Java多线程并发编程
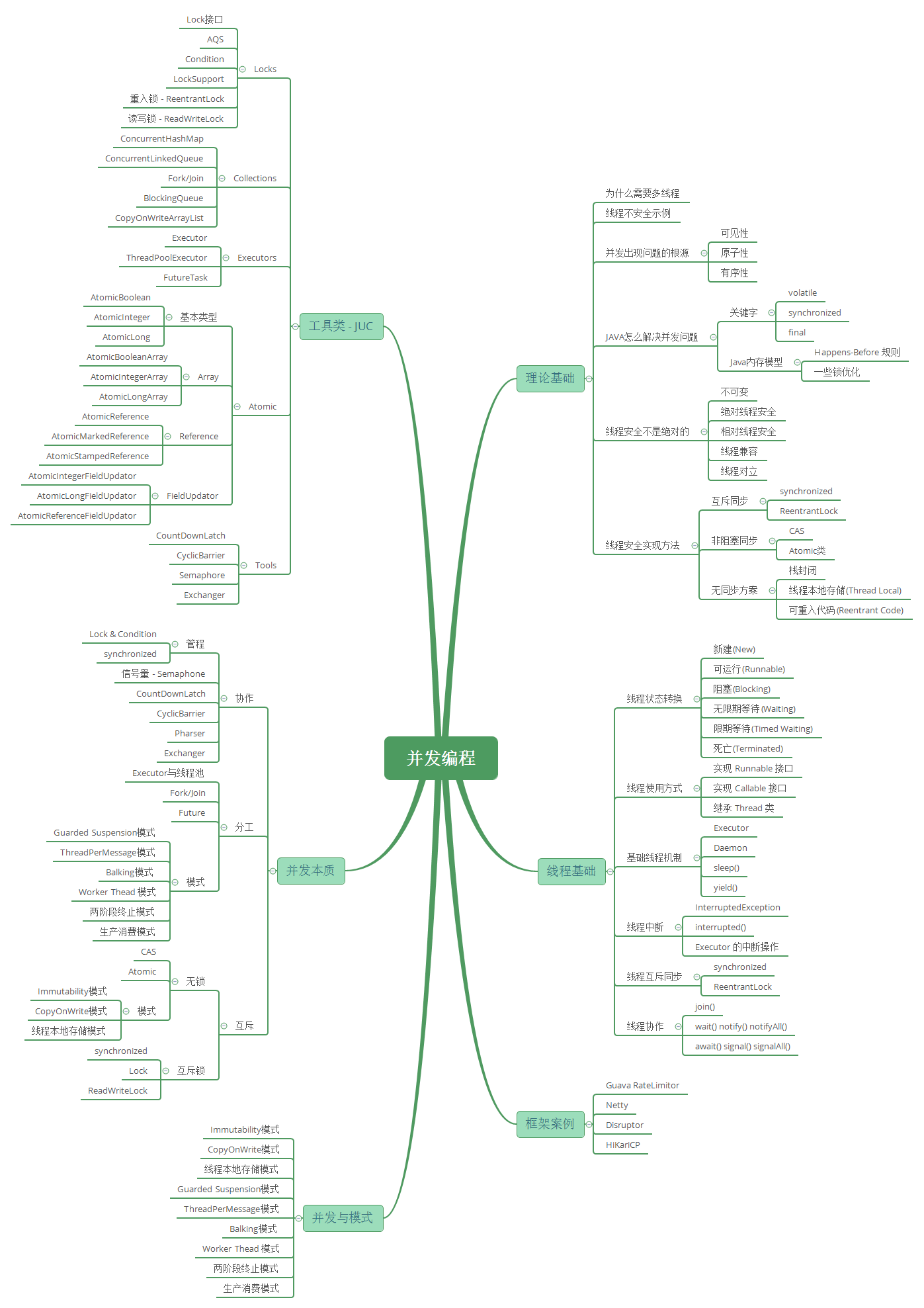
一、多线程基础与概念
结合面试问题加深理解
【理论基础】
- 多线程的出现是要解决什么问题的?
- 线程不安全是指什么? 举例说明
- 并发出现线程不安全的本质什么? 可见性,原子性和有序性。
- Java是怎么解决并发问题的? 3个关键字,JMM和8个Happens-Before
- 线程安全有哪些实现方案?
- 如何理解并发和并行的区别?
【线程基础】
- 线程有哪几种状态? 分别说明从一种状态到另一种状态转变有哪些方式?
- 通常线程有哪几种使用方式?
- 基础线程机制有哪些?
- 线程的中断方式有哪些?
- 线程的互斥同步方式有哪些? 如何比较和选择?
- 线程之间有哪些协作方式?
【Synchronized】
- Synchronized可以作用在哪里? 分别通过对象锁和类锁进行举例。
- Synchronized本质上是通过什么保证线程安全的? 分三个方面回答:加锁和释放锁的原理,可重入原理,保证可见性原理。
- Synchronized由什么样的缺陷? Java Lock是怎么弥补这些缺陷的。
- Synchronized和Lock的对比,和选择?
- Synchronized在使用时有何注意事项?
- Synchronized修饰的方法在抛出异常时,会释放锁吗?
- 多个线程等待同一个snchronized锁的时候,JVM如何选择下一个获取锁的线程?
- Synchronized使得同时只有一个线程可以执行,性能比较差,有什么提升的方法?
- 我想更加灵活地控制锁的释放和获取(现在释放锁和获取锁的时机都被规定死了),怎么办?
- 什么是锁的升级和降级? 什么是JVM里的偏斜锁、轻量级锁、重量级锁?
- 不同的JDK中对Synchronized有何优化?
【volatile】
- volatile关键字的作用是什么?
- volatile能保证原子性吗?
- 之前32位机器上共享的long和double变量的为什么要用volatile? 现在64位机器上是否也要设置呢?
- i++为什么不能保证原子性?
- volatile是如何实现可见性的? 内存屏障。
- volatile是如何实现有序性的? happens-before等
- 说下volatile的应用场景?
【final】
- 所有的final修饰的字段都是编译期常量吗?
- 如何理解private所修饰的方法是隐式的final?
- 说说final类型的类如何拓展? 比如String是final类型,想写个MyString复用所有String中方法,同时增加一个新的toMyString()的方法,应该如何做?
- final方法可以被重载吗? 可以
- 父类的final方法能不能够被子类重写? 不可以
- 说说final域重排序规则?
- 说说final的原理?
- 使用 final 的限制条件和局限性?
- 看 final 详解最后的一个思考题
【CAS, Unsafe和原子类】
- 线程安全的实现方法有哪些?
- 什么是CAS?
- CAS使用示例,结合AtomicInteger给出示例?
- CAS会有哪些问题?
- 针对这这些问题,Java提供了哪几个解决的?
- AtomicInteger底层实现? CAS+volatile
- 请阐述你对Unsafe类的理解?
- 说说你对Java原子类的理解? 包含13个,4组分类,说说作用和使用场景。
- AtomicStampedReference是什么?
- AtomicStampedReference是怎么解决ABA的? 内部使用Pair来存储元素值及其版本号
- java中还有哪些类可以解决ABA的问题? AtomicMarkableReference
【LockSupport】
- 为什么LockSupport也是核心基础类? AQS框架借助于两个类:Unsafe(提供CAS操作)和LockSupport(提供park/unpark操作)
- 写出分别通过wait/notify和LockSupport的park/unpark实现同步?
- LockSupport.park()会释放锁资源吗? 那么Condition.await()呢?
- Thread.sleep()、Object.wait()、Condition.await()、LockSupport.park()的区别? 重点
- 如果在wait()之前执行了notify()会怎样?
- 如果在park()之前执行了unpark()会怎样?
为什么学多线程并发编程
初级开发者可能更多的是为了应付面试。工作三五年之后,再想着弄虚作假糊弄应付面试,恐怕真的不行了,面试官可不是吃素的!你不行,后面还有一大批求职者等着呢,没点真本事,只能眼睁睁看着机会从身边流逝,很看好的公司,然而自己却面试不过,这种心痛的滋味可不好受。
其实,多线程并发应用程序的优势是非常显著的,尤其是在多核CPU和大内存的系统环境下,多线程能更大程度地利用发挥硬件性能,为应用程序带来业务处理响应速度上的提升,给用户更好的体验感受,进而更好的留住用户和吸引更多新用户。
多线程并发编程很有用,是大厂项目标配,顺应时代技术发展的需求。不掌握多线程,别说一线大厂,二三线公司估计都进不了,被人挑三拣四,进不了好公司,你的时间和身体将会被廉价的消费和压榨,最后的结果是,钱没赚多少,时间和健康几乎全搭进去了,关键是技术水平还在原地踏步,技术水平没提升,跳槽到大公司的希望又很渺茫,陷入“—>技术水平差—>进不了大厂—>小公司压榨时间身体,技术很难提升—>”恶性循环。中年危机被淘汰的毫无疑问就是这批“温水煮青蛙”的普通”CRUD“开发人群。程序员的职业生涯,不可能一直做开发,年纪大了,要么走管理岗,要么做架构师,要么就尽早准备转行,做产品经理或其他互联网工作,或者创业做生意。出路是走出来的,即使下沉也还是得走,一步一个圈。焦虑害怕逃避不仅没有帮助,反而还因为过多的精神内耗,浪费掉最宝贵的年轻时光!!
为什么需要多线程
充分利用 CPU 资源,资源闲置就是浪费,宁愿高负荷运转损耗硬件,也不愿意让硬件空闲。
直白一点,榨干计算机的可用价值。
进程与线程
进程是资源分配的最小单位,线程是CPU调度的最小单位。
一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线。
进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段,数据集,堆等)及一些进程级的资源(如打开文件和信号等),某进程内的线程在其他进程不可见。
调度和切换:线程上下文切换比进程上下文切换要快得多。
(概念这东西,理工科还要死记硬背?就用自己的话表达出来就好了。)
通俗理解:
进程:一个程序运行就是一个进程。程序多开,运行的是多个进程。理论上一个封好包的应用程序运行后就只有一个进程,但程序分多个程序包或多个程序模块运行则有多个进程。
杀毒软件主程序及其功能模块以独立进程运行

谷歌浏览器主程序及插件以独立进程运行
线程:程序运行过程中,能同时处理多个业务,处理每个业务就是一个线程。
借助 Process Explorer 工具查看应用程序进程下的线程
做个简单的比喻:进程=火车,线程=车厢
线程在进程下行进(单纯的车厢无法运行)
一个进程可以包含多个线程(一辆火车可以有多个车厢)
不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-"互斥锁"
进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
(https://www.zhihu.com/question/25532384/answer/411179772)
进程通信
参照“操作系统-进程与线程-进程通信”。
管道 netstat -tulnp | grep 8080
消息队列 mq
共享内存
信号量 计数器
信号 硬件中断 事件通知
socket 远程网络通信
并行与并发
并发:以前单核CPU要处理多个应用程序进程,需要进程切换执行。就好像早上排队安检进地铁站,有时候一个安检口硬是分开排了三队,因为排一队的话人太多了,早晚高峰人流量特别大,一个口,三队人,门一次只能过一个,三队只能轮流着进了。
并行:现在的CPU基本都是四核八核,甚至更高,多个应用程序进程可以由不同的CPU同时处理了。比如,单向机动车道有两三条道;地铁口设置多个安检门。当然,并行只是相对的,应用程序打开多了,进程线程就多了,CPU还是要切换执行。就像现在早晚高峰的地铁安检,就算安检门多了,但人一多,同样还是排多队轮流进安检门。
多线程应用场景
异步调用
新开一个线程,进行异步调用执行,可以避免主线程阻塞,子线程异步调用,主线程可以继续往下执行业务代码。
提升执行效率
在多核CPU环境下,多线程能更好地利用CPU资源,能一定程度地提升程序执行效率。
但是在单核CPU环境,多线程应用反而会因为线程上下文切换,额外耗费性能资源,影响了执行效率。
多线程创建/使用方式
继承 Thread 类
定义一个类继承Thread类
重写run()方法,编写线程具体执行代码
创建线程类对象,调用start()方法启动线程(注意线程不一定立即执行,CPU安排调度,商业头脑妄想:有什么办法能让CPU立即执行的线程?)
