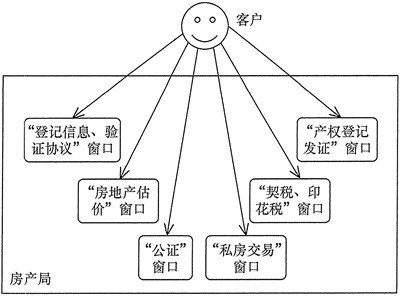
作用目的(为什么用)
优点:
降低了子系统与客户端之间的耦合度,使得子系统的变化不会影响调用它的客户类。
对客户屏蔽了子系统组件,减少了客户处理的对象数目,并使得子系统使用起来更加容易。
降低了大型软件系统中的编译依赖性,简化了系统在不同平台之间的移植过程,因为编译一个子系统不会影响其他的子系统,也不会影响外观对象。
缺点:
不能很好地限制客户使用子系统类。
增加新的子系统可能需要修改外观类或客户端的源代码,违背了“开闭原则”。
应用场景
实现方式
模式的结构
外观(Facade)模式包含以下主要角色:
外观(Facade)角色:为多个子系统对外提供一个共同的接口。
子系统(Sub System)角色:实现系统的部分功能,客户可以通过外观角色访问它。
客户(Client)角色:通过一个外观角色访问各个子系统的功能。
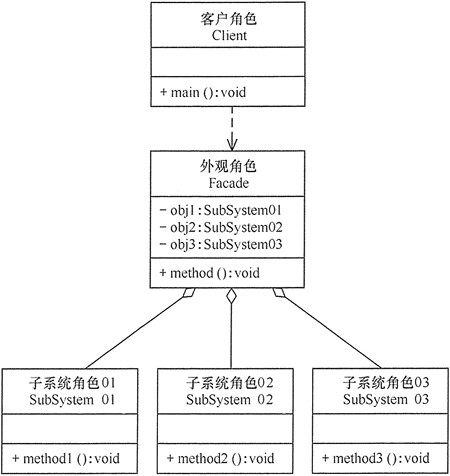
模式的实现
应用实例
应用扩展
在外观模式中,当增加或移除子系统时需要修改外观类,这违背了“开闭原则”。如果引入抽象外观类,则在一定程度上解决了该问题。
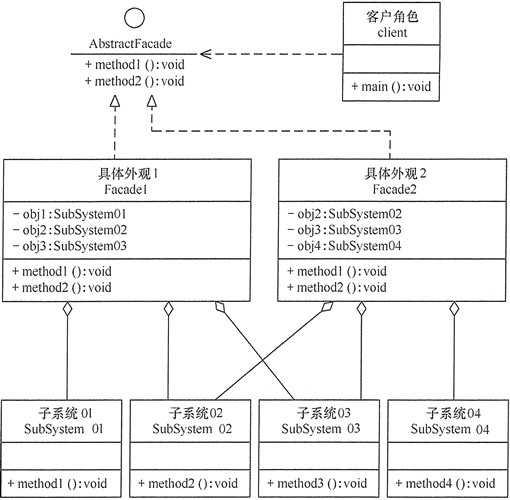
缺陷问题及规避方案
相关补充
享元(Flyweight)模式
定义(什么是/是什么)
运用共享技术来有效地支持大量细粒度对象的复用。它通过共享已经存在的对象来大幅度减少需要创建的对象数量、避免大量相似类的开销,从而提高系统资源的利用率。
个人理解:共享内存中的对象元素。
享元模式中存在以下两种状态:
内部状态,即不会随着环境的改变而改变的可共享部分。
外部状态,指随环境改变而改变的不可以共享的部分。
作用目的(为什么用)
优点:
- 相同对象只要保存一份,这降低了系统中对象的数量,从而降低了系统中细粒度对象给内存带来的压力。
缺点:
为了使对象可以共享,需要将一些不能共享的状态外部化,这将增加程序的复杂性。
读取享元模式的外部状态会使得运行时间稍微变长。
应用场景
前面分析了享元模式的结构与特点,下面分析它适用的应用场景。享元模式是通过减少内存中对象的数量来节省内存空间的,所以以下几种情形适合采用享元模式:
系统中存在大量相同或相似的对象,这些对象耗费大量的内存资源。
大部分的对象可以按照内部状态进行分组,且可将不同部分外部化,这样每一个组只需保存一个内部状态。
由于享元模式需要额外维护一个保存享元的数据结构,所以应当在有足够多的享元实例时才值得使用享元模式。
实现方式
模式的结构
享元模式的主要角色有如下:
抽象享元角色(Flyweight):是所有的具体享元类的基类,为具体享元规范需要实现的公共接口,非享元的外部状态以参数的形式通过方法传入。
具体享元(Concrete Flyweight)角色:实现抽象享元角色中所规定的接口。
非享元(Unsharable Flyweight)角色:是不可以共享的外部状态,它以参数的形式注入具体享元的相关方法中。
享元工厂(Flyweight Factory)角色:负责创建和管理享元角色。当客户对象请求一个享元对象时,享元工厂检査系统中是否存在符合要求的享元对象,如果存在则提供给客户;如果不存在的话,则创建一个新的享元对象。
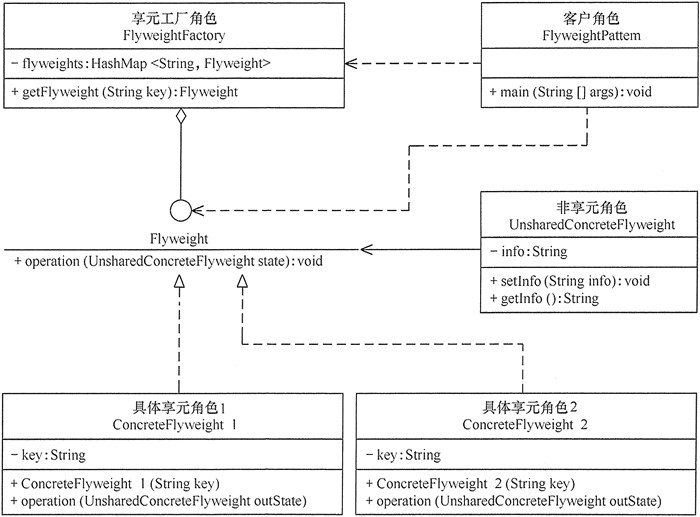
模式的实现
应用实例
Integer[-128,127]的缓存。
享元模式在五子棋游戏中的应用。
应用扩展
缺陷问题及规避方案
相关补充
组合(Composite)模式
定义(什么是/是什么)
组合(Composite)模式又叫作部分-整体模式,它是一种将对象组合成树状的层次结构的模式,用来表示“部分-整体”的关系,使用户对单个对象和组合对象具有一致的访问性。
在现实生活中,存在很多“部分-整体”的关系,例如,大学中的部门与学院、总公司中的部门与分公司、学习用品中的书与书包、生活用品中的衣月艮与衣柜以及厨房中的锅碗瓢盆等。在软件开发中也是这样,例如,文件系统中的文件与文件夹、窗体程序中的简单控件与容器控件等。对这些简单对象与复合对象的处理,如果用组合模式来实现会很方便。
作用目的(为什么用)
优点:
组合模式使得客户端代码可以一致地处理单个对象和组合对象,无须关心自己处理的是单个对象,还是组合对象,这简化了客户端代码;
更容易在组合体内加入新的对象,客户端不会因为加入了新的对象而更改源代码,满足“开闭原则”。
缺点:
设计较复杂,客户端需要花更多时间理清类之间的层次关系。
不容易限制容器中的构件。