优势:
使用继承Thread类的方式创建多线程,编写简单,如果需要访问当前线程,则无需使用Thread.currentThread()方法,直接使用this即可获得当前线程。
缺点:
一个类一旦继承了Thread类之后,就不能再继承其他类了,所以,实际开发中一般不用这种方式。
实现代码:
public class TestThread01 extends Thread {
@Override
public void run() {
// 具体执行代码
int count = 100;
for (int i = 0; i < count; i++) {
// Thread.currentThread().getName() 获取执行方法线程的名称,比如main线程调用run()方法,获取到的线程名称是main线程的名称
System.out.println(Thread.currentThread().getName() + "-我发财啦-" + i);
// this.getName() 获取线程自己的名称
//System.out.println(this.getName() + " 报数:" + i);
}
}
public static void main(String[] args) {
// main线程,主线程
// 创建线程对象
TestThread01 tt1 = new TestThread01();
// 调用run()方法,相当于使用对象内方法,是按顺序执行
//tt1.run();
// 调用start()方法启动线程,等待CPU调度执行。start()底层start0()是native方法,Java本身不能开启线程。
tt1.start();
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "-喂!怎么还在睡?!赶快写代码!" + i);
}
}
}★实现 Runnable 接口
- 定义一个类实现Runnable接口
- 重写run()方法,编写线程具体执行代码
- 创建线程类对象,调用start()方法启动线程
优势:
避免Java单继承的局限性。
方便一个线程类对象被多个线程调用。

缺点:
实现代码:
public class TestThread02 implements Runnable {
// 重写run()方法
@Override
public void run() {
// 具体执行代码
for (int i = 0; i < 200; i++) {
System.out.println(Thread.currentThread().getName() + " 报数:" + i);
}
}
public static void main(String[] args) {
// 创建线程对象,通过线程对象开启线程,代理
// Thread t = new Thread(tt2);
// t.start();
// 创建Runnable接口实现类的对象
TestThread02 tt2 = new TestThread02();
// 方便一个线程类对象被多个线程调用
//new Thread(tt2).start();
//new Thread(tt2).start();
new Thread(tt2).start();
for (int i = 0; i < 1000; i++) {
System.out.println(Thread.currentThread().getName() + " 报数:" + i);
}
}
}/**
* 创建线程方式二解耦形式,实际开发使用
*/
public class TestThread0201 {
public static void main(String[] args) {
Thread0201 t = new Thread0201();
/*
new Thread(new Runnable() {
@Override
public void run() {
t.play();
}
}, "愉快玩耍").start();
*/
// lambda表达式简化写法
new Thread(() -> { // 只有一行代码,花括号也可以省略
t.play();
}, "愉快玩耍").start();
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + "-今日代码量(行):" + i);
}
}
}
/**
* 普通资源类
*/
class Thread0201 {
void play() {
for (int i = 0; i < 50; i++) {
System.out.println(Thread.currentThread().getName() + "-划水时间(分钟):" + i);
}
}
}★实现 Callable 接口
实现Callable接口,适用于需要返回值的场景
重写call()方法,抛出异常
创建目标对象
创建执行服务的线程池:ExecutorService esr = Executors.newFixedThreadPool(3);
提交执行:Future<Boolean> f1 = esr.submit(tt301);
获取结果:boolean r1 = f1.get();
关闭服务:esr.shutdownNow();
优势:
可以指定返回值
可以抛出异常
缺点:
- 实现原理比前两种方式复杂一些
实现代码:
public class TestThread03 implements Callable<Boolean> {
@Override
public Boolean call() throws Exception {
// 模拟锻炼2000步,方便查看,设置200
for (int i = 1; i <= 200; i++) {
System.out.println(Thread.currentThread().getName() + " 已经锻炼了 " + i + " 步。");
}
return true;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
TestThread03 tt301 = new TestThread03();
TestThread03 tt302 = new TestThread03();
TestThread03 tt303 = new TestThread03();
// 创建执行服务
ExecutorService esr = Executors.newFixedThreadPool(3);
// 提交执行
Future<Boolean> f1 = esr.submit(tt301);
Future<Boolean> f2 = esr.submit(tt302);
Future<Boolean> f3 = esr.submit(tt303);
// 获取结果
boolean r1 = f1.get();
boolean r2 = f2.get();
boolean r3 = f3.get();
// 打印结果
System.out.println(r1);
System.out.println(r2);
System.out.println(r3);
// 关闭服务
esr.shutdownNow();
}
}线程的状态
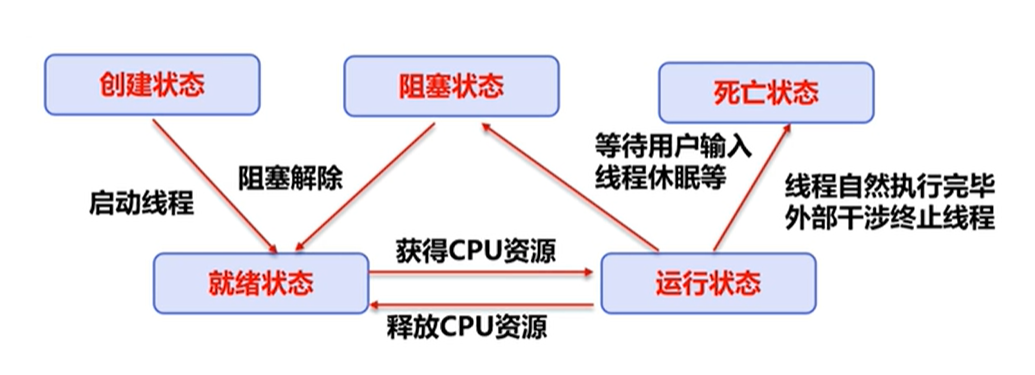
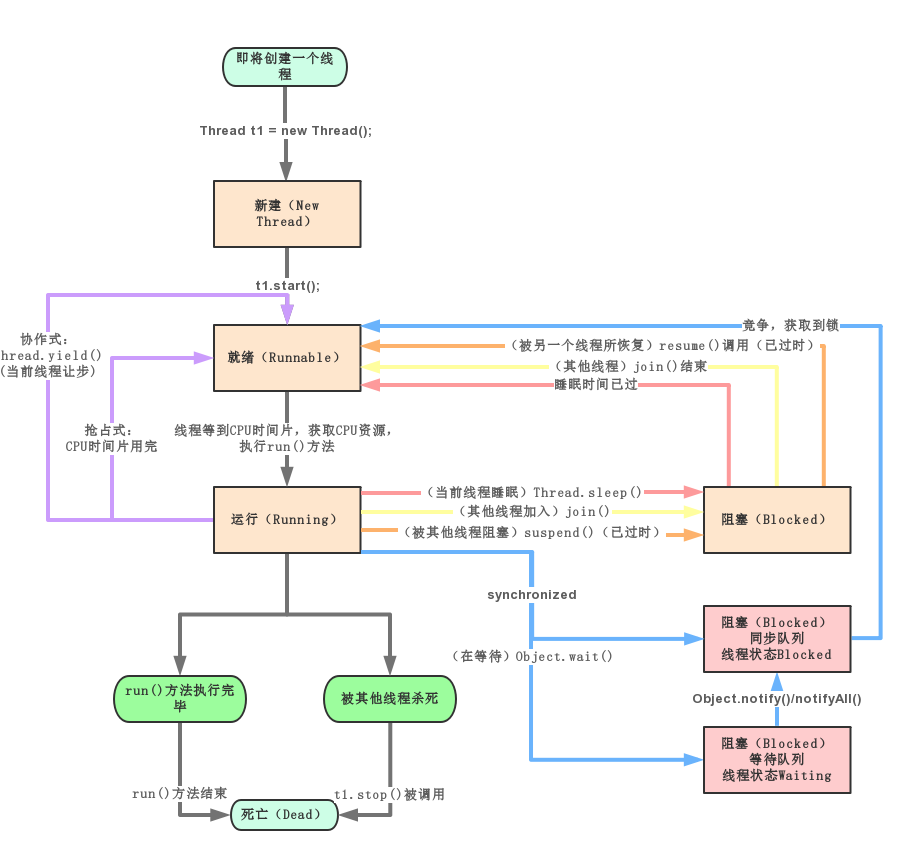
Thread类源码中的状态标识:
线程方法
主要常用方法:
| 方法 | 说明 |
|---|---|
| public void start() | 使该线程开始执行;Java 虚拟机调用该线程的 run 方法。 |
| public void run() | 如果该线程是使用独立的 Runnable 运行对象构造的,则调用该 Runnable 对象的 run 方法;否则,该方法不执行任何操作并返回。 |
| public final void setName(String name) | 改变线程名称,使之与参数 name 相同。 |
| public final void setPriority(int priority) | 更改线程的优先级。(执行顺序依然受CPU调度影响) |
| public final void setDaemon(boolean on) | 将该线程标记为守护线程或用户线程。 |
| public final void join(long millisec) | 等待该线程终止的时间最长为 millis 毫秒。 |
| public void interrupt() | 中断线程。(别用这个方式) |
| public final boolean isAlive() | 测试线程是否处于活动状态。 |
| public static void yield() | 暂停当前正在执行的线程对象,并执行其他线程。 |
| public static void sleep(long millisec) | 在指定的毫秒数内让当前正在执行的线程休眠(暂停执行),此操作受到系统计时器和调度程序精度和准确性的影响。 |
| public static boolean holdsLock(Object x) | 当且仅当当前线程在指定的对象上保持监视器锁时,才返回 true。 |
| public static Thread currentThread() | 返回对当前正在执行的线程对象的引用。 |
| public static void dumpStack() | 将当前线程的堆栈跟踪打印至标准错误流。 |
线程优先级
每一个 Java 线程都有一个优先级,这样有助于操作系统确定线程的调度顺序。
Java 线程的优先级是一个整数,其取值范围是 1 (Thread.MIN_PRIORITY ) - 10 (Thread.MAX_PRIORITY )。
默认情况下,每一个线程都会分配一个优先级 NORM_PRIORITY(5)。
具有较高优先级的线程对程序更重要,并且应该在低优先级的线程之前分配处理器资源。但是,线程优先级不能保证线程执行的顺序,而且非常依赖于系统平台。
public class TestThreadStop implements Runnable {
/** 线程是否停止标志,true-停止; **/
boolean stopFlag = false;
@Override
public void run() {
int i = 0;
while(!stopFlag) {
System.out.println(Thread.currentThread().getName() + "-" + i++);
}
}
private void stop() {
this.stopFlag = true;
}
public static void main(String[] args) {
TestThreadStop tts = new TestThreadStop();
new Thread(tts, "TestThreadStop").start();
for (int i = 0; i < 1000; i++) {
System.out.println(Thread.currentThread().getName() + "-" + i);
if (i == 900) {
// 调用自定义的停止方法
tts.stop();
System.out.println("TestThreadStop线程停止了。");
}
}
}
}基础线程机制
Executor 线程执行管理
Executor 管理多个异步任务的执行,而无需程序员显式地管理线程的生命周期。这里的异步是指多个任务的执行互不干扰,不需要进行同步操作。
主要有三种 Executor:
- CachedThreadPool: 一个任务创建一个线程;
- FixedThreadPool: 所有任务只能使用固定大小的线程;
- SingleThreadExecutor: 相当于大小为 1 的 FixedThreadPool。
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
executorService.execute(new MyRunnable());
}
executorService.shutdown();
}daemon 守护线程
Java线程分为用户线程和守护线程,默认用户线程
用户线程对象可以通过setDaemon(true)方法转换为守护线程
虚拟机必须确保用户线程执行完毕
虚拟机不用等待守护线程执行完毕(如,GC回收、日志记录、内存监控)
public class TestDaemonThread {
public static void main(String[] args) {
God god = new God();
You you = new You();
Thread godThread = new Thread(god, "God");
godThread.setDaemon(true);
godThread.start();
Thread youThread = new Thread(you, "You");
youThread.start();
}
}
class You implements Runnable {
@Override
public void run() {
for (int i = 1; i <= 36500; i++) {
System.out.println(">>>> 开心地活着第 " + i + " 天 >>>>");
}
System.out.println("====Goodbye world.====");
}
}
class God implements Runnable {
@Override
public void run() {
while (true) {
System.out.println("~~~~ 上帝守护着你 ~~~~");
}
}
}sleep() 线程休眠
sleep(millis)指定当前线程休眠的毫秒数。
sleep方法声明抛出InterruptedException中断异常。
sleep方法时间结束后线程进入就绪状态。
sleep方法可以模拟网络延时和模拟倒计时。
sleep方法不会释放锁资源,线程睡觉了,锁在Object对象那呢~
sleep是静态方法,最好不要用Thread的实例对象调用它,因为它睡眠的始终是当前正在运行的线程,而不是调用它的线程对象,它只对正在运行状态的线程对象有效。
public class Test1 {
public static void main(String[] args) throws InterruptedException {
System.out.println(Thread.currentThread().getName());
MyThread myThread=new MyThread();
myThread.start();
// 这里sleep的就是main线程,而非myThread线程
myThread.sleep(1000);
Thread.sleep(10);
for(int i=0;i<100;i++){
System.out.println("main"+i);
}
}
}yield() 线程礼让
将线程从运行状态转为就绪状态。
注意,礼让不一定成功。因为是 CPU 重新调度,可能还是先被调用。
public class TestThreadYield {
public static void main(String[] args) {
TestYield ty = new TestYield();
new Thread(ty, "a").start();
new Thread(ty, "b").start();
}
}
class TestYield implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 开始执行");
Thread.yield();
System.out.println(Thread.currentThread().getName() + " 执行结束");
}
}线程中断
一个线程执行完毕之后会自动结束,如果在运行过程中发生异常也会提前结束。
InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
对于以下代码,在 main() 中启动一个线程之后再中断它,由于线程中调用了 Thread.sleep() 方法,因此会抛出一个 InterruptedException,从而提前结束线程,不执行之后的语句。
public class InterruptExample {
private static class MyThread1 extends Thread {
@Override
public void run() {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}public static void main(String[] args) throws InterruptedException {
Thread thread1 = new MyThread1();
thread1.start();
thread1.interrupt();
System.out.println("Main run");
}Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at InterruptExample.lambda$main$0(InterruptExample.java:5)
at InterruptExample$$Lambda$1/713338599.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)interrupted()
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
public class InterruptExample {
private static class MyThread2 extends Thread {
@Override
public void run() {
while (!interrupted()) {
// ..
}
System.out.println("Thread end");
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread2 = new MyThread2();
thread2.start();
thread2.interrupt();
}
Thread endExecutor 的中断操作
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
以下使用 Lambda 创建线程,相当于创建了一个匿名内部线程。
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.shutdownNow();
System.out.println("Main run");
}Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at ExecutorInterruptExample.lambda$main$0(ExecutorInterruptExample.java:9)
at ExecutorInterruptExample$$Lambda$1/1160460865.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)如果只想中断 Executor 中的一个线程,可以通过使用 submit() 方法来提交一个线程,它会返回一个 Future<?> 对象,通过调用该对象的 cancel(true) 方法就可以中断线程。
Future<?> future = executorService.submit(() -> {
// ..
});
future.cancel(true);停止线程
JDK 自带的 stop() 和 destroy() 已经被标记 Deprecated,不推荐使用了。
停止线程的方式,建议自己设置一个标志位,用来判断是否结束线程。
public class TestThreadStop implements Runnable {
/** 线程是否停止标志,true-停止; **/
boolean stopFlag = false;
@Override
public void run() {
int i = 0;
while(!stopFlag) {
System.out.println(Thread.currentThread().getName() + "-" + i++);
}
}
private void stop() {
this.stopFlag = true;
}
public static void main(String[] args) {
TestThreadStop tts = new TestThreadStop();
new Thread(tts, "TestThreadStop").start();
for (int i = 0; i < 1000; i++) {
System.out.println(Thread.currentThread().getName() + "-" + i);
if (i == 900) {
// 调用自定义的停止方法
tts.stop();
System.out.println("TestThreadStop线程停止了。");
}
}
}
}线程不安全案例
- 加1
- 买票
- 取款
- List
/**
* 多线程对变量数值加1
* https://www.pdai.tech/md/java/thread/java-thread-x-theorty.html
*/
public class ThreadUnsafeExample {
private int cnt = 0;
public void add() {
cnt++;
}
public int get() {
return cnt;
}
}
public static void main(String[] args) throws InterruptedException {
final int threadSize = 1000;
ThreadUnsafeExample example = new ThreadUnsafeExample();
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < threadSize; i++) {
executorService.execute(() -> {
example.add();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println(example.get());
}
输出结果
997 // 结果总是小于1000/**
* 线程不安全的买票
*/
public class UnsafeBuyTickets implements Runnable {
private int ticketsSum = 10;
@Override
public void run() {
while(true) {
if (ticketsSum <= 0) {
break;
}
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 抢到了第 " + ticketsSum-- + " 张票。");
}
}
public static void main(String[] args) {
UnsafeBuyTickets rtt = new UnsafeBuyTickets();
new Thread(rtt, "小明").start();
new Thread(rtt, "小红").start();
new Thread(rtt, "小牛").start();
}
}/**
* 线程不安全的取款
*/
public class UnsafeBank {
public static void main(String[] args) {
// 创建用户
Account ac = new Account(new BigDecimal("10000.00"), "小明");
System.out.println(ac);
// 你要取的钱
BigDecimal money1 = new BigDecimal("1000");
Withdraw wd1 = new Withdraw(ac, money1);
new Thread(wd1, "你").start();
// 你女朋友要取的钱
BigDecimal money2 = new BigDecimal("10000");
Withdraw wd2 = new Withdraw(ac, money2);
new Thread(wd2, "你女朋友").start();
}
}
class Withdraw implements Runnable {
private Account account;
private BigDecimal money;
public Withdraw(Account account, BigDecimal money) {
this.account = account;
this.money = money;
}
public Account getAccount() {
return account;
}
public void setAccount(Account account) {
this.account = account;
}
public BigDecimal getMoney() {
return money;
}
public void setMoney(BigDecimal money) {
this.money = money;
}
@Override
public String toString() {
return "Withdraw{" +
"account=" + account +
", money=" + money +
'}';
}
@Override
public void run() {
// 省略校验用户信息阶段
// 判断余额
if (account.getBalance().compareTo(money) < 0) {
System.out.println(Thread.currentThread().getName() + "-当前账户余额不足!");
return;
}
// 模拟延时
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 取款
System.out.println(account);
account.setBalance(account.getBalance().subtract(money));
System.out.println(Thread.currentThread().getName() + "-取款:" + money);
// 显示余额
System.out.println(Thread.currentThread().getName() + "-当前账户余额:" + account.getBalance());
}
}
class Account {
private BigDecimal balance;
private String name;
public Account(BigDecimal balance, String name) {
this.balance = balance;
this.name = name;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/*@Override
public String toString() {
return "Account{" +
"balance=" + balance +
", name='" + name + '\'' +
'}';
}*/
}/**
* 线程不安全的List
*/
public class UnsafeList {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
list.add(Thread.currentThread().getName());
}).start();
}
System.out.println(list.size());
}
}并发出现问题的根源: 并发三要素
https://www.pdai.tech/md/java/thread/java-thread-x-theorty.html
- CPU 增加了缓存,以均衡与内存的速度差异;// 导致
可见性问题- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;// 导致
原子性问题- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。// 导致
有序性问题
可见性: CPU缓存引起
可见性:一个线程对共享变量的修改,另外一个线程能够立刻看到。
举个简单的例子,看下面这段代码:
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
原子性: 分时复用引起
原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
经典的转账问题:比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。
试想一下,如果这2个操作不具备原子性,会造成什么样的后果。假如从账户A减去1000元之后,因为出错异常中止,这样就会导致账户A虽然减去了1000元,但是账户B没有收到这个转过来的1000元。
所以这2个操作必须要具备原子性才能保证不出现一些意外的问题。
有序性: 重排序引起
有序性:即程序执行的顺序按照代码的先后顺序执行。举个简单的例子,看下面这段代码:
int i = 0;
boolean flag = false;
i = 1; //语句1
flag = true; //语句2上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗? 不一定,为什么呢? 这里可能会发生指令重排序(Instruction Reorder)。
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读 / 写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

上述的 1 属于编译器重排序,2 和 3 属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。对于编译器,JMM 的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM 的处理器重排序规则会要求 java 编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel 称之为 memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
JAVA是怎么解决并发问题的: JMM(Java内存模型)
理解的第一个维度:核心知识点
JMM本质上可以理解为,Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括:
- volatile、synchronized 和 final 三个关键字
- Happens-Before 8 个规则
理解的第二个维度:可见性,有序性,原子性
线程活跃性
死锁
**指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。**此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
个人理解:两个或多个线程彼此持有一把不同的锁,但是自己持有的锁还没释放又想要其他线程的锁,相互僵持等待,导致程序无响应。
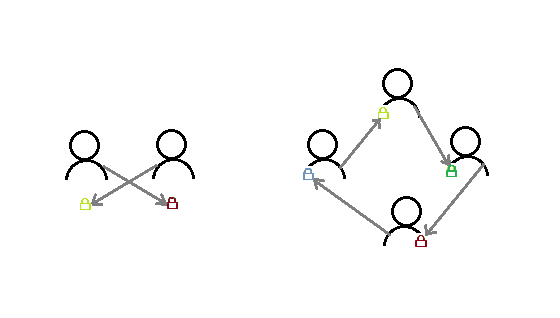
死锁发生的条件:
互斥条件:线程对资源的访问是排他性的,如果一个线程对占用了某资源,那么其他线程必须处于等待状态,直到资源被释放。
请求和保持条件:线程T1至少已经保持了一个资源R1占用,但又提出对另一个资源R2请求,而此时,资源R2被其他线程T2占用,于是该线程T1也必须等待,但又对自己保持的资源R1不释放。
不剥夺条件:线程已获得的资源,在未使用完之前,不能被其他线程剥夺,只能在使用完以后由自己释放。
环路等待条件:在死锁发生时,必然存在一个“进程-资源环形链”,即:{p0,p1,p2,...pn},进程p0(或线程)等待p1占用的资源,p1等待p2占用的资源,pn等待p0占用的资源。(最直观的理解是,p0等待p1占用的资源,而p1而在等待p0占用的资源,于是两个进程就相互等待)。
避免死锁的方法:
获得了锁,就先把锁范围内的事情做完,完事把锁释放了,再想获取其他的锁做其他的事情。别吃着碗里的看着锅里的,吃相很难看。
/**
* 程序死锁
*/
public class TestDeadLock {
public static void main(String[] args) {
MobilePhone doThing = new MobilePhone(0);
MobilePhone doThing2 = new MobilePhone(1);
new Thread(doThing, "事情1").start();
new Thread(doThing2, "事情2").start();
}
}
class MobilePhone implements Runnable {
// static 让需要的资源对象只有一个
static PlayGame playGame = new PlayGame();
static Shopping shopping = new Shopping();
int choice;
public MobilePhone(int choice) {
this.choice = choice;
}
@Override
public void run() {
doThing();
}
void doThing() {
if (choice == 0) { // 玩游戏
synchronized(playGame) {
System.out.println(Thread.currentThread().getName() + "-玩一局王者吧~~~");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized(shopping) {// 玩着玩着,好气哦,突然想到还要网购
System.out.println(Thread.currentThread().getName() + "-网购买生活必须品要紧。。。");
}
}
} else { // 购物
synchronized(shopping) {
System.out.println(Thread.currentThread().getName() + "-网购买生活必须品先~~~");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized(playGame) {// 套路太多,没钱了,不买立省百分比
System.out.println(Thread.currentThread().getName() + "-玩一局王者吧。。。");
}
}
}
}
}
class PlayGame {
}
class Shopping {
}// 避免死锁
void doThingRight() {
if (choice == 0) { // 玩游戏
synchronized(playGame) {
System.out.println(Thread.currentThread().getName() + "-玩一局王者吧~~~");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
synchronized(shopping) {// 玩着玩着,好气哦,突然想到还要网购
System.out.println(Thread.currentThread().getName() + "-网购买生活必须品要紧。。。");
}
} else { // 购物
synchronized(shopping) {
System.out.println(Thread.currentThread().getName() + "-网购买生活必须品先~~~");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
synchronized(playGame) {// 套路太多,没钱了,不买立省百分比
System.out.println(Thread.currentThread().getName() + "-玩一局王者吧。。。");
}
}
}活锁
是指线程1可以使用资源,但它很礼貌,让其他线程先使用资源,线程2也可以使用资源,但它很绅士,也让其他线程先使用资源。这样你让我,我让你,最后两个线程都无法使用资源。
关于“死锁与活锁”的比喻:
死锁:迎面开来的汽车A和汽车B过马路,汽车A得到了半条路的资源(满足死锁发生条件1:资源访问是排他性的,我占了路你就不能上来,除非你爬我头上去),汽车B占了汽车A的另外半条路的资源,A想过去必须请求另一半被B占用的道路(死锁发生条件2:必须整条车身的空间才能开过去,我已经占了一半,尼玛另一半的路被B占用了),B若想过去也必须等待A让路,A是辆兰博基尼,B是开奇瑞QQ的屌丝,A素质比较低开窗对B狂骂:快给老子让开,B很生气,你妈逼的,老子就不让(死锁发生条件3:在未使用完资源前,不能被其他线程剥夺),于是两者相互僵持一个都走不了(死锁发生条件4:环路等待条件),而且导致整条道上的后续车辆也走不了。
活锁:马路中间有条小桥,只能容纳一辆车经过,桥两头开来两辆车A和B,A比较礼貌,示意B先过,B也比较礼貌,示意A先过,结果两人一直谦让谁也过不去。
饥饿
是指如果线程T1占用了资源R,线程T2又请求封锁R,于是T2等待。T3也请求资源R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求......,T2可能永远等待。
也就是,如果一个线程因为CPU时间全部被其他线程抢走而得不到CPU运行时间,这种状态被称之为“饥饿”。而该线程被“饥饿致死”正是因为它得不到CPU运行时间的机会。
关于“饥饿”的比喻:
在“首堵”北京的某一天,天气阴沉,空气中充斥着雾霾和地沟油的味道,某个苦逼的临时工交警正在处理塞车,有两条道A和B上都堵满了车辆,其中A道堵的时间最长,B相对堵的时间较短,这时,前面道路已疏通,交警按照最佳分配原则,示意B道上车辆先过,B道路上过了一辆又一辆,A道上排队时间最长的却没法通过,只能等B道上没有车辆通过的时候再等交警发指令让A道依次通过,这也就是ReentrantLock显示锁里提供的不公平锁机制(当然了,ReentrantLock也提供了公平锁的机制,由用户根据具体的使用场景而决定到底使用哪种锁策略),不公平锁能够提高吞吐量但不可避免的会造成某些线程的饥饿。
导致线程饥饿的常见原因:
高优先级线程吞噬所有的低优先级线程的CPU时间
你能为每个线程设置独自的线程优先级,优先级越高的线程获得的CPU时间越多,线程优先级值设置在1到10之间,而这些优先级值所表示行为的准确解释则依赖于你的应用运行平台。对大多数应用来说,你最好是不要改变其优先级值。
线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之前持续地对该同步块进行访问
Java的同步代码区也是一个导致饥饿的因素。Java的同步代码区对哪个线程允许进入的次序没有任何保障。这就意味着理论上存在一个试图进入该同步区的线程处于被永久堵塞的风险,因为其他线程总是能持续地先于它获得访问,这即是“饥饿”问题,而一个线程被“饥饿致死”正是因为它得不到CPU运行时间的机会。
线程在等待一个本身(在其上调用wait())也处于永久等待完成的对象,因为其他线程总是被持续地获得唤醒
如果多个线程处在wait()方法执行上,而对其调用notify()不会保证哪一个线程会获得唤醒,任何线程都有可能处于继续等待的状态。因此存在这样一个风险:一个等待线程从来得不到唤醒,因为其他等待线程总是能被获得唤醒。
解决饥饿的方案被称之为“公平性” – 即所有线程均能公平地获得运行机会。
在Java中实现公平性方案,需要:
使用Lock锁,而不是synchronized同步;
设置使用公平锁;
注意可能出现性能问题,10min、1s。
★线程协作/顺序控制
join
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。
可以理解为插队。
public class TestThreadJoin {
public static void main(String[] args) {
TestJoin tj = new TestJoin();
Thread t = new Thread(tj, "TestThreadJoin");
t.start(); // 这里开启线程后,CPU随时可以调度执行,不一定要等到main线程执行到50才开始执行
for (int i = 1; i <= 100; i++) {
System.out.println(Thread.currentThread().getName() + "-正在排队:" + i);
if (i == 50) {
try {
// 突然有人来插队
t.join(); // main线程会阻塞
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
class TestJoin implements Runnable {
@Override
public void run() {
for (int i = 1; i <= 100; i++) {
System.out.println(Thread.currentThread().getName() + "-VIP来插队了-" + i);
}
}
}wait/notify/notifyAll
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
它们都属于 Object 的一部分,而不属于 Thread。
只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateExeception。
使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
wait、notify、notifyAll 为什么需要放在 synchronized 同步代码块中?
因为 wait 阻塞线程要释放锁资源,前提得获得锁;notify 唤醒线程,也需要线程同步。(自己理解的,感觉有些浅显)
wait() 和 sleep() 的区别
- wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
- wait() 会释放锁,sleep() 不会。
启动两个线程, 一个输出 1,3,5,7…99, 另一个输出 2,4,6,8…100 最后 STDOUT 中按序输出 1,2,3,4,5…100
TIP
别一开始就想要把实现代码写得很完美,各种高级炫技,这是在写笔试题啊,追求这么完美,最后只会导致其他题目没有时间做,甚至这一题都写不完!产品市场也一样,真要把产品做到百分之八十以上的完美程度,市场早就被别人占据了!