不容易用继承的方法来增加构件的新功能。
应用场景
在需要表示一个对象整体与部分的层次结构的场合。
要求对用户隐藏组合对象与单个对象的不同,用户可以用统一的接口使用组合结构中的所有对象的场合。
实现方式
模式的结构
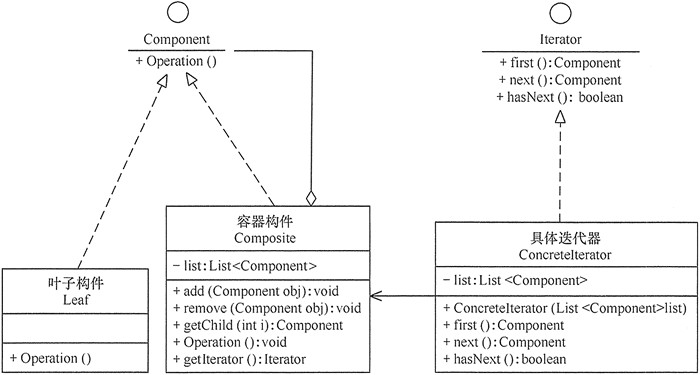
组合模式包含以下主要角色:
抽象构件(Component)角色:它的主要作用是为树叶构件和树枝构件声明公共接口,并实现它们的默认行为。在透明式的组合模式中抽象构件还声明访问和管理子类的接口;在安全式的组合模式中不声明访问和管理子类的接口,管理工作由树枝构件完成。
树叶构件(Leaf)角色:是组合中的叶节点对象,它没有子节点,用于实现抽象构件角色中 声明的公共接口。
树枝构件(Composite)角色:是组合中的分支节点对象,它有子节点。它实现了抽象构件角色中声明的接口,它的主要作用是存储和管理子部件,通常包含 Add()、Remove()、GetChild() 等方法。
组合模式分为透明式的组合模式和安全式的组合模式。
透明方式:在该方式中,由于抽象构件声明了所有子类中的全部方法,所以客户端无须区别树叶对象和树枝对象,对客户端来说是透明的。但其缺点是:树叶构件本来没有 Add()、Remove() 及 GetChild() 方法,却要实现它们(空实现或抛异常),这样会带来一些安全性问题。
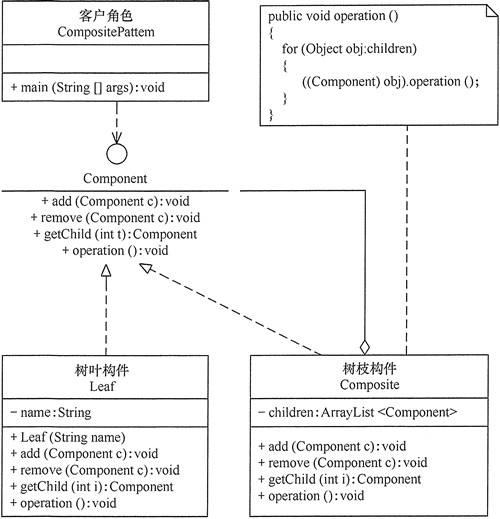
安全方式:在该方式中,将管理子构件的方法移到树枝构件中,抽象构件和树叶构件没有对子对象的管理方法,这样就避免了上一种方式的安全性问题,但由于叶子和分支有不同的接口,客户端在调用时要知道树叶对象和树枝对象的存在,所以失去了透明性。
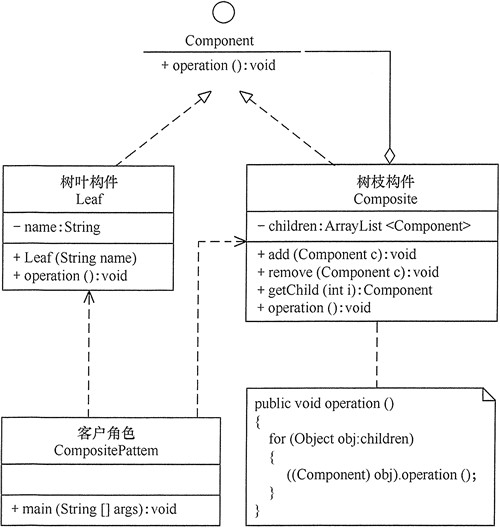
模式的实现
应用实例
应用扩展
缺陷问题及规避方案
相关补充
行为型模式(11)
模板方法(Template Method)模式
定义(什么是/是什么)
定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
简单说就是,确定要做得事情放在父类,不确定的事情就交给子类去做。
例如,去银行办理业务一般要经过以下4个流程:取号、排队、办理具体业务、对银行工作人员进行评分等,其中取号、排队和对银行工作人员进行评分的业务对每个客户是一样的,可以在父类中实现,但是办理具体业务却因人而异,它可能是存款、取款或者转账等,可以延迟到子类中实现。
这样的例子在生活中还有很多,例如,一个人每天会起床、吃饭、做事、睡觉等,其中“做事”的内容每天可能不同。我们把这些规定了流程或格式的实例定义成模板,允许使用者根据自己的需求去更新它,例如,简历模板、论文模板、Word 中模板文件等。
作用目的(为什么用)
优点:
它封装了不变部分,扩展可变部分。它把认为是不变部分的算法封装到父类中实现,而把可变部分算法由子类继承实现,便于子类继续扩展。(扩展性)
它在父类中提取了公共的部分代码,便于代码复用。(复用性)
部分方法是由子类实现的,因此子类可以通过扩展方式增加相应的功能,符合开闭原则。
缺点:
对每个不同的实现都需要定义一个子类,这会导致类的个数增加,系统更加庞大,设计也更加抽象。
父类中的抽象方法由子类实现,子类执行的结果会影响父类的结果,这导致一种反向的控制结构,它提高了代码阅读的难度。
应用场景
模板方法模式通常适用于以下场景:
算法的整体步骤很固定,但其中个别部分易变时,这时候可以使用模板方法模式,将容易变的部分抽象出来,供子类实现。
当多个子类存在公共的行为时,可以将其提取出来并集中到一个公共父类中以避免代码重复。首先,要识别现有代码中的不同之处,并且将不同之处分离为新的操作。最后,用一个调用这些新的操作的模板方法来替换这些不同的代码。
当需要控制子类的扩展时,模板方法只在特定点调用钩子操作,这样就只允许在这些点进行扩展。
实现方式
模式的结构
模板方法模式包含以下主要角色:
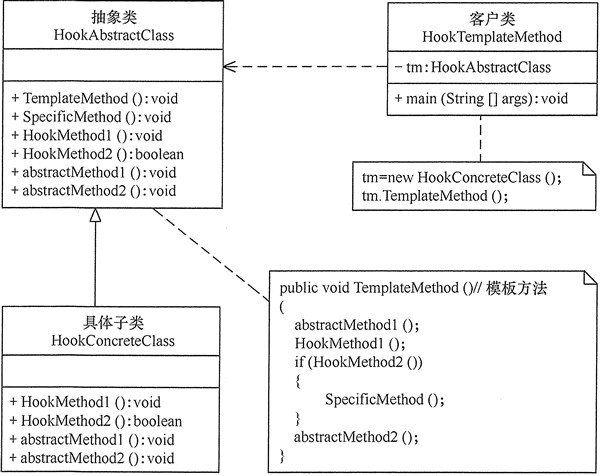
(1) 抽象类(Abstract Class):负责给出一个算法的轮廓和骨架。它由一个模板方法和若干个基本方法构成。这些方法的定义如下。
模板方法:定义了算法的骨架,按某种顺序调用其包含的基本方法。
基本方法:是整个算法中的一个步骤,包含以下几种类型。
抽象方法:在抽象类中申明,由具体子类实现。
具体方法:在抽象类中已经实现,在具体子类中可以继承或重写它。