题目要求用 Java 的 wait + notify 机制来实现,重点考察对于多线程可见性的理解。
package cn.m1yellow.threads.cooperation;
/**
* wait、notify、synchronized
* 启动两个线程, 一个输出 1,3,5,7…99, 另一个输出 2,4,6,8…100 最后 STDOUT 中按序输出 1,2,3,4,5…100
*/
public class Coop01 {
/**
* 事实上,除了匿名内部类内部,方法和作用域内的内部类内部使用的外部变量也必须是 final 的。
* 原因如下:内部类会自动拷贝外部变量的引用,为了避免:
* 1.外部方法修改引用,而导致内部类得到的引用值不一致
* 2.内部类修改引用,而导致外部方法的参数值在修改前和修改后不一致。于是就用 final 来让该引用不可改变。
* 至于这是基于语法上的考虑还是由于实现机制上的限制,我就没有继续考究了。
* https://www.zhihu.com/question/21395848/answer/39841533
*/
private final Object lockObj = new Object();
public static void main(String[] args) {
// 创建线程实例对象
Coop01 coop01 = new Coop01();
Thread threadA = coop01.new ThreadA();
Thread threadB = coop01.new ThreadB();
// 开启线程
// TODO 是否存在 threadB 先被 CPU 调用执行的情况呢?synchronized 只有非公平锁,理论上存在这种问题
threadA.start();
//threadA.join(); // 使用 join 保证执行顺序
threadB.start();
//threadB.join();
}
class ThreadA extends Thread {
@Override
public void run() {
synchronized (lockObj) {
for (int i = 1; i <= 100; i += 2) {
lockObj.notify();
System.out.println(i);
try {
lockObj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
class ThreadB extends Thread {
@Override
public void run() {
synchronized (lockObj) {
for (int i = 2; i <= 100; i += 2) {
lockObj.notify();
System.out.println(i);
if (i == 100) break;
try {
lockObj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
}await/signal/signalAll
java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
使用 Lock 来获取一个 Condition 对象。
编写两个线程,一个线程打印1-52,另一个线程打印字母A-Z,打印顺序为12A34B56C...5152Z,要求使用线程间的通信。
AABAABAAB
AAAABBAAAABB
使用 Lock 及 condition 的 await/signal
package cn.m1yellow.threads.cooperation;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 编写两个线程,一个线程打印1-52,另一个线程打印字母A-Z,打印顺序为12A34B56C...5152Z,要求使用线程间的通信。
* Lock、condition 的 await/signal
*/
public class Coop02 {
private final Lock lock = new ReentrantLock(true);
private final Condition condition = lock.newCondition();
public static void main(String[] args) {
// 创建线程实例对象
Coop02 coop02 = new Coop02();
ThreadA threadA = coop02.new ThreadA();
ThreadB threadB = coop02.new ThreadB();
// 启动线程
new Thread(() -> threadA.print(), "threadA").start();
new Thread(() -> threadB.print(), "threadB").start();
}
class ThreadA {
public void print() {
for (int i = 1; i <= 52; i++) {
try {
lock.lock();
condition.signal();
System.out.print(i);
if (i % 2 == 0 && i != 52) {
condition.await();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
class ThreadB {
public void print() {
for (int i = 0; i < 26; i++) {
try {
lock.lock();
condition.signal();
System.out.print((char) (65 + i));
if (i != 25) {
condition.await();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
}park/unpark
volatile
就使用一个 volatile 变量
原理是保证多线程变量可见性。
package cn.m1yellow.threads.cooperation;
/**
* 编写两个线程,一个线程打印1-52,另一个线程打印字母A-Z,打印顺序为12A34B56C...5152Z,要求使用线程间的通信。
* 就使用一个 volatile 变量
*/
public class Coop03 {
private volatile int threadNum = 1;
public static void main(String[] args) {
// 创建线程实例对象
Coop03 coop02 = new Coop03();
ThreadA threadA = coop02.new ThreadA();
ThreadB threadB = coop02.new ThreadB();
// 启动线程,注意线程调度执行顺序并不一定是先A后B,还是需要使用 join 确保线程执行顺序
new Thread(() -> threadA.print(), "threadA").start();
new Thread(() -> threadB.print(), "threadB").start();
}
class ThreadA {
public void print() {
for (int i = 1; i <= 52; i++) {
while (threadNum == 2) {}
System.out.print(i);
if (i % 2 == 0) threadNum = 2;
}
}
}
class ThreadB {
public void print() {
for (int i = 0; i < 26; i++) {
while (threadNum == 1) {}
System.out.print((char) (65 + i));
threadNum = 1;
}
}
}
}AtomicInteger
使用 AtomicInteger
原理是底层使用原子操作,保证线程安全
package cn.m1yellow.threads.cooperation;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 编写两个线程,一个线程打印1-52,另一个线程打印字母A-Z,打印顺序为12A34B56C...5152Z,要求使用线程间的通信。
* 使用 AtomicInteger
*/
public class Coop04 {
private AtomicInteger threadNum = new AtomicInteger(1);
public static void main(String[] args) {
// 创建线程实例对象
Coop04 coop02 = new Coop04();
ThreadA threadA = coop02.new ThreadA();
ThreadB threadB = coop02.new ThreadB();
// 启动线程
new Thread(() -> threadA.print(), "threadA").start();
new Thread(() -> threadB.print(), "threadB").start();
}
class ThreadA {
public void print() {
for (int i = 1; i <= 52; i++) {
while (threadNum.get() == 2) {}
System.out.print(i);
if (i % 2 == 0) threadNum.set(2);
}
}
}
class ThreadB {
public void print() {
for (int i = 0; i < 26; i++) {
while (threadNum.get() == 1) {}
System.out.print((char) (65 + i));
threadNum.set(1);
}
}
}
}生产者消费者
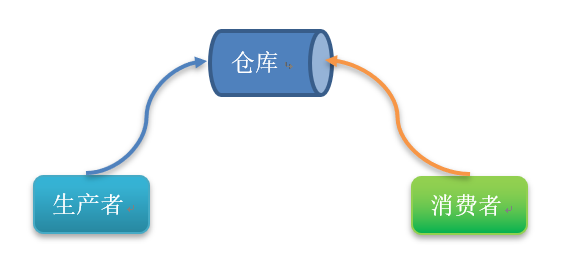
/**
* 生产者-消费者
*/
public class ProducterCustomer {
public static void main(String[] args) {
// KFC订单系统,一个店使用一个订单系统
KFCSystem sys = new KFCSystem(new ConcurrentLinkedQueue<>());
// 俩店员
Producter p1 = new Producter(1, sys);
Producter p2 = new Producter(2, sys);
// 店员工作
new Thread(p1, "店员" + p1.producterNo).start();
new Thread(p2, "店员" + p2.producterNo).start();
// 来顾客了
Customer c1 = new Customer(1, 1, sys);
Customer c2 = new Customer(2, 3, sys);
new Thread(c1, "顾客" + c1.orderNo).start();
new Thread(c2, "顾客" + c2.orderNo).start();
}
}
/**
* 生产者-店员,可以有多个店员
*/
class Producter implements Runnable {
int producterNo;
KFCSystem sys;
public Producter(int producterNo, KFCSystem sys) {
this.producterNo = producterNo;
this.sys = sys;
}
@Override
public void run() {
Customer c;
while (true) {
c = sys.serving();
if (c != null) { // 有订单
System.out.println(Thread.currentThread().getName() + ":哟!来单啦!!!");
making(c);
} else { // 没订单,就等呗
System.out.println(Thread.currentThread().getName() + ":啊,怎么没客人啊~~~");
sys.waiting();
}
}
}
/**
* 制作
*/
private void making(Customer c) {
// 模拟制作耗时
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 制作完成,通知对应订单号的顾客取餐
sys.notifyFinish(c);
}
}
/**
* 消费者-顾客,顾客很多
*/
class Customer implements Runnable {
int orderNo;
int orderNum;
KFCSystem sys;
public Customer(int orderNo, int orderNum, KFCSystem sys) {
this.orderNo = orderNo;
this.orderNum = orderNum;
this.sys = sys;
}
@Override
public void run() {
ordering();
}
/**
* 下单
*/
private void ordering() {
// 下单
sys.ordering(this);
// 系统通知店员有新订单
sys.notifyMaking();
// 用户下完单后,在座位上等待通知取餐
synchronized(this) {
System.out.println(Thread.currentThread().getName() + "-等待取餐。");
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + "-取餐 " + this.orderNum + " 份。");
}
}
/**
* 肯德基操作台系统
* 炸鸡桶,现吃现做
*/
class KFCSystem {
/**
* 炸鸡桶订单
**/
ConcurrentLinkedQueue<Customer> orders;
public KFCSystem(ConcurrentLinkedQueue<Customer> orders) {
this.orders = orders;
}
/**
* 下单
*/
void ordering(Customer c) {
orders.offer(c);
}
/**
* 取单
*/
Customer serving(){
return orders.poll();
}
/**
* 下单后通知店员制作
*/
synchronized void notifyMaking() {
this.notifyAll();
}
/**
* 制作完成,通知取餐
*/
void notifyFinish(Customer c) {
synchronized(c) {
c.notify(); // notify为什么要同步?
}
}
/**
* 没顾客,系统等待下单
*/
synchronized void waiting() {
try {
this.wait(); // wait为什么要同步?
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}四大函数式接口
新时代的程序员:lambda表达式、链式编程、函数式接口、Stream流式计算
传统程序员:泛型、枚举、反射
函数式接口:只有一个抽象方法的接口,接口内其他成员不限制。
java.util.function
Interface Function<T,R> 函数式接口:有一个输入参数,有一个输出
Interface Supplier<T> 供给型接口:没有参数,只有返回值
Interface Consumer<T> 消费型接口:只有输入,没有返回值
Interface Predicate<T> 断定型接口:有一个输入参数,返回值只能是布尔值
Interface Function<T,R>
Interface Supplier<T>
Interface Consumer<T>
Interface Predicate<T>
Stream 流式计算
Stream是对集合功能的增强,它提供了各种非常便利、高效的聚合操作,可以大批量数据操作,同时再结合Lambda表达式,就可以极大的提高编程效率。
Stream的API提供了串行和并行两种模式进行操作数据。
Stream操作分为中间操作或者最终操作两种:
中间操作,返回Stream本身,这样就可以将多个操作依次串起来例如,map、flatMap、filter、distinct、sorted、peek、limit、skip、parallel、sequential、unordered
最终操作,返回一特定类型的计算结果例如,forEach、forEachOrdered、toArray、reduce、collect、min、max、count、anyMatch、allMatch、noneMatch、findFirst、findAny、iterator
/**
* jdk1.8 Stream流式计算
*
*/
public class TestStream {
public static void main(String[] args) {
List<StreamUser> userList = new ArrayList<>();
userList.add(new StreamUser(1, "小博",19));
userList.add(new StreamUser(1, "小博",19));
userList.add(new StreamUser(2, "小南",21));
userList.add(new StreamUser(3, "小龙",22));
userList.add(new StreamUser(4, "小蜜",17));
userList.add(new StreamUser(5, "小菲",18));
userList.add(new StreamUser(5, "小菲",18));
//userList.stream().distinct().filter(u -> {return u.age < 20;}).sorted().forEach(System.out::println);
userList.stream().distinct().filter(u -> u.age < 20).sorted().forEach(System.out::println);
userList.stream().distinct().map(u -> u.id).collect(Collectors.toList()).forEach(System.out::println);
}
}
class StreamUser implements Comparable<StreamUser> {
long id;
String name;
int age;
public StreamUser(long id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "StreamUser{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
StreamUser that = (StreamUser) o;
return id == that.id &&
age == that.age &&
name.equals(that.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name, age);
}
@Override
public int compareTo(StreamUser o) {
return this.age - o.age;
}
}二、★JMM 内存模型
JMM,全名为Java Memory Model,即Java内存模型。它是一组规范,需要各个JVM的实现来遵守JMM规范,它屏蔽了各种硬件和操作系统的内存访问差异,以实现Java程序在各个平台下都能达到一致的内存访问效果。不像C/C++那样直接访问物理硬件和操作系统的内存模型,它的主要目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码重排序、处理器会对代码乱序执行等带来的问题。可以保证并发编程场景中的原子性、可见性和有序性。
它有利于开发者可以利用这些规范,更方便地开发多线程程序。如果没有这样的JMM内存模型来规范,那么很可能经过了不同JVM的不同规则的重排序之后,导致不同的虚拟机上运行的结果不一样。
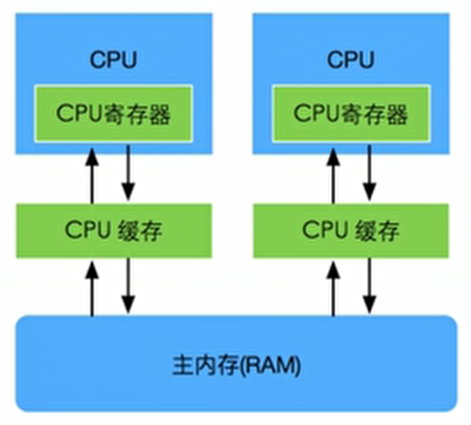
Java 线程模型结构
CPU 缓存模型示意图
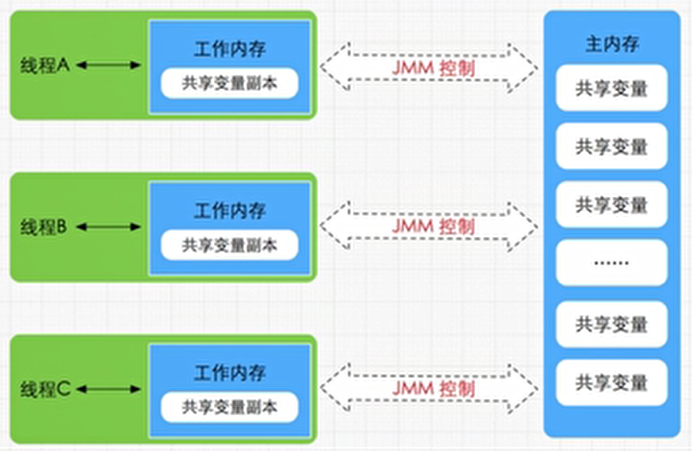
Java 多线程内存模型示意图
volatile 缓存一致性协议
JMM 数据原子操作
read(读取):从主内存读取数据。
load(载入):将主内存读取到的数据写入工作内存。
use(使用):从工作内存读取数据来计算。
assign(赋值):将计算好的值重新赋值到工作内存中。
store(存储):将工作内存数据传回主内存。
write(写入):将store变量值赋值给主内存中的变量。
lock(锁定):将主内存变量加锁,并标识为线程独占状态。
unlock(解锁):将主内存变量解锁,解锁后的变量才可以被其他线程锁定。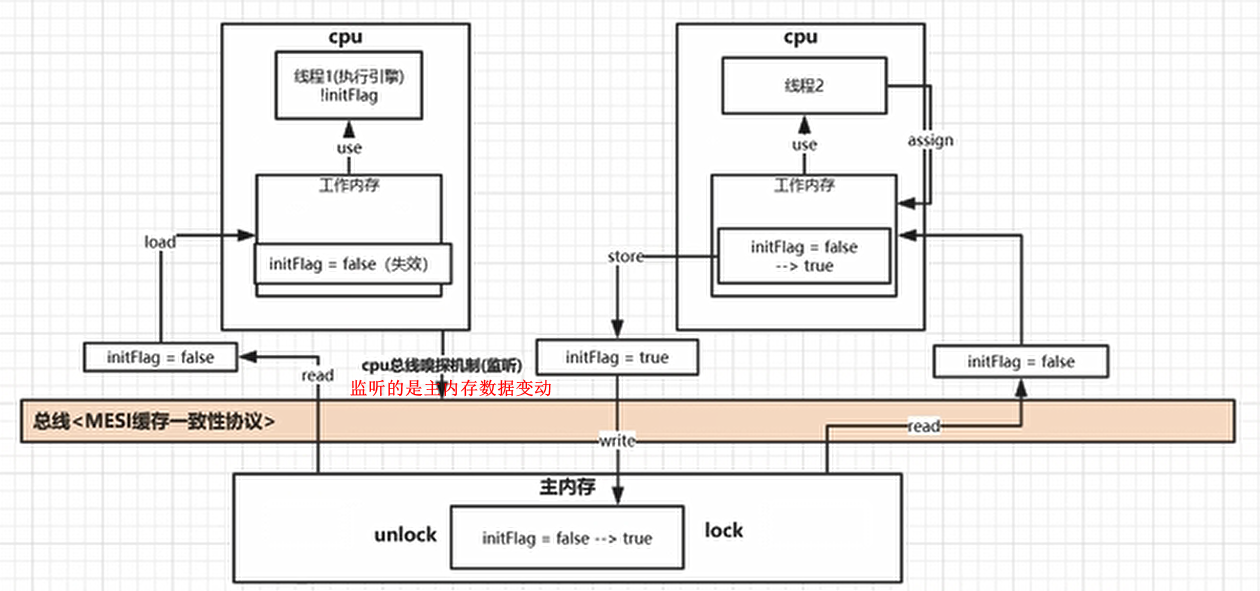
案例代码
volatile 底层原理
主要通过汇编lock前缀指令,它会锁定这块内存区域的缓存(缓存行锁定)并回写到主存,IA-32和Intel64架构软件开发者手册对lock指令的解释如下:
会将当前处理器缓存行的数据立即写回到系统内存。
这个写回内存的操作会引起其他cpu里缓存了该内存地址的数据无效(MESI协议)。
提供内存屏障功能,使lock前后指令不能重排序。
汇编代码
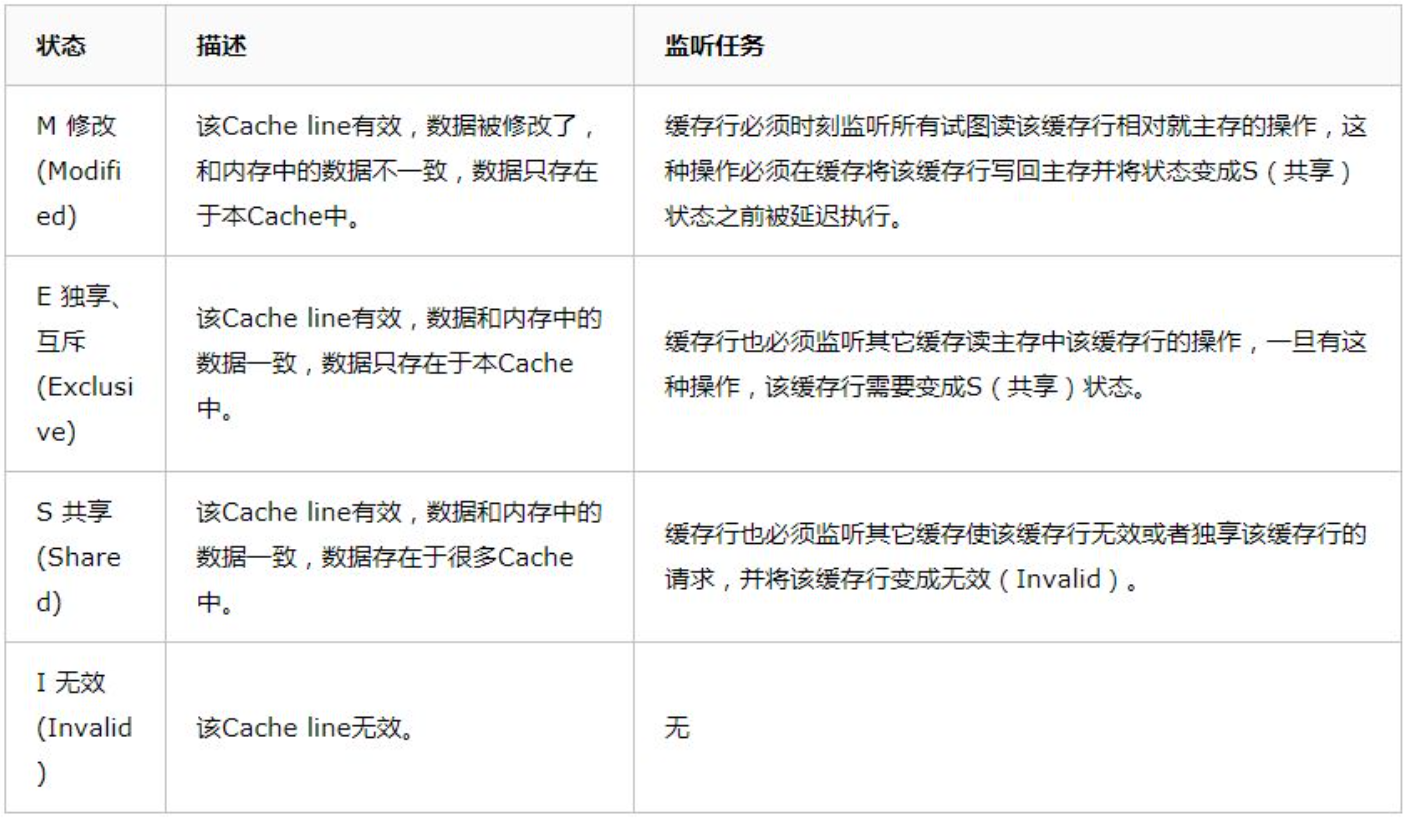
多核CPU多级缓存一致性协议MESI(CPU级别)
https://cloud.tencent.com/developer/article/1462257
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱?
注意:
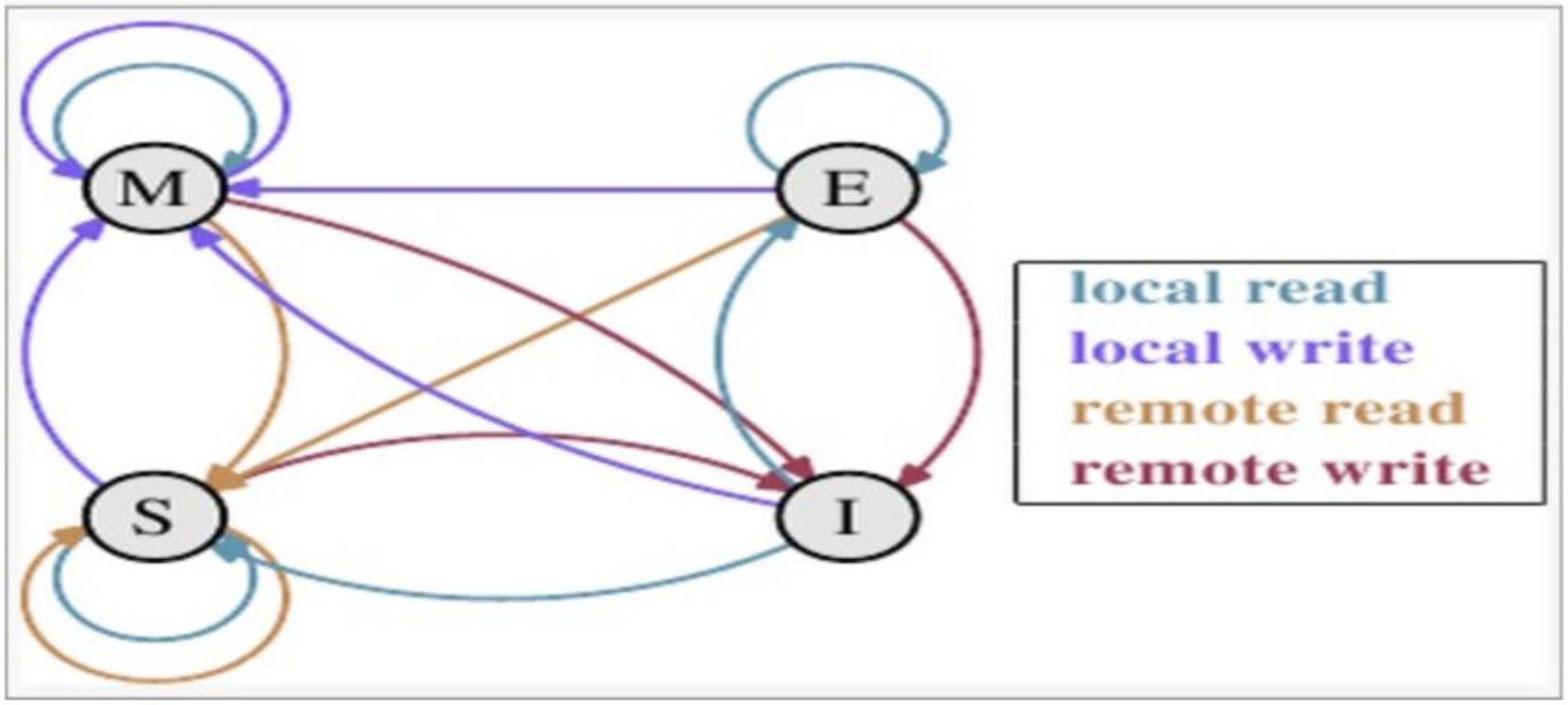
对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。
可见性、原子性、有序性
可见性
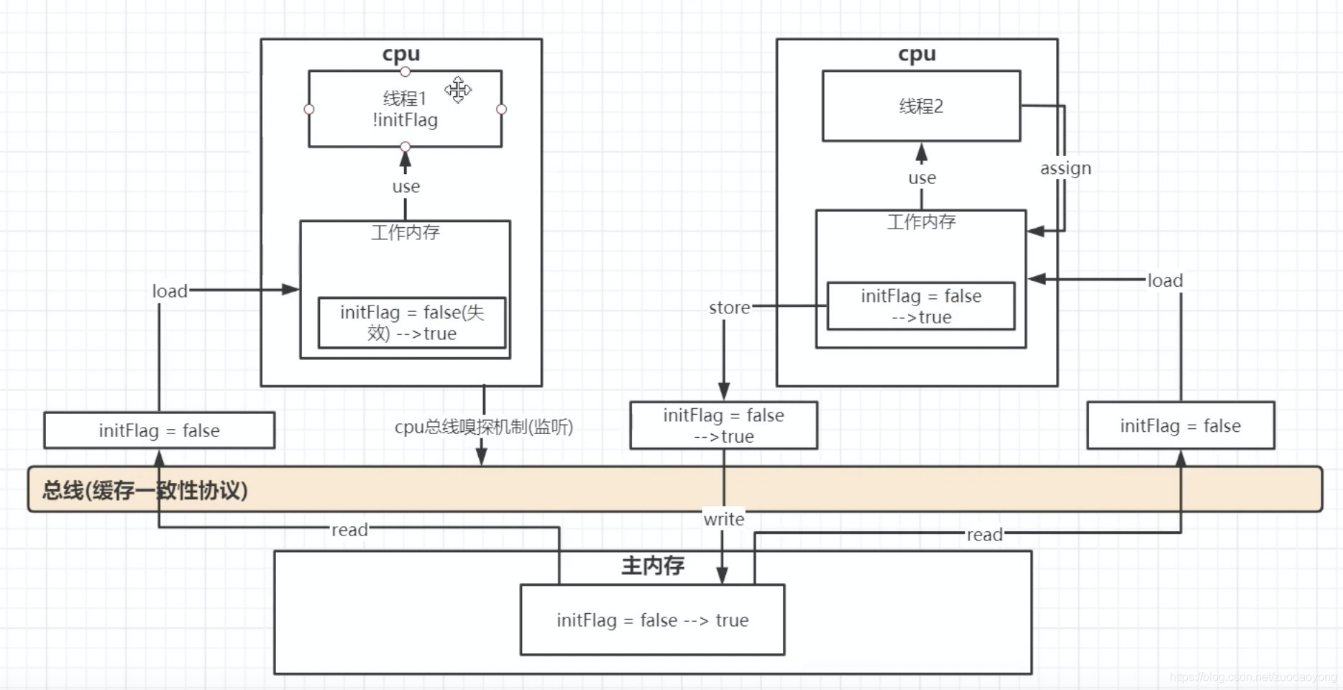
指的是多线程对共享变量修改的可见性。当一个线程修改了共享变量的值,其他线程能够立刻得知这个修改。
线程缓存导致的可见性问题
如果两个或者更多的线程在没有正确的使用volatile声明或者同步的情况下共享一个对象,一个线程更新这个共享对象可能对其它线程来说是不可见的:共享对象被初始化在主存中。跑在CPU上的一个线程将这个共享对象读到CPU缓存中,然后修改了这个对象。只要CPU缓存没有被刷新会主存,对象修改后的版本对跑在其它CPU上的线程都是不可见的。这种方式可能导致每个线程拥有这个共享对象的私有拷贝,每个拷贝停留在不同的CPU缓存中。
线程缓存导致的内存可见性问题处理方案:
使用volatile关键字:volatile关键字可以保证直接从主存中读取一个变量,如果这个变量被修改后,总是会被写回到主存中去。Java内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值这种依赖主内存作为传递媒介的方式来实现可见性的,无论是普通变量还是volatile变量都是如此,普通变量与volatile变量的区别是:volatile的特殊规则保证了新值能立即同步到主内存,以及每个线程在每次使用volatile变量前都立即从主内存刷新。因此可以说volatile保证了多线程操作时变量的可见性,而普通变量则不能保证这一点。
使用synchronized关键字:同步块的可见性是由“如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值”、“对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store和write操作)”这两条规则获得的。
使用final关键字:final关键字的可见性是指,被final修饰的字段在构造器中一旦被初始化完成,并且构造器没有把“this”的引用传递出去(this引用逃逸是一件很危险的事情,其他线程有可能通过这个引用访问到“初始化了一半”的对象),那么在其他线程就能看见final字段的值(无须同步)。
指令重排导致的可见性问题
指令重排不会影响单线程执行结果,但是却可能影响多线程的执行结果。
指令重排导致的可见性问题处理方案:
Java语言提供了volatile和synchronized两个关键字来保证线程之间操作的有序性:
volatile关键字使用内存屏障实现禁止处理器指令重排序。
synchronized则是由“一个变量在同一个时刻只允许一条线程对其进行lock操作”这条规则获得的,这个规则决定了持有同一个锁的两个同步块只能串行地进入。
原子性
指一个操作或一组操作是按原子的方式执行的。要么该操作不被执行,要么以原子方式执行,即执行过程中不会被其它线程中断。
Java中的原子操作:
除long和double之外的基本类型的读写操作。
所有引用类型的读写操作,不管是32位机器还是64位机器。
声明为volatile的类型变量读写操作。
synchronized关键字同步的代码。
java.concurrent.Atomic.* 包中所有类的原子操作。
关于long和double的原子性补充:
在官方文档中,对于64位值的写入可以分为两个32位的操作进行写入。但由于目前各种平台下的商用虚拟机几乎都选择把64位数据的读写操作作为原子操作来对待,因此在编写代码时一般也不需要将用到的long和double变量专门声明为volatile。
如果应用场景需要一个更大范围的原子性保证,需要使用同步块技术。Java内存模型提供了lock和unlock操作来满足这种需求。虚拟机提供了字节码指令monitorenter和monitorexist来隐式地使用这两个操作,这两个字节码指令反映到Java代码中就是同步快——synchronized关键字。
注意:
原子操作+原子操作 !=原子操作。
对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性,因为本质上volatile++是读、写两次操作。
有序性
代码从编写到最终被CPU执行,代码执行的指令顺序跟代码逻辑顺序通常都是不一致的,你看到的代码顺序不一定就是CPU执行的顺序。
代码编写完成后,期间经过解释器解释、编译器编译及处理器指令优化后,单线程执行结果不会有影响。但是在多线程环境下,代码执行的结果可能超出预期逻辑,出现不可预知的结果,这是不期望的执行结果。
怎样保证有序性?