钩子方法:在抽象类中已经实现,包括用于判断的逻辑方法和需要子类重写的空方法两种。
(2) 具体子类(Concrete Class):实现抽象类中所定义的抽象方法和钩子方法。
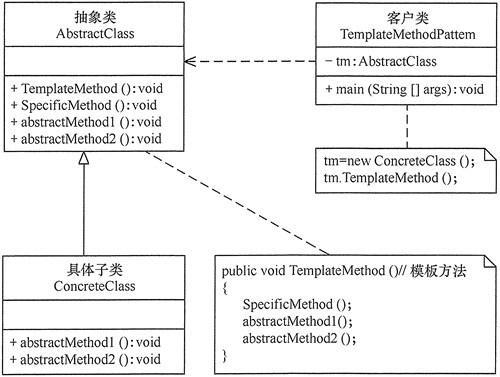
模式的实现
应用实例
Spring IOC容器初始化时,运用了模板模式。
用模板方法模式实现出国留学手续设计程序。
出国留学手续一般经过以下流程:
索取学校资料,提出入学申请,办理因私出国护照、出境卡和公证,申请签证,体检、订机票、准备行装,抵达目标学校等,其中有些业务对各个学校是一样的,但有些业务因学校不同而不同,所以比较适合用模板方法模式来实现。
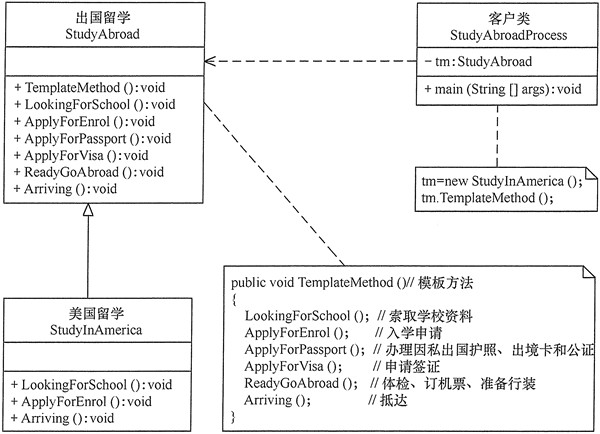
应用扩展
在模板方法模式中,基本方法包含:抽象方法、具体方法和钩子方法,正确使用“钩子方法”可以使得子类控制父类的行为。可以通过在具体子类中重写钩子方法 HookMethod1() 和 HookMethod2() 来改变抽象父类中的运行结果。
缺陷问题及规避方案
相关补充
▲策略(Strategy)模式
定义(什么是/是什么)
该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
简单说,做一件事情有很多种处理方案,或者一个物品有很多种表现形态,用策略模式实现,更容易扩展和复用。
在现实生活中常常遇到实现某种目标存在多种策略可供选择的情况,例如,出行旅游可以乘坐飞机、乘坐火车、骑自行车或自己开私家车等,超市促销可以釆用打折、送商品、送积分等方法。
在软件开发中也常常遇到类似的情况,当实现某一个功能存在多种算法或者策略,我们可以根据环境或者条件的不同选择不同的算法或者策略来完成该功能,如数据排序策略有冒泡排序、选择排序、插入排序、二叉树排序等。
作用目的(为什么用)
优点:
多重条件语句不易维护,而使用策略模式可以避免使用多重条件语句。
策略模式提供了一系列的可供重用的算法族,恰当使用继承可以把算法族的公共代码转移到父类里面,从而避免重复的代码。
策略模式可以提供相同行为的不同实现,客户可以根据不同时间或空间要求选择不同的。
策略模式提供了对开闭原则的完美支持,可以在不修改原代码的情况下,灵活增加新算法。
策略模式把算法的使用放到环境类中,而算法的实现移到具体策略类中,实现了二者的分离。
缺点:
客户端必须理解所有策略算法的区别,以便适时选择恰当的算法类。
策略模式造成很多的策略类。
应用场景
策略模式在很多地方用到,如 Java SE 中的容器布局管理就是一个典型的实例,Java SE 中的每个容器都存在多种布局供用户选择。在程序设计中,通常在以下几种情况中使用策略模式较多:
一个系统需要动态地在几种算法中选择一种时,可将每个算法封装到策略类中。
一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,可将每个条件分支移入它们各自的策略类中以代替这些条件语句。
系统中各算法彼此完全独立,且要求对客户隐藏具体算法的实现细节时。
系统要求使用算法的客户不应该知道其操作的数据时,可使用策略模式来隐藏与算法相关的数据结构。
多个类只区别在表现行为不同,可以使用策略模式,在运行时动态选择具体要执行的行为。
实现方式
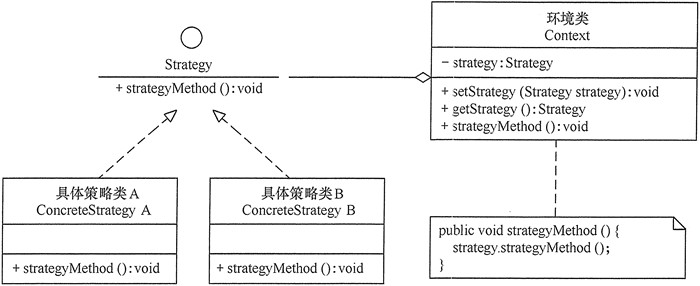
模式的结构
策略模式的主要角色如下:
抽象策略(Strategy)类:定义了一个公共接口,各种不同的算法以不同的方式实现这个接口,环境角色使用这个接口调用不同的算法,一般使用接口或抽象类实现。
具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现。
环境(Context)类:持有一个策略类的引用,最终给客户端调用。
模式的实现
应用实例
Array Sort比较器策略。
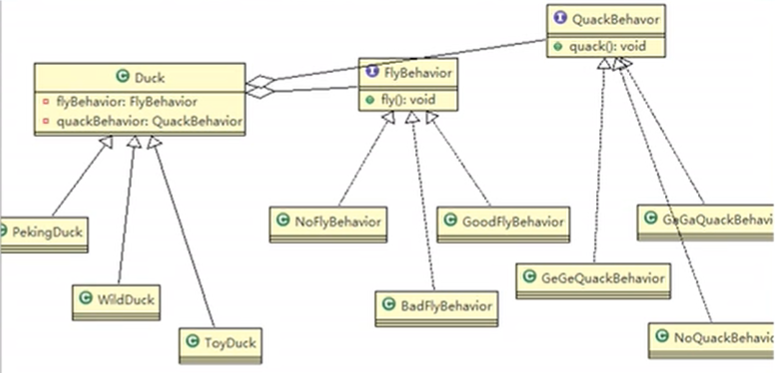
鸭子问题
应用扩展
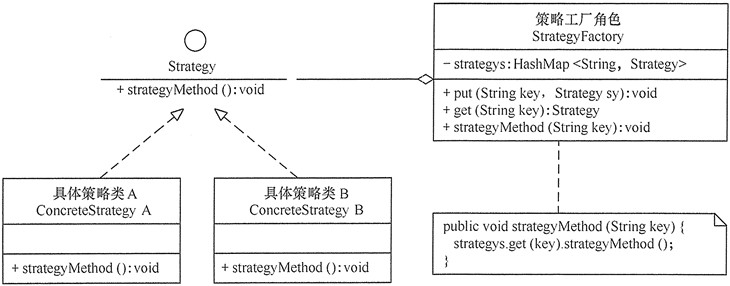
在一个使用策略模式的系统中,当存在的策略很多时,客户端管理所有策略算法将变得很复杂,如果在环境类中使用策略工厂模式来管理这些策略类将大大减少客户端的工作复杂度。
缺陷问题及规避方案
相关补充
命令(Command)模式
定义(什么是/是什么)
将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行储存、传递、调用、增加与管理。