参考怎样避免指令重排
指令重排
什么是指令重排
为什么会出现指令重排
指令重排分类
指令重排会导致什么问题
指令重排的案例
怎样避免指令重排
指令重排遵循什么规则
什么是指令重排?为什么会出现指令重排?
在执行程序时为了提高性能,编译器和处理器会对指令做重排序。

指令重排分类
**编译器优化的重排序。**编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
**处理器指令级并行的重排序。**现代处理器采用了指令级并行技术(Instruction-LevelParallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
**内存系统的“重排序”。**由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从源码到最终执行的指令序列示意图:

指令重排会导致什么问题
指令重排序不会影响单线程执行结果,但会改变多线程程序的执行结果,导致最后的结果跟预期的不一致。
指令重排案例
public class OutOfOrderExecution {
private static int x = 0,y = 0;
private static int a = 0,b = 0;
private static int c;
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(1);
for (;;){
c++;
a = 0;
b = 0;
x = 0;
y = 0;
Thread one = new Thread(new Runnable() {
@Override
public void run() {
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
a = 1;
x = b;
}
});
Thread two = new Thread(new Runnable() {
@Override
public void run() {
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
b = 1;
y = a;
}
});
one.start();
two.start();
latch.countDown();
one.join();
two.join();
System.out.println("x = " + x + ",y = " + y);
}
}
}程序可能会以下情:
(正常情况)线程1先执行完,线程2再开始执行,那么输出结果为x = 0,y = 1
(正常情况)线程2先执行完,线程1再开始执行,那么输出结果为x = 1,y = 0
(正常情况)线程1执行a = 1后因CPU线程调度掉线程2执行,对b = 1赋值,然后输出结果是x = 1,y = 1
(重排序情况)x= b,y = a重排序到a = 1,b = 1前执行,执行顺序为(y = a,a = 1,x = b,b=1)那么输出结果是x = 0,y = 0
怎样避免指令重排
可以使用 synchronized 和 volatile 来保证多线程之间操作的有序性。
实现方式有所区别:
volatile关键字会禁止指令重排。[volatile 禁止指令重排序语义的实现](#volatile 有序性实现)
synchronized关键字保证同一时刻只允许一条线程操作。
说到有序性,可以通过 volatile 和 synchronized 来实现,但是不可能所有的代码都靠这两个关键字。实际上,Java 语言已对重排序或者说有序性做了规定(指令重排原则),这些规定在虚拟机优化的时候是不能违背的。
指令重排原则
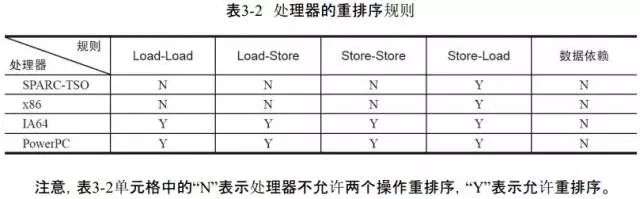
每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这会导致处理器执行内存操作的顺序可能会与内存实际的操作执行顺序不一致。由于现代的处理器都会使用写缓冲区,因此现代的处理器都会允许对写-读操作进行重排序:
数据依赖:
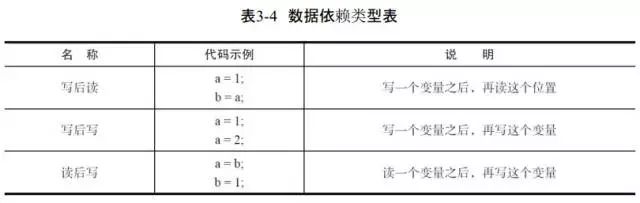
编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。(这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑)
数据依赖个人理解:定义完一个变量,接着立马就用。
as-if-serial
不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器和处理器不会对存在数据依赖关系的操作做重排序,因为会改变执行结果。(编译器、runtime和处理器都必须遵守as-if-serial语义)
即便指令重排不会乱来,但还是会在一些特殊场景(多线程环境)导致代码执行出现不可预知的问题。
happens-before
闲言碎语:【理工科重点倾向实践成果,理论概念用自己的理解描述】
除了教材作者和授课讲师,几乎没有人愿意整理记忆一大堆的理论概念,他们是靠这个为生的!而你作为开发人员,重点是利用技术现实业务价值,如果你也卡在海量细枝末节的理论概念里面,时间和精力没用对地方,各项技能平庸不拔尖,求职跳槽怎么竞争得过那些名校、名企光环的人啊!!
**sychronized 和 volatile 关键字来保证原子性、可见性和有序性。**从jdk5开始提供happens-before原则来辅助程序执行的原子性、可见性和有序性。
程序顺序原则:在一个线程内一段代码的执行结果是有序的。虽然还会指令重排,但是随便它怎么排,结果是按照代码的顺序生成的不会变。
锁规则:无论是在单线程环境还是多线程环境,对于同一个锁来说,一个线程对这个锁解锁之后,另一个线程获取了这个锁都能看到前一个线程的操作结果。
volatile变量规则:如果一个线程先去写一个volatile变量,然后一个线程去读这个变量,那么这个写操作的结果一定对读的这个线程可见。
线程启动规则:在主线程A执行过程中,启动子线程B,那么线程A在启动子线程B之前对共享变量的修改结果对线程B可见。
线程结束规则:在主线程A执行过程中,子线程B终止,那么线程B在终止之前对共享变量的修改结果在线程A中可见。
中断规则:线程interrupt()方法的调用比检测线程中断的事件发生的早,可以通过Thread.interrupted()检测到是否发生中断。
终结器规则:一个对象的初始化的完成,也就是构造函数执行的结束一定早于happens-before它的finalize()方法。
传递性:A happens-before B,B happens-before C,那么A happens-before C。
JMM 内存屏障(了解)
https://zhuanlan.zhihu.com/p/29881777
**重排序可能会导致多线程程序出现内存可见性问题。**对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障(Memory Barriers,Intel称之为Memory Fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序。通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
为了保证内存可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。
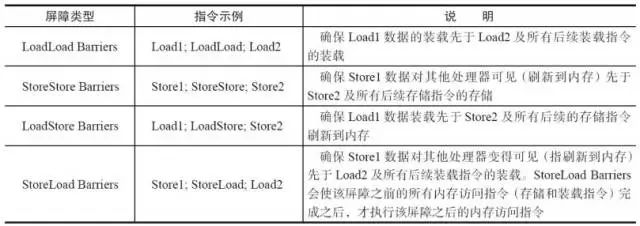
StoreLoad Barriers 是一个“全能型”的屏障,它同时具有其他3个屏障的效果。现代的多处理器大多支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(Buffer Fully Flush)。
不同cpu对于jvm内存屏障的实现指令不一样,拿Intel cpu来看实现的指令:
- ifence:是一种load barrier读屏障,实现LoadLoad屏障。
- sfence:是一种store barrier写屏障,实现StoreStore屏障。
- mfence:是一种全能屏障,具备Ifence和sfence的能力,实现所有屏障的能力。
三、★线程安全同步处理
互斥同步
Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是 JVM 实现的 synchronized,而另一个是 JDK 实现的 ReentrantLock。
synchronized
同一进程的多个线程共享同一块存储空间,在带来方便的同时,也产生了访问冲突的问题,为了保证数据在方法中被访问时的正确性,在访问时加入锁机制synchronized,当一个线程获取对象的排他锁,独占资源,其他线程必须等待,使用完毕后释放锁即可。
synchronized 存在的问题:
一个线程持有锁,会导致其他所有需要此锁的线程挂起。
在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题。
如果优先级高的线程等待一个线程优先级低的线程释放锁,会导致优先级倒置,引起性能问题。
同步方法
// 同步一个普通方法,和同步代码块一样,作用于同一个对象。
private synchronized void method(String[] args){}
// 同步一个静态方法,作用于整个类。
public synchronized static void fun() {
// ...
}
// 同步监视器为一个类,作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
public void func() {
synchronized (SynchronizedExample.class) {
// ...
}
}synchronized 方法控制对“对象”的访问每个对象拥有一把锁,每个synchronized方法都必须获得调用该方法的对象的锁才能执行,否则线程会阻塞。方法一旦被执行,就独占该锁,直到方法返回才释放锁,后面阻塞的线程才能获得这个锁,继续执行。
synchronized 同步方法时,对象锁在方法所在类的对象上,这个对象称为同步监视器。同步方法时的同步监视器是方法所在类的对象本身,即this,或者是class[反射相关]。
synchronized 同步static静态方法时,锁的是Class对象(万物皆对象),作用于整个类。
同步方法的缺陷:同步大方法影响性能
如果synchronized同步的是一个处理业务量比较大的方法,将会对方法的执行效率产生影响,因为其中可能有很多代码根本不用同步。
/**
* synchronized 同步方法,锁是方法所在类的对象,这里是this
*/
private synchronized void buy() {
if (ticketsSum <= 0) {
stopFlag = true;
return;
}
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 抢到了第 " + ticketsSum-- + " 张票。");
}同步代码块
// 只作用于同一个对象,如果是两个不同的对象进入同步代码块,就不会进行同步。
//synchronized(obj){}
public void func() {
synchronized (this) {
// ...
}
}obj 称为同步监视器。
obj 可以是任何对象,但推荐使用共享且变化的对象(增删改)作为同步监视器。
代码块包括静态代码块和非静态代码块,锁的都是 obj 对象。
public class UnsafeList {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
/**
* 锁的对象是变化的量,即增删改的对象
*/
synchronized(list) {
list.add(Thread.currentThread().getName());
}
}).start();
}
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(list.size());
}
}ReentrantLock
ReentrantLock 是 java.util.concurrent(J.U.C)包中的锁。
public class LockExample {
private Lock lock = new ReentrantLock();
public void func() {
lock.lock();
try {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
} finally {
lock.unlock(); // 确保释放锁,从而避免发生死锁。
}
}
}
public static void main(String[] args) {
LockExample lockExample = new LockExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> lockExample.func());
executorService.execute(() -> lockExample.func());
}
输出结果
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9ReentrantLock 与 Synchronized 比较
1. 锁的实现
synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
2. 性能
新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
3. 等待可中断
当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
ReentrantLock 可中断,而 synchronized 不行。
4. 公平锁
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
5. 锁绑定多个条件
一个 ReentrantLock 可以同时绑定多个 Condition 对象。
使用选择
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。这是因为 synchronized 是 JVM 实现的一种锁机制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持。并且使用 synchronized 不用担心没有释放锁而导致死锁问题,因为 JVM 会确保锁的释放。
非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
CAS(Compare-and-Swap)
随着硬件指令集的发展,可以使用基于冲突检测的乐观并发策略:先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
乐观锁需要操作和冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是:比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个操作数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
[CAS ABA 问题](#CAS(compare and swap)比较并交换)
AtomicInteger
JUC 包里面的整数原子类 AtomicInteger,其中的 compareAndSet() 和 getAndIncrement() 等方法都使用了 Unsafe 类的 CAS 操作。
以下代码使用了 AtomicInteger 执行了自增的操作。
private AtomicInteger cnt = new AtomicInteger();
public void add() {
cnt.incrementAndGet();
}以下代码是 incrementAndGet() 的源码,它调用了 unsafe 的 getAndAddInt() 。
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}以下代码是 getAndAddInt() 源码,var1 指示对象内存地址,var2 指示该字段相对对象内存地址的偏移,var4 指示操作需要加的数值,这里为 1。通过 getIntVolatile(var1, var2) 得到旧的预期值,通过调用 compareAndSwapInt() 来进行 CAS 比较,如果该字段内存地址中的值等于 var5,那么就更新内存地址为 var1+var2 的变量为 var5+var4。