作用目的(为什么用)
优点:
降低系统的耦合度。命令模式能将调用操作的对象与实现该操作的对象解耦。
增加或删除命令非常方便。采用命令模式增加与删除命令不会影响其他类,它满足“开闭原则”,对扩展比较灵活。
可以实现宏命令。命令模式可以与组合模式结合,将多个命令装配成一个组合命令,即宏命令。
方便实现Undo和Redo操作。命令模式可以与后面介绍的备忘录模式结合,实现命令的撤销与恢复。
缺点:
- 可能产生大量具体命令类。因为计对每一个具体操作都需要设计一个具体命令类,这将增加系统的复杂性。
应用场景
命令模式通常适用于以下场景:
当系统需要将请求调用者与请求接收者解耦时,命令模式使得调用者和接收者不直接交互。
当系统需要随机请求命令或经常增加或删除命令时,命令模式比较方便实现这些功能。
当系统需要执行一组操作时,命令模式可以定义宏命令来实现该功能。
当系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作时,可以将命令对象存储起来,采用备忘录模式来实现。
实现方式
模式的结构
命令模式包含以下主要角色:
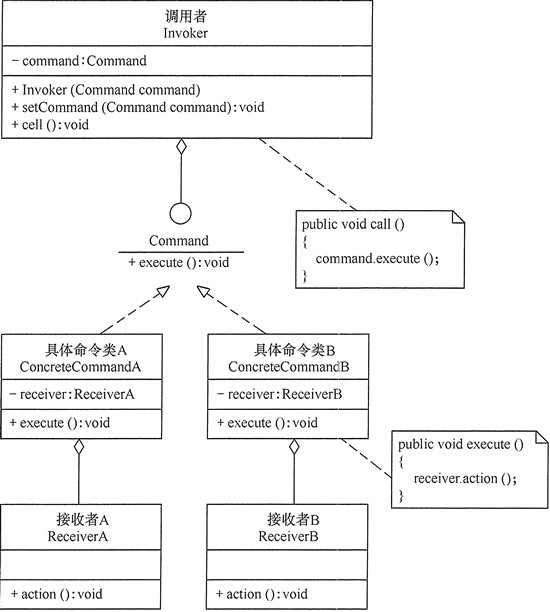
抽象命令类(Command)角色:声明执行命令的接口,拥有执行命令的抽象方法 execute()。
具体命令角色(Concrete Command)角色:是抽象命令类的具体实现类,它拥有接收者对象,并通过调用接收者的功能来完成命令要执行的操作。
实现者/接收者(Receiver)角色:执行命令功能的相关操作,是具体命令对象业务的真正实现者。
调用者/请求者(Invoker)角色:是请求的发送者,它通常拥有很多的命令对象,并通过访问命令对象来执行相关请求,它不直接访问接收者。
模式的实现
应用实例
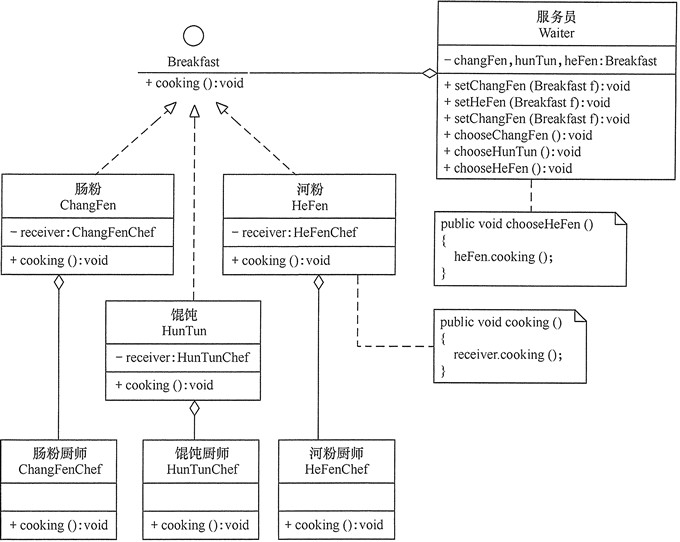
用命令模式实现客户去餐馆吃早餐的实例。
客户去餐馆可选择的早餐有肠粉、河粉和馄饨等,客户可向服务员选择以上早餐中的若干种,服务员将客户的请求交给相关的厨师去做。这里的点早餐相当于“命令”,服务员相当于“调用者”,厨师相当于“接收者”,所以用命令模式实现比较合适。
应用扩展
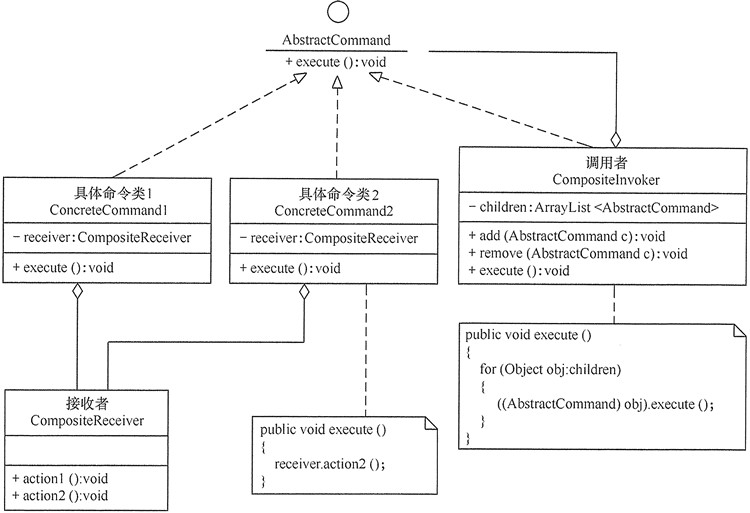
在软件开发中,有时将命令模式与前面学的组合模式联合使用,这就构成了宏命令模式,也叫组合命令模式。宏命令包含了一组命令,它充当了具体命令与调用者的双重角色,执行它时将递归调用它所包含的所有命令。
命令模式还可以同备忘录(Memento)模式组合使用,这样就变成了可撤销的命令模式。
缺陷问题及规避方案
相关补充
▲职责链(Chain of Responsibility)模式
定义(什么是/是什么)
为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
自己做不了或不想做的事情,交给上级或下属去做咯。
作用目的(为什么用)
优点:
降低了对象之间的耦合度。该模式使得一个对象无须知道到底是哪一个对象处理其请求以及链的结构,发送者和接收者也无须拥有对方的明确信息。
增强了系统的可扩展性。可以根据需要增加新的请求处理类,满足开闭原则。
增强了给对象指派职责的灵活性。当工作流程发生变化,可以动态地改变链内的成员或者调动它们的次序,也可动态地新增或者删除责任。
责任链简化了对象之间的连接。每个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if···else 语句。
责任分担。每个类只需要处理自己该处理的工作,不该处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
缺点:
不能保证每个请求一定被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。
对比较长的职责链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
职责链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用。
应用场景
责任链模式通常在以下几种情况使用:
有多个对象可以处理一个请求,哪个对象处理该请求由运行时刻自动确定。
可动态指定一组对象处理请求,或添加新的处理者。
在不明确指定请求处理者的情况下,向多个处理者中的一个提交请求。
实现方式
模式的结构
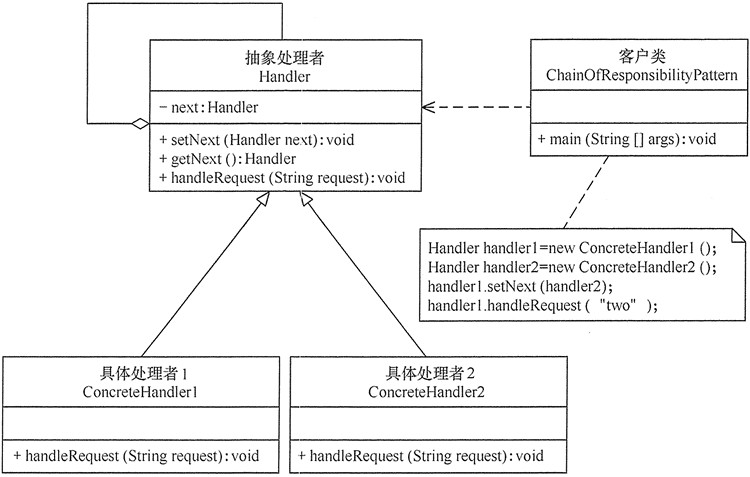
职责链模式主要包含以下角色:
抽象处理者(Handler)角色:定义一个处理请求的接口,包含抽象处理方法和一个后继连接。
具体处理者(Concrete Handler)角色:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。
客户类(Client)角色:创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程。
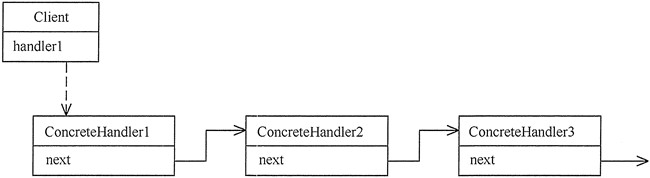
模式的实现
应用实例
SpringMVC-HandlerExecutionChain类使用到职责链模式。
职责链模式解决OA系统采购审批。

用责任链模式设计一个请假条审批模块。
假如规定学生请假小于或等于 2 天,班主任可以批准;小于或等于 7 天,系主任可以批准;小于或等于 10 天,院长可以批准;其他情况不予批准;这个实例适合使用职责链模式实现。
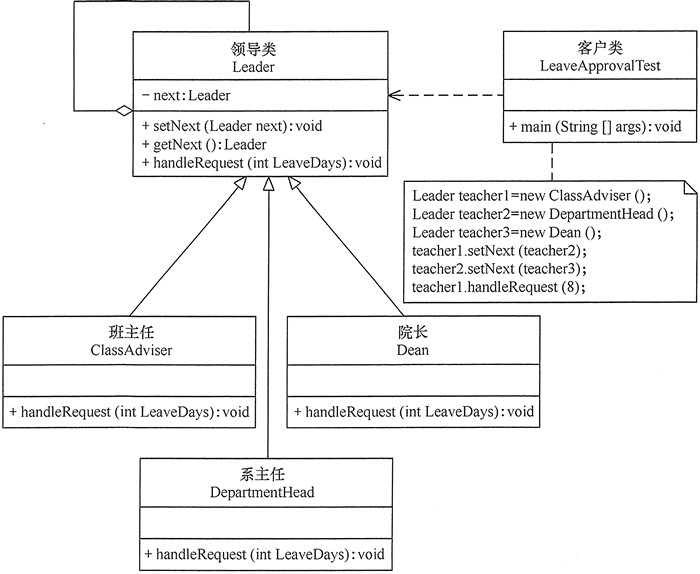
应用扩展
缺陷问题及规避方案
相关补充
★状态(State)模式
定义(什么是/是什么)
对有状态的对象,把复杂的“判断逻辑”提取到不同的状态对象中,允许状态对象在其内部状态发生改变时改变其行为。
对有状态的对象编程,传统的解决方案是:将这些所有可能发生的情况全都考虑到,然后使用 if-else 语句来做状态判断,再进行不同情况的处理。但当对象的状态很多时,程序会变得很复杂。而且增加新的状态要添加新的 if-else 语句,这违背了“开闭原则”,不利于程序的扩展。
如果采用“状态模式”就能很好地得到解决。状态模式的解决思想是:当控制一个对象状态转换的条件表达式过于复杂时,把相关“判断逻辑”提取出来,放到一系列的状态类当中,这样可以把原来复杂的逻辑判断简单化。
作用目的(为什么用)
优点:
状态模式将与特定状态相关的行为局部化到一个状态中,并且将不同状态的行为分割开来,满足“单一职责原则”。
减少对象间的相互依赖。将不同的状态引入独立的对象中会使得状态转换变得更加明确,且减少对象间的相互依赖。
有利于程序的扩展。通过定义新的子类很容易地增加新的状态和转换。
缺点:
每种状态对应一个类,原本的if-else代码片段用一个一个状态类替换,类及其对象增加,同时也增加了系统内存的开销和系统复杂度。
状态模式的结构与实现都较为复杂,如果使用不当会导致程序结构和代码的混乱。
应用场景
通常在以下情况下可以考虑使用状态模式:
当一个对象的行为取决于它的状态,并且它必须在运行时根据状态改变它的行为时,就可以考虑使用状态模式。
一个操作中含有庞大的分支结构,并且这些分支决定于对象的状态时。
实现方式
模式的结构
状态模式包含以下主要角色:
环境(Context)角色:也称为上下文,它定义了客户感兴趣的接口,维护一个当前状态,并将与状态相关的操作委托给当前状态对象来处理。
抽象状态(State)角色:定义一个接口,用以封装环境对象中的特定状态所对应的行为。
具体状态(ConcreteState)角色:实现抽象状态所对应的行为。
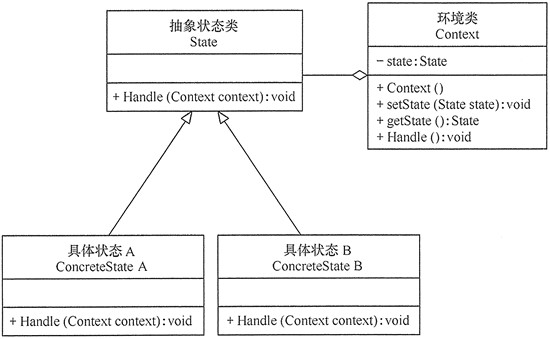
模式的实现
应用实例
用“状态模式”设计一个多线程的状态转换程序。
多线程存在 5 种状态,分别为新建状态、就绪状态、运行状态、阻塞状态和死亡状态,各个状态当遇到相关方法调用或事件触发时会转换到其他状态。
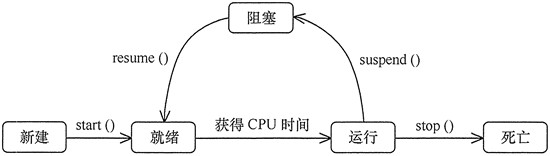
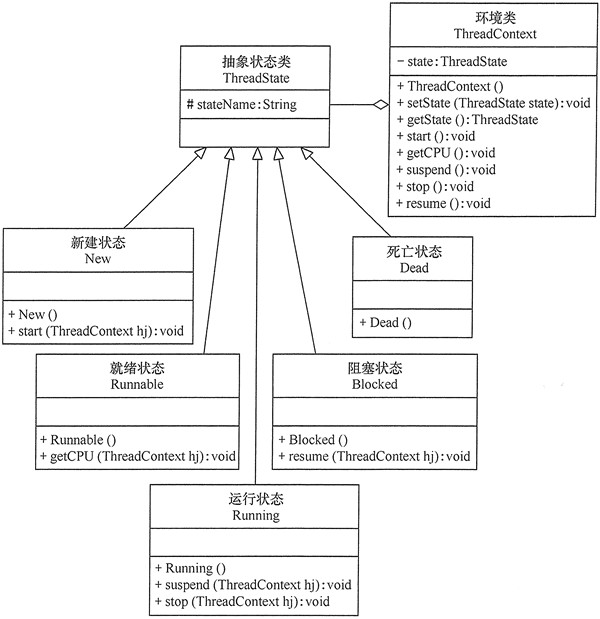
应用扩展
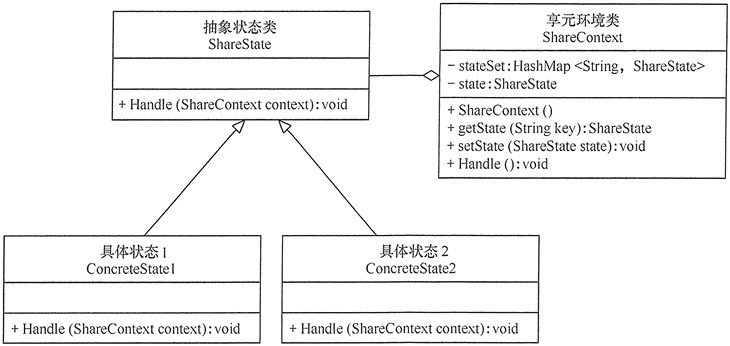
在有些情况下,可能有多个环境对象需要共享一组状态,这时需要引入享元模式,将这些具体状态对象放在集合中供程序共享。
缺陷问题及规避方案
相关补充
★观察者(Observer)模式
定义(什么是/是什么)
指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式、模型-视图模式,它是对象行为型模式。
作用目的(为什么用)
优点:
降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。
目标与观察者之间建立了一套触发机制。
缺点:
目标与观察者之间的依赖关系并没有完全解除,而且有可能出现循环引用。