可以看到 getAndAddInt() 在一个循环中进行,发生冲突的做法是不断的进行重试。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
栈封闭
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StackClosedExample {
public void add100() {
int cnt = 0;
for (int i = 0; i < 100; i++) {
cnt++;
}
System.out.println(cnt);
}
}
public static void main(String[] args) {
StackClosedExample example = new StackClosedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> example.add100());
executorService.execute(() -> example.add100());
executorService.shutdown();
}
输出结果
100
100线程本地存储(Thread Local Storage)
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
符合这种特点的应用并不少见,大部分使用消费队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完。其中最重要的一个应用实例就是经典 Web 交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式,这种处理方式的广泛应用使得很多 Web 服务端应用都可以使用线程本地存储来解决线程安全问题。
可以使用 java.lang.ThreadLocal 类来实现线程本地存储功能。
对于以下代码,thread1 中设置 threadLocal 为 1,而 thread2 设置 threadLocal 为 2。过了一段时间之后,thread1 读取 threadLocal 依然是 1,不受 thread2 的影响。
public class ThreadLocalExample {
public static void main(String[] args) {
ThreadLocal threadLocal = new ThreadLocal();
Thread thread1 = new Thread(() -> {
threadLocal.set(1);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadLocal.get());
threadLocal.remove();
});
Thread thread2 = new Thread(() -> {
threadLocal.set(2);
threadLocal.remove();
});
thread1.start();
thread2.start();
}
}为了理解 ThreadLocal,先看以下代码:
public class ThreadLocalExample1 {
public static void main(String[] args) {
ThreadLocal threadLocal1 = new ThreadLocal();
ThreadLocal threadLocal2 = new ThreadLocal();
Thread thread1 = new Thread(() -> {
threadLocal1.set(1);
threadLocal2.set(1);
});
Thread thread2 = new Thread(() -> {
threadLocal1.set(2);
threadLocal2.set(2);
});
thread1.start();
thread2.start();
}
}它所对应的底层结构图为:

每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象,Thread 类中就定义了 ThreadLocal.ThreadLocalMap 成员。
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;当调用一个 ThreadLocal 的 set(T value) 方法时,先得到当前线程的 ThreadLocalMap 对象,然后将 ThreadLocal->value 键值对插入到该 Map 中。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}get() 方法类似。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}ThreadLocal 从理论上讲并不是用来解决多线程并发问题的,因为根本不存在多线程竞争。
在一些场景 (尤其是使用线程池) 下,由于 ThreadLocal.ThreadLocalMap 的底层数据结构导致 ThreadLocal 有内存泄漏的情况,应该尽可能在每次使用 ThreadLocal 后手动调用 remove(),以避免出现 ThreadLocal 经典的内存泄漏甚至是造成自身业务混乱的风险。
可重入代码(Reentrant Code)
这种代码也叫做纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。
可重入代码有一些共同的特征,例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都由参数中传入、不调用非可重入的方法等。
synchronized 详解
- synchronized详解 [📄](./Java 多线程与并发/synchronized 详解.md)
synchronized 内置锁实现原理
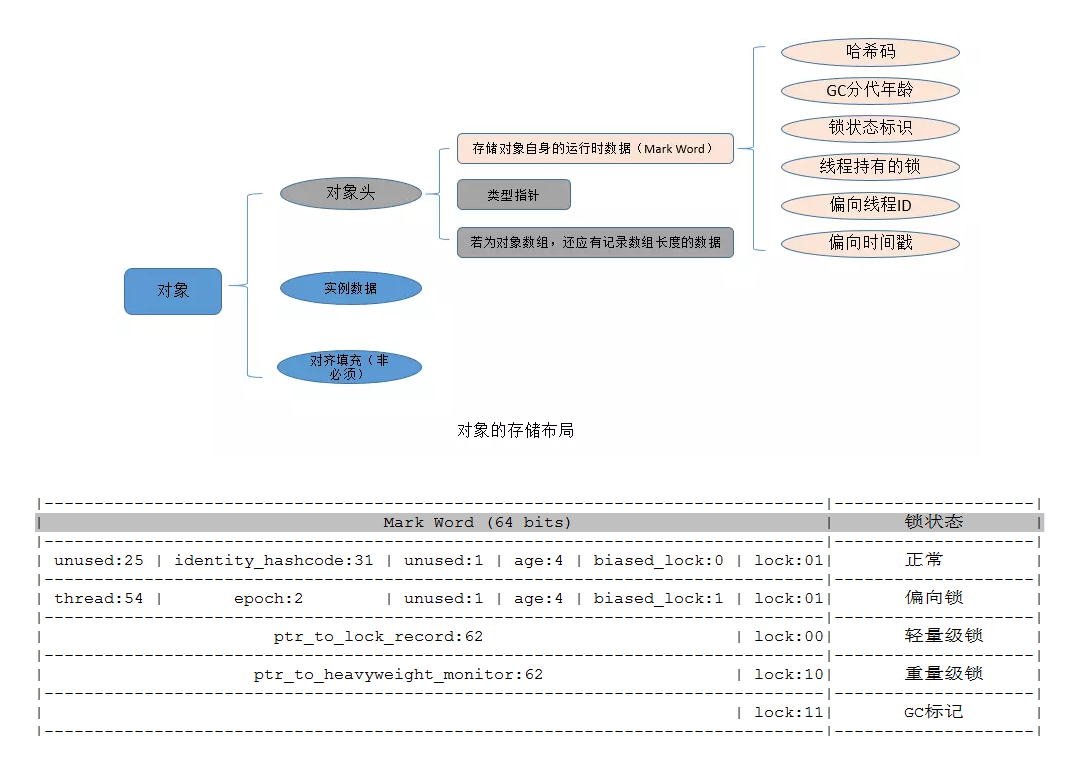
synchronized 可重入实现原理
synchronized用的锁是存在Java对象头里的。
JVM基于进入和退出Monitor对象来实现方法同步和代码块同步。代码块同步是使用monitorenter和monitorexit指令实现的,monitorenter指令是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处。任何对象都有一个monitor与之关联,当且一个monitor被持有后,它将处于锁定状态。
根据虚拟机规范的要求,在执行monitorenter指令时,首先要去尝试获取对象的锁,如果这个对象没被锁定,或者当前线程已经拥有了那个对象的锁,把锁的计数器加1(线程重入锁的计数器也要加1);相应地,在执行monitorexit指令时会将锁计数器减1,当计数器被减到0时,锁就释放了。如果获取对象锁失败了,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
synchronized 锁膨胀升级过程
volatile 详解
https://www.pdai.tech/md/java/thread/java-thread-x-key-volatile.html
volatile 的作用
防重排序
从一个最经典的例子来分析重排序问题。大家应该都很熟悉单例模式的实现,而在并发环境下的单例实现方式,通常可以采用双重检查加锁(DCL)的方式来实现。其源码如下:
public class Singleton {
public static volatile Singleton singleton;
/**
* 构造函数私有,禁止外部实例化
*/
private Singleton() {};
public static Singleton getInstance() {
if (singleton == null) {
synchronized (singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}现在分析一下为什么要在变量singleton之间加上volatile关键字。要理解这个问题,先要了解对象的构造过程,实例化一个对象其实可以分为三个步骤:
- 分配内存空间。
- 初始化对象。
- 将内存空间的地址赋值给对应的引用。
但是由于操作系统可以对指令进行重排序,所以上面的过程也可能会变成如下过程:
- 分配内存空间。
- 将内存空间的地址赋值给对应的引用。
- 初始化对象
如果是这个流程,多线程环境下就可能将一个未初始化的对象引用暴露出来,从而导致不可预料的结果。因此,为了防止这个过程的重排序,需要将变量设置为volatile类型的变量。
实现可见性
可见性问题主要指一个线程修改了共享变量值,而另一个线程却看不到。引起可见性问题的主要原因是每个线程拥有自己的一个高速缓存区——线程工作内存。volatile关键字能有效的解决这个问题,看下下面的例子,就可以知道其作用:
public class VolatileTest {
int a = 1;
int b = 2;
public void change(){
a = 3;
b = a;
}
public void print(){
System.out.println("b="+b+";a="+a);
}
public static void main(String[] args) {
while (true){
final VolatileTest test = new VolatileTest();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
test.change();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
test.print();
}
}).start();
}
}
}直观上说,这段代码的结果只可能有两种:b=3;a=3 或 b=2;a=1。不过运行上面的代码(可能时间上要长一点),你会发现除了上两种结果之外,还出现了第三种结果:
......
b=2;a=1
b=2;a=1
b=3;a=3
b=3;a=3
b=3;a=1 // 这里
b=3;a=3
b=2;a=1
b=3;a=3
b=3;a=3
......为什么会出现b=3;a=1这种结果呢? 正常情况下,如果先执行change方法,再执行print方法,输出结果应该为b=3;a=3。相反,如果先执行的print方法,再执行change方法,结果应该是 b=2;a=1。那b=3;a=1的结果是怎么出来的? 原因就是第一个线程将值a=3修改后,但是对第二个线程是不可见的,所以才出现这一结果。如果将a和b都改成volatile类型的变量再执行,则再也不会出现b=3;a=1的结果了。
保证原子性:单次读/写
volatile不能保证完全的原子性,只能保证单次的读/写操作具有原子性。先从如下两个问题来理解(后文再从内存屏障的角度理解)
问题1: i++为什么不能保证原子性?
对于原子性,需要强调一点,也是大家容易误解的一点:对volatile变量的单次读/写操作可以保证原子性的,如long和double类型变量,但是并不能保证i++这种操作的原子性,因为本质上i++是读、写两次操作。
现在就通过下列程序来演示一下这个问题:
public class VolatileTest01 {
volatile int i;
public void addI(){
i++;
}
public static void main(String[] args) throws InterruptedException {
final VolatileTest01 test01 = new VolatileTest01();
for (int n = 0; n < 1000; n++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
test01.addI();
}
}).start();
}
Thread.sleep(10000);//等待10秒,保证上面程序执行完成
System.out.println(test01.i);
}
}大家可能会误认为对变量i加上关键字volatile后,这段程序就是线程安全的。大家可以尝试运行上面的程序。下面是我本地运行的结果:981 可能每个人运行的结果不相同。不过应该能看出,volatile是无法保证原子性的(否则结果应该是1000)。原因也很简单,i++其实是一个复合操作,包括三步骤:
- 读取i的值。
- 对i加1。
- 将i的值写回内存。 volatile是无法保证这三个操作是具有原子性的,可以通过AtomicInteger或者Synchronized来保证+1操作的原子性。 注:上面几段代码中多处执行了Thread.sleep()方法,目的是为了增加并发问题的产生几率,无其他作用。
问题2: 共享的long和double变量的为什么要用volatile?
因为long和double两种数据类型的操作可分为高32位和低32位两部分,因此普通的long或double类型读/写可能不是原子的。因此,鼓励大家将共享的long和double变量设置为volatile类型,这样能保证任何情况下对long和double的单次读/写操作都具有原子性。
如下是JLS中的解释:
17.7 Non-Atomic Treatment of double and long
- For the purposes of the Java programming language memory model, a single write to a non-volatile long or double value is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.
- Writes and reads of volatile long and double values are always atomic.
- Writes to and reads of references are always atomic, regardless of whether they are implemented as 32-bit or 64-bit values.
- Some implementations may find it convenient to divide a single write action on a 64-bit long or double value into two write actions on adjacent 32-bit values. For efficiency’s sake, this behavior is implementation-specific; an implementation of the Java Virtual Machine is free to perform writes to long and double values atomically or in two parts.
- Implementations of the Java Virtual Machine are encouraged to avoid splitting 64-bit values where possible. Programmers are encouraged to declare shared 64-bit values as volatile or synchronize their programs correctly to avoid possible complications.
目前各种平台下的商用虚拟机都选择把 64 位数据的读写操作作为原子操作来对待,因此在编写代码时一般不把long 和 double 变量专门声明为 volatile多数情况下也是不会错的。
volatile 的实现原理
volatile 可见性实现
volatile 变量的内存可见性是基于内存屏障(Memory Barrier)实现:
- 内存屏障,又称内存栅栏,是一个 CPU 指令。
- 在程序运行时,为了提高执行性能,编译器和处理器会对指令进行重排序,JMM 为了保证在不同的编译器和 CPU 上有相同的结果,通过插入特定类型的内存屏障来禁止+ 特定类型的编译器重排序和处理器重排序,插入一条内存屏障会告诉编译器和 CPU:不管什么指令都不能和这条 Memory Barrier 指令重排序。
写一段简单的 Java 代码,声明一个 volatile 变量,并赋值。
public class Test {
private volatile int a;
public void update() {
a = 1;
}
public static void main(String[] args) {
Test test = new Test();
test.update();
}
}通过 hsdis 和 jitwatch 工具可以得到编译后的汇编代码:
......