当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
应用场景
观察者模式适合以下几种场景:
对象间存在一对多关系,一个对象的状态发生改变会影响其他对象。
当一个抽象模型有两个方面,其中一个方面依赖于另一方面时,可将这二者封装在独立的对象中以使它们可以各自独立地改变和复用。
实现方式
模式的结构
观察者模式的主要角色如下:
抽象主题(Subject)角色:也叫抽象目标类,它提供了一个用于保存观察者对象的聚集类和增加、删除观察者对象的方法,以及通知所有观察者的抽象方法。
具体主题(Concrete Subject)角色:也叫具体目标类,它实现抽象目标中的通知方法,当具体主题的内部状态发生改变时,通知所有注册过的观察者对象。
抽象观察者(Observer)角色:它是一个抽象类或接口,它包含了一个更新自己的抽象方法,当接到具体主题的更改通知时被调用。
具体观察者(Concrete Observer)角色:实现抽象观察者中定义的抽象方法,以便在得到目标的更改通知时更新自身的状态。
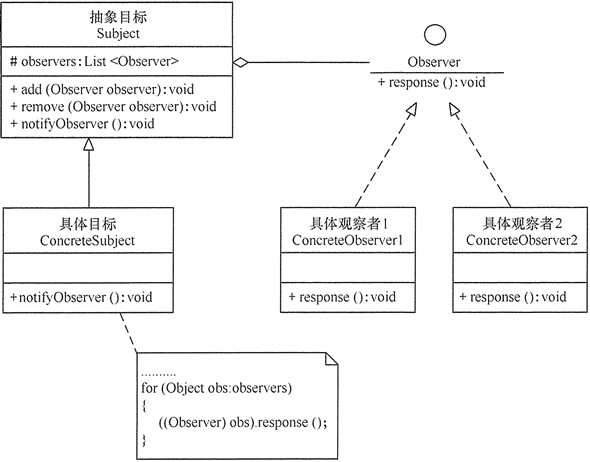
模式的实现
应用实例
天气预报信息发布与订阅。
应用扩展
缺陷问题及规避方案
相关补充
中介者(Mediator)模式
定义(什么是/是什么)
定义一个中介对象来封装一系列对象之间的交互,使原有对象之间的耦合松散,且可以独立地改变它们之间的交互。中介者模式又叫调停模式,它是迪米特法则的典型应用。
就好比,刚毕业的学生参加工作需要租房,找一手房东,可能要一个一个找下去,但如果找中介,一个中介就能对应多个房东。
作用目的(为什么用)
优点:
降低了对象之间的耦合性,使得对象易于独立地被复用。
将对象间的一对多关联转变为一对一的关联,提高系统的灵活性,使得系统易于维护和扩展。
缺点:
- 当业务类太多时,中介者的职责将很大,它会变得复杂而庞大,以至于系统难以维护。
应用场景
多件事情做起来很麻烦了,自然就会想到可不可以找中介处理。
当对象之间存在复杂的网状结构关系而导致依赖关系混乱且难以复用时。
当想创建一个运行于多个类之间的对象,又不想生成新的子类时。
实现方式
模式的结构
中介者模式包含以下主要角色:
抽象中介者(Mediator)角色:它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。
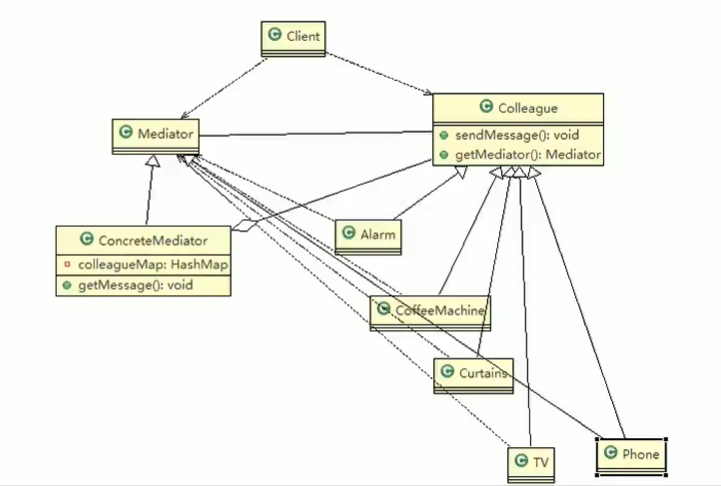
具体中介者(ConcreteMediator)角色:实现中介者接口,定义一个 List 来管理同事对象,协调各个同事角色之间的交互关系,因此它依赖于同事角色。
抽象同事类(Colleague)角色:定义同事类的接口,保存中介者对象,提供同事对象交互的抽象方法,实现所有相互影响的同事类的公共功能。
具体同事类(Concrete Colleague)角色:是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。
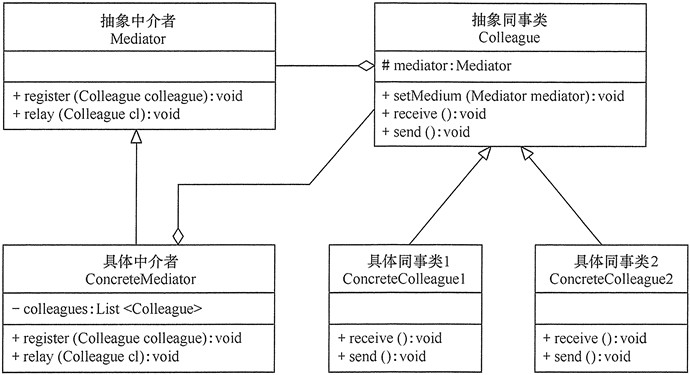
模式的实现
应用实例
智能家居
应用扩展
缺陷问题及规避方案
相关补充
迭代器(Iterator)模式
定义(什么是/是什么)
提供一个对象来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
在现实生活以及程序设计中,经常要访问一个聚合对象中的各个元素,如“数据结构”中的链表遍历,通常的做法是将链表的创建和遍历都放在同一个类中,但这种方式不利于程序的扩展,如果要更换遍历方法就必须修改程序源代码,这违背了 “开闭原则”。
既然将遍历方法封装在聚合类中不可取,那么聚合类中不提供遍历方法,将遍历方法由用户自己实现是否可行呢?答案是同样不可取,因为这种方式会存在两个缺点:
暴露了聚合类的内部表示,使其数据不安全;
增加了客户的负担。
“迭代器模式”能较好地克服以上缺点,它在客户访问类与聚合类之间插入一个迭代器,这分离了聚合对象与其遍历行为,对客户也隐藏了其内部细节,且满足“单一职责原则”和“开闭原则”,如 Java 中的 Collection、List、Set、Map 等都包含了迭代器。
作用目的(为什么用)
优点:
访问一个聚合对象的内容而无须暴露它的内部表示。
遍历任务交由迭代器完成,这简化了聚合类。
它支持以不同方式遍历一个聚合,甚至可以自定义迭代器的子类以支持新的遍历。
增加新的聚合类和迭代器类都很方便,无须修改原有代码。
封装性良好,为遍历不同的聚合结构提供一个统一的接口。
缺点:
- 增加了类的个数,这在一定程度上增加了系统的复杂性。
应用场景
前面介绍了关于迭代器模式的结构与特点,下面介绍其应用场景,迭代器模式通常在以下几种情况使用:
当需要为聚合对象提供多种遍历方式时。
当需要为遍历不同的聚合结构提供一个统一的接口时。
当访问一个聚合对象的内容而无须暴露其内部细节的表示时。
实现方式
模式的结构
迭代器模式主要包含以下角色:
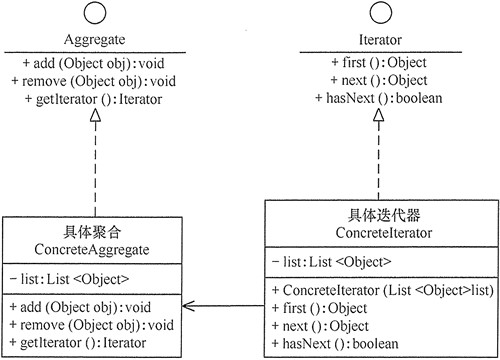
抽象聚合(Aggregate)角色:定义存储、添加、删除聚合对象以及创建迭代器对象的接口。
具体聚合(ConcreteAggregate)角色:实现抽象聚合类,返回一个具体迭代器的实例。
抽象迭代器(Iterator)角色:定义访问和遍历聚合元素的接口,通常包含 hasNext()、first()、next() 等方法。
具体迭代器(Concretelterator)角色:实现抽象迭代器接口中所定义的方法,完成对聚合对象的遍历,记录遍历的当前位置。
模式的实现
应用实例
ArrayList使用了迭代器模式。
应用扩展
迭代器模式常常与组合模式结合起来使用,在对组合模式中的容器构件进行访问时,经常将迭代器潜藏在组合模式的容器构成类中。当然,也可以构造一个外部迭代器来对容器构件进行访问。
缺陷问题及规避方案
相关补充
▲访问者(Visitor)模式
定义(什么是/是什么)
将作用于某种数据结构中的各元素的操作分离出来封装成独立的类,使其在不改变数据结构的前提下可以添加作用于这些元素的新的操作,为数据结构中的每个元素提供多种访问方式。它将对数据的操作与数据结构进行分离。
作用目的(为什么用)
优点:
扩展性好。能够在不修改对象结构中的元素的情况下,为对象结构中的元素添加新的功能。
复用性好。可以通过访问者来定义整个对象结构通用的功能,从而提高系统的复用程度。
灵活性好。访问者模式将数据结构与作用于结构上的操作解耦,使得操作集合可相对自由地演化而不影响系统的数据结构。
符合单一职责原则。访问者模式把相关的行为封装在一起,构成一个访问者,使每一个访问者的功能都比较单一。
缺点:
增加新的元素类很困难。在访问者模式中,每增加一个新的元素类,都要在每一个具体访问者类中增加相应的具体操作,这违背了“开闭原则”。
破坏封装。访问者模式中具体元素对访问者公布细节,这破坏了对象的封装性。
违反了依赖倒置原则。访问者模式依赖了具体类,而没有依赖抽象类。
应用场景
通常在以下情况可以考虑使用访问者(Visitor)模式:
对象结构相对稳定,但其操作算法经常变化的程序。
对象结构中的对象需要提供多种不同且不相关的操作,而且要避免让这些操作的变化影响对象的结构。
对象结构包含很多类型的对象,希望对这些对象实施一些依赖于其具体类型的操作。
实现方式
模式的结构
访问者模式包含以下主要角色:
抽象访问者(Visitor)角色:定义一个访问具体元素的接口,为每个具体元素类对应一个访问操作 visit() ,该操作中的参数类型标识了被访问的具体元素。
具体访问者(ConcreteVisitor)角色:实现抽象访问者角色中声明的各个访问操作,确定访问者访问一个元素时该做什么。
抽象元素(Element)角色:声明一个包含接受操作 accept() 的接口,被接受的访问者对象作为 accept() 方法的参数。
具体元素(ConcreteElement)角色:实现抽象元素角色提供的 accept() 操作,其方法体通常都是 visitor.visit(this) ,另外具体元素中可能还包含本身业务逻辑的相关操作。
对象结构(Object Structure)角色:是一个包含元素角色的容器,提供让访问者对象遍历容器中的所有元素的方法,通常由 List、Set、Map 等聚合类实现。

模式的实现
应用实例
不同人对歌手演唱的评价。

应用扩展
缺陷问题及规避方案
相关补充
备忘录(Memento)模式
定义(什么是/是什么)
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便以后当需要时能将该对象恢复到原先保存的状态。该模式又叫快照模式。
备份之前的状态。
每个人都有犯错误的时候,都希望有种“后悔药”能弥补自己的过失,让自己重新开始,但现实是残酷的。在计算机应用中,客户同样会常常犯错误,能否提供“后悔药”给他们呢?当然是可以的,而且是有必要的。这个功能由“备忘录模式”来实现。
其实很多应用软件都提供了这项功能,如 Word、记事本、Photoshop、Eclipse 等软件在编辑时按 Ctrl+Z 组合键时能撤销当前操作,使文档恢复到之前的状态;还有在 IE 中的后退键、数据库事务管理中的回滚操作、玩游戏时的中间结果存档功能、数据库与操作系统的备份操作、棋类游戏中的悔棋功能等都属于这类。
备忘录模式能记录一个对象的内部状态,当用户后悔时能撤销当前操作,使数据恢复到它原先的状态。
作用目的(为什么用)
优点:
提供了一种可以恢复状态的机制。当用户需要时能够比较方便地将数据恢复到某个历史的状态。
实现了内部状态的封装。除了创建它的发起人之外,其他对象都不能够访问这些状态信息。
简化了发起人类。发起人不需要管理和保存其内部状态的各个备份,所有状态信息都保存在备忘录中,并由管理者进行管理,这符合单一职责原则。
缺点:
- 资源消耗大。如果要保存的内部状态信息过多或者特别频繁,将会占用比较大的内存资源。
应用场景
需要保存与恢复数据的场景,如玩游戏时的中间结果的存档功能。
需要提供一个可回滚操作的场景,如 Word、记事本、Photoshop,Eclipse 等软件在编辑时按 Ctrl+Z 组合键,还有数据库中事务操作。
实现方式
模式的结构
模式的实现
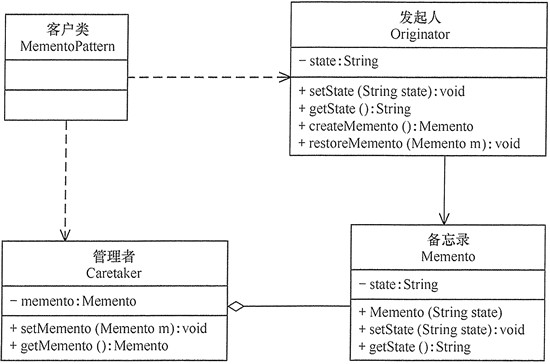
备忘录模式的主要角色如下:
发起人(Originator)角色:记录当前时刻的内部状态信息,提供创建备忘录和恢复备忘录数据的功能,实现其他业务功能,它可以访问备忘录里的所有信息。
备忘录(Memento)角色:负责存储发起人的内部状态,在需要的时候提供这些内部状态给发起人。
管理者(Caretaker)角色:对备忘录进行管理,提供保存与获取备忘录的功能,但其不能对备忘录的内容进行访问与修改。
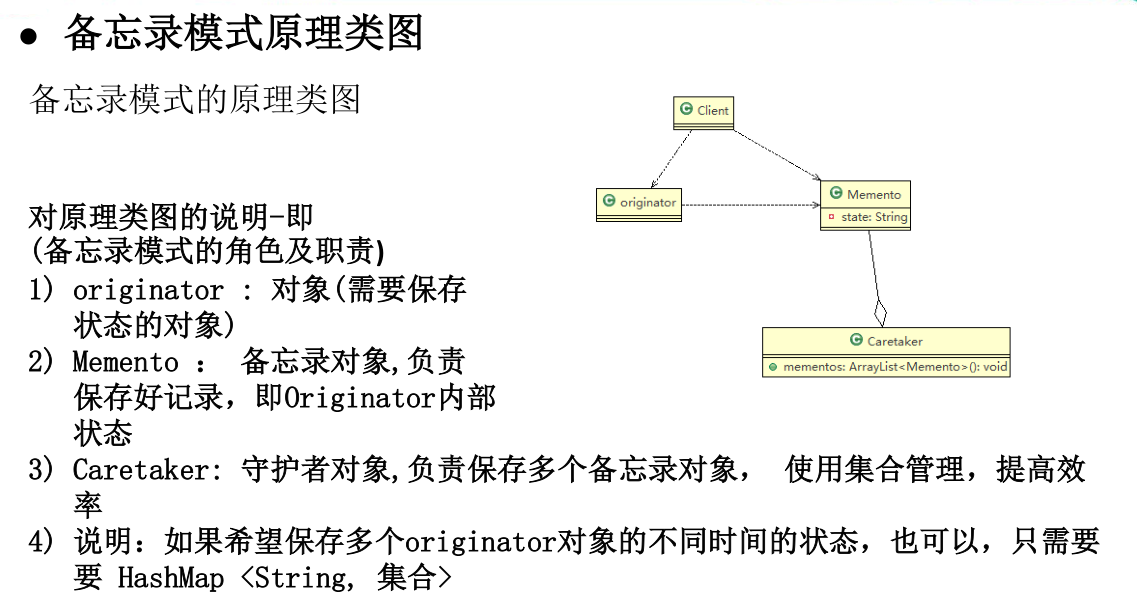
应用实例
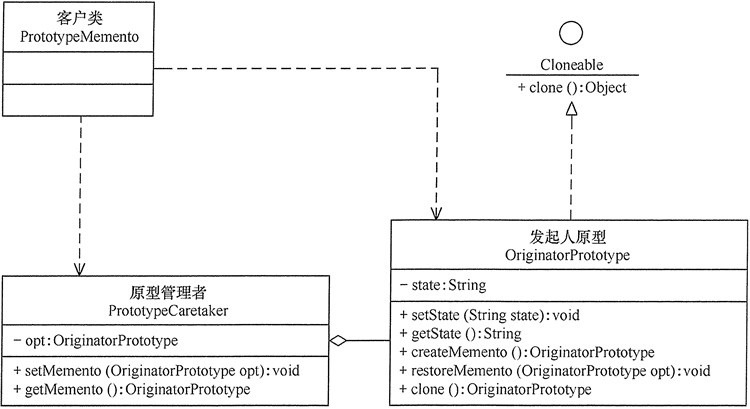
应用扩展
备忘录模式可以跟原型模式混合使用。在备忘录模式中,通过定义“备忘录”来备份“发起人”的信息,而原型模式的 clone() 方法具有自备份功能,所以,如果让发起人实现 Cloneable 接口就有备份自己的功能,这时可以删除备忘录类。
缺陷问题及规避方案
相关补充
解释器(Interpreter)模式
定义(什么是/是什么)
给分析对象定义一个语言,并定义该语言的文法表示,再设计一个解析器来解释语言中的句子。也就是说,用编译语言的方式来分析应用中的实例。这种模式实现了文法表达式处理的接口,该接口解释一个特定的上下文。
作用目的(为什么用)
优点:
扩展性好。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
容易实现。在语法树中的每个表达式节点类都是相似的,所以实现其文法较为容易。
缺点:
执行效率较低。解释器模式中通常使用大量的循环和递归调用,当要解释的句子较复杂时,其运行速度很慢,且代码的调试过程也比较麻烦。
会引起类膨胀。解释器模式中的每条规则至少需要定义一个类,当包含的文法规则很多时,类的个数将急剧增加,导致系统难以管理与维护。
可应用的场景比较少。在软件开发中,需要定义语言文法的应用实例非常少,所以这种模式很少被使用到。
应用场景
当语言的文法较为简单,且执行效率不是关键问题时。
当问题重复出现,且可以用一种简单的语言来进行表达时。
当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象语法树的时候,如 XML 文档解释。
实现方式
模式的结构
解释器模式包含以下主要角色:
抽象表达式(Abstract Expression)角色:定义解释器的接口,约定解释器的解释操作,主要包含解释方法 interpret()。
终结符表达式(Terminal Expression)角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。
非终结符表达式(Nonterminal Expression)角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。
环境(Context)角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
客户端(Client):主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。
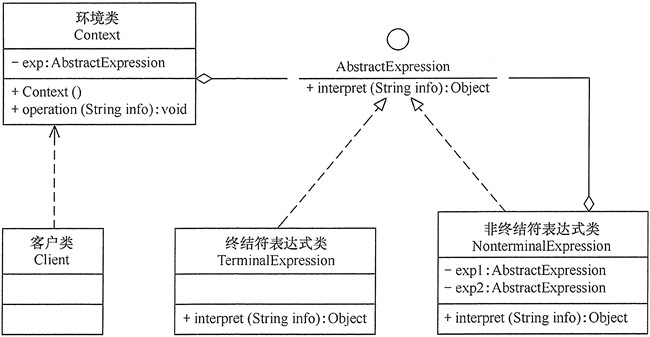
模式的实现