0x0000000002951563: and $0xffffffffffffff87,%rdi
0x0000000002951567: je 0x00000000029515f8
0x000000000295156d: test $0x7,%rdi
0x0000000002951574: jne 0x00000000029515bd
0x0000000002951576: test $0x300,%rdi
0x000000000295157d: jne 0x000000000295159c
0x000000000295157f: and $0x37f,%rax
0x0000000002951586: mov %rax,%rdi
0x0000000002951589: or %r15,%rdi
0x000000000295158c: lock cmpxchg %rdi,(%rdx) //在 volatile 修饰的共享变量进行写操作的时候会多出 lock 前缀的指令
0x0000000002951591: jne 0x0000000002951a15
0x0000000002951597: jmpq 0x00000000029515f8
0x000000000295159c: mov 0x8(%rdx),%edi
0x000000000295159f: shl $0x3,%rdi
0x00000000029515a3: mov 0xa8(%rdi),%rdi
0x00000000029515aa: or %r15,%rdi
......lock 前缀的指令在多核处理器下会引发两件事情:
- 将当前处理器缓存行的数据写回到系统内存。
- 写回内存的操作会使在其他 CPU 里缓存了该内存地址的额数据无效。
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2 或其他)后再进行操作,但操作完不知道何时会写到内存。
如果对声明了 volatile 的变量进行写操作,JVM 就会向处理器发送一条 lock 前缀的指令,将这个变量所在缓存行的数据写回到系统内存。
为了保证各个处理器的缓存是一致的,实现了缓存一致性协议(MESI),每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
所有多核处理器下还会完成:当处理器发现本地缓存失效后,就会从内存中重读该变量数据,即可以获取当前最新值。
volatile 变量通过这样的机制就使得每个线程都能获得该变量的最新值。
lock 指令
在 Pentium 和早期的 IA-32 处理器中,lock 前缀会使处理器执行当前指令时产生一个 LOCK## 信号,会对总线进行锁定,其它 CPU 对内存的读写请求都会被阻塞,直到锁释放。 后来的处理器,加锁操作是由高速缓存锁代替总线锁来处理。 因为锁总线的开销比较大,锁总线期间其他 CPU 没法访问内存。 这种场景多缓存的数据一致通过缓存一致性协议(MESI)来保证。
缓存一致性
缓存是分段(line)的,一个段对应一块存储空间,称之为缓存行,它是 CPU 缓存中可分配的最小存储单元,大小 32 字节、64 字节、128 字节不等,这与 CPU 架构有关,通常来说是 64 字节。 LOCK## 因为锁总线效率太低,因此使用了多组缓存。 为了使其行为看起来如同一组缓存那样。因而设计了 缓存一致性协议。 缓存一致性协议有多种,但是日常处理的大多数计算机设备都属于 " 嗅探(snooping)" 协议。 所有内存的传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线。 缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁(同一个指令周期中,只有一个 CPU 缓存可以读写内存)。 CPU 缓存不仅仅在做内存传输的时候才与总线打交道,而是不停在嗅探总线上发生的数据交换,跟踪其他缓存在做什么。 当一个缓存代表它所属的处理器去读写内存时,其它处理器都会得到通知,它们以此来使自己的缓存保持同步。 只要某个处理器写内存,其它处理器马上知道这块内存在它们的缓存段中已经失效。
volatile 有序性实现
volatile 的 happens-before 关系
happens-before 规则中有一条是 volatile 变量规则:对一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。
//假设线程A执行writer方法,线程B执行reader方法
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // 1 线程A修改共享变量
flag = true; // 2 线程A写volatile变量
}
public void reader() {
if (flag) { // 3 线程B读同一个volatile变量
int i = a; // 4 线程B读共享变量
……
}
}
}根据 happens-before 规则,上面过程会建立 3 类 happens-before 关系。
- 根据程序次序规则:1 happens-before 2 且 3 happens-before 4。
- 根据 volatile 规则:2 happens-before 3。
- 根据 happens-before 的传递性规则:1 happens-before 4。
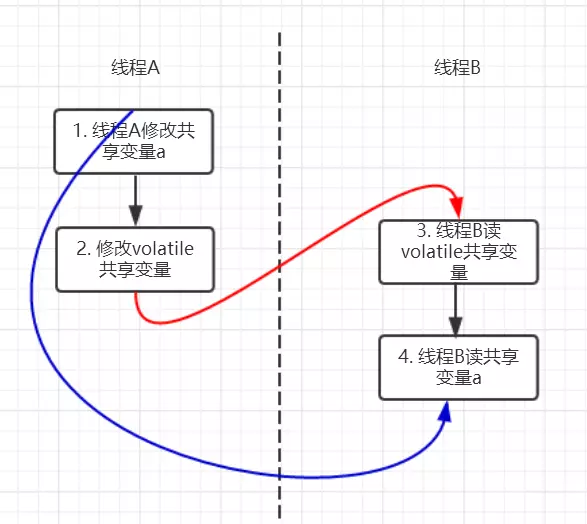
因为以上规则,当线程 A 将 volatile 变量 flag 更改为 true 后,线程 B 能够迅速感知。
volatile 禁止重排序
为了性能优化,JMM 在不改变正确语义的前提下,会允许编译器和处理器对指令序列进行重排序。JMM 提供了内存屏障阻止这种重排序。
https://cloud.tencent.com/developer/article/1462257
通过内存屏障指令来禁止特定类型的处理器重排序。
JMM针对编译器制定volatile重排序规则表:

当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
下面是基于保守策略的JMM内存屏障插入策略:
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的后面插入一个StoreLoad屏障。
在每个volatile读操作的后面插入一个LoadLoad屏障。
在每个volatile读操作的后面插入一个LoadStore屏障。
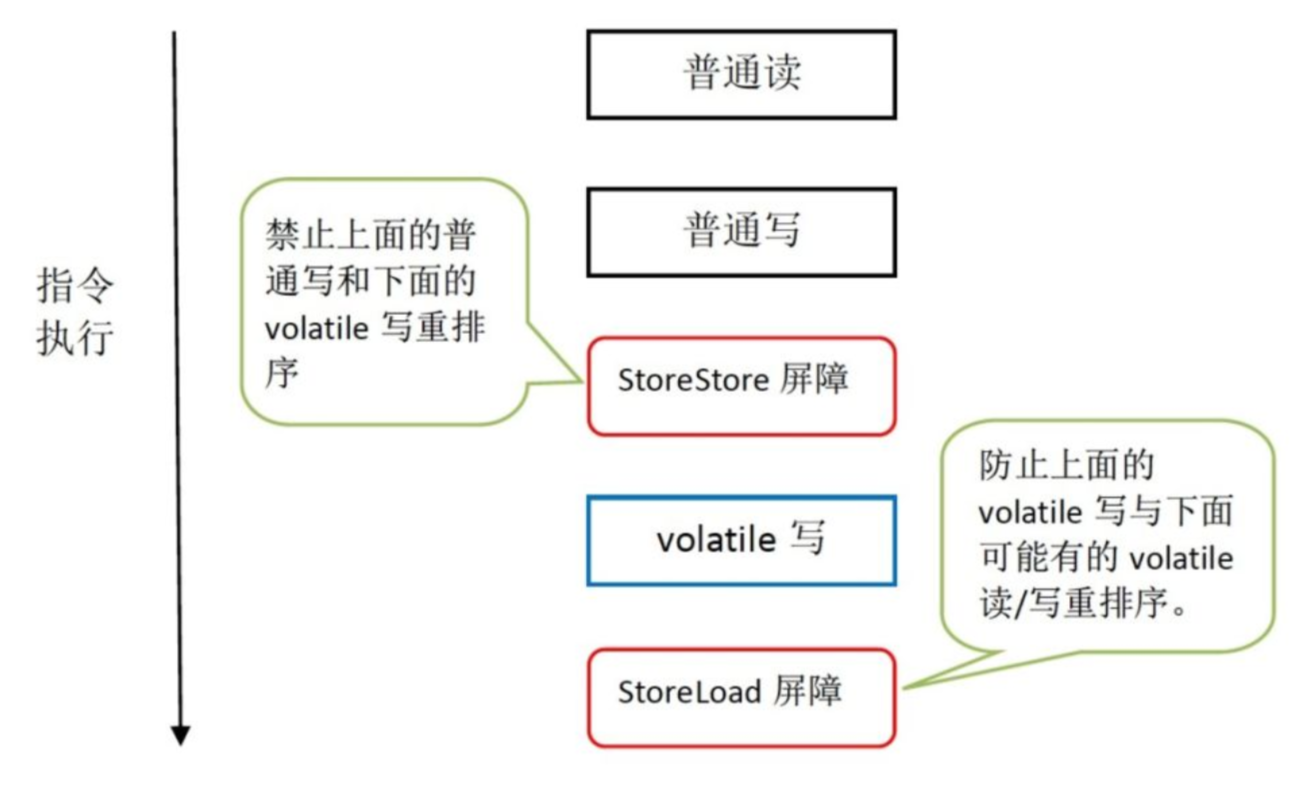
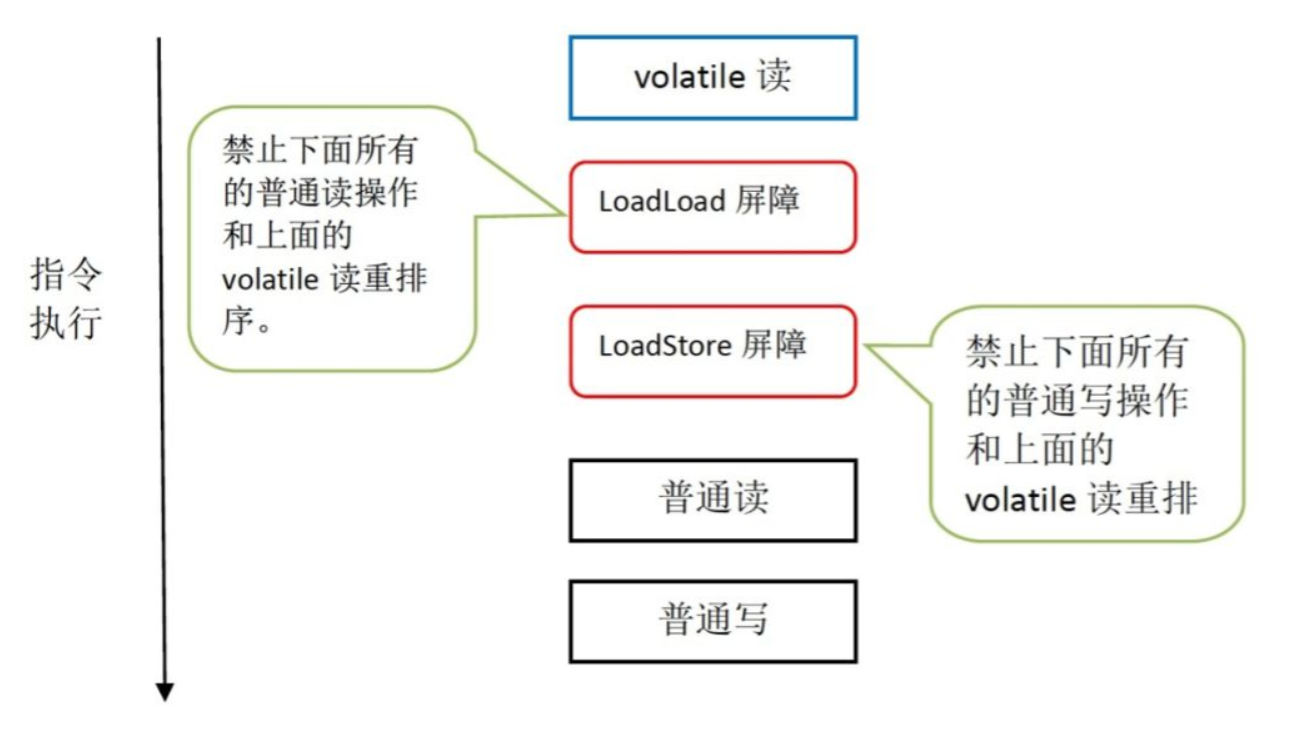
从编译器重排序规则和处理器内存屏障插入策略来看,只要volatile变量与普通变量之间的重排序可能会破坏volatile的内存语义(内存可见性),这种重排序就会被编译器重排序规则和处理器内存屏障插入策略禁止。
volatile 的应用场景
使用 volatile 必须具备的条件
- 对变量的写操作不依赖于当前值。
- 该变量没有包含在具有其他变量的不变式中。
- 只有在状态真正独立于程序内其他内容时才能使用 volatile。
模式1:状态标志
也许实现 volatile 变量的规范使用仅仅是使用一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或请求停机。
volatile boolean shutdownRequested;
......
public void shutdown() { shutdownRequested = true; }
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}模式2:一次性安全发布(one-time safe publication)
缺乏同步会导致无法实现可见性,这使得确定何时写入对象引用而不是原始值变得更加困难。在缺乏同步的情况下,可能会遇到某个对象引用的更新值(由另一个线程写入)和该对象状态的旧值同时存在。(这就是造成著名的双重检查锁定(double-checked-locking)问题的根源,其中对象引用在没有同步的情况下进行读操作,产生的问题是您可能会看到一个更新的引用,但是仍然会通过该引用看到不完全构造的对象)。
public class BackgroundFloobleLoader {
public volatile Flooble theFlooble;
public void initInBackground() {
// do lots of stuff
theFlooble = new Flooble(); // this is the only write to theFlooble
}
}
public class SomeOtherClass {
public void doWork() {
while (true) {
// do some stuff...
// use the Flooble, but only if it is ready
if (floobleLoader.theFlooble != null)
doSomething(floobleLoader.theFlooble);
}
}
}模式3:独立观察(independent observation)
安全使用 volatile 的另一种简单模式是定期 发布 观察结果供程序内部使用。例如,假设有一种环境传感器能够感觉环境温度。一个后台线程可能会每隔几秒读取一次该传感器,并更新包含当前文档的 volatile 变量。然后,其他线程可以读取这个变量,从而随时能够看到最新的温度值。
public class UserManager {
public volatile String lastUser;
public boolean authenticate(String user, String password) {
boolean valid = passwordIsValid(user, password);
if (valid) {
User u = new User();
activeUsers.add(u);
lastUser = user;
}
return valid;
}
}模式4:volatile bean 模式
在 volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}模式5:开销较低的读-写锁策略
volatile 的功能还不足以实现计数器。因为 ++x 实际上是三种操作(读、添加、存储)的简单组合,如果多个线程凑巧试图同时对 volatile 计数器执行增量操作,那么它的更新值有可能会丢失。 如果读操作远远超过写操作,可以结合使用内部锁和 volatile 变量来减少公共代码路径的开销。 安全的计数器使用 synchronized 确保增量操作是原子的,并使用 volatile 保证当前结果的可见性。如果更新不频繁的话,该方法可实现更好的性能,因为读路径的开销仅仅涉及 volatile 读操作,这通常要优于一个无竞争的锁获取的开销。
@ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatile int value;
public int getValue() { return value; }
public synchronized int increment() {
return value++;
}
}模式6:双重检查(double-checked)
就是上文举的例子。
单例模式的一种实现方式,但很多人会忽略 volatile 关键字,因为没有该关键字,程序也可以很好的运行,只不过代码的稳定性总不是 100%,说不定在未来的某个时刻,隐藏的 bug 就出来了。
class Singleton {
private volatile static Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
syschronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}final 详解
https://www.pdai.tech/md/java/thread/java-thread-x-key-final.html
final 基础使用
修饰类
当某个类的整体定义为final时,就表明了你不能打算继承该类,而且也不允许别人这么做。即这个类是不能有子类的。
注意:final类中的所有方法都隐式为final,因为无法覆盖他们,所以在final类中给任何方法添加final关键字是没有任何意义的。
这里顺道说说final类型的类如何拓展? 比如String是final类型,想写个MyString复用所有String中方法,同时增加一个新的toMyString()的方法,应该如何做?
设计模式中最重要的两种关系,一种是继承/实现;另外一种是组合关系。所以当遇到不能用继承的(final修饰的类),应该考虑用组合, 如下代码大概写个组合实现的意思:
/**
* 扩展 String 类
*/
class MyString{
private String innerString;
// ...init & other methods
// 支持老的方法
public int length(){
return innerString.length(); // 通过innerString调用老的方法
}
// 添加新方法
public String toMyString(){
//...
}
}修饰方法
常规的使用就不说了,这里说下:
- private 方法是隐式的 final
- final 方法是可以被重载的
private final
类中所有private方法都隐式地指定为final的,由于无法取用private方法,所以也就不能覆盖它。可以对private方法增添final关键字,但这样做并没有什么好处。看下下面的例子:
public class Base {
private void test() {
}
}
public class Son extends Base {
public void test() {
}
public static void main(String[] args) {
Son son = new Son();
Base father = son;
//father.test();
}
}Base和Son都有方法test(),但是这并不是一种覆盖,因为private所修饰的方法是隐式的final,也就是无法被继承,所以更不用说是覆盖了,在Son中的test()方法不过是属于Son的新成员罢了,Son进行向上转型得到father,但是father.test()是不可执行的,因为Base中的test方法是private的,无法被访问到。
final 方法是可以被重载的
知道父类的final方法是不能够被子类重写的,那么final方法可以被重载吗? 答案是可以的,下面代码是正确的。
public class FinalExampleParent {
public final void test() {
}
public final void test(String str) {
}
}修饰参数
Java允许在参数列表中以声明的方式将参数指明为final,这意味这你无法在方法中更改参数引用所指向的对象。这个特性主要用来向匿名内部类传递数据。
修饰变量
常规的用法比较简单,这里通过下面三个问题进一步说明。
**所有的 final 修饰的字段都是编译期常量吗?**不是,需要动态取值的变量在初始化的时候才会赋值
现在来看编译期常量和非编译期常量, 如:
public class Test {
//编译期常量
final int i = 1;
final static int J = 1;
final int[] a = {1,2,3,4};
//非编译期常量
Random r = new Random();
final int k = r.nextInt();
public static void main(String[] args) {
}
}k的值由随机数对象决定,所以不是所有的final修饰的字段都是编译期常量,只是k的值在被初始化后无法被更改。
static final
一个既是static又是final 的字段只占据一段不能改变的存储空间,它必须在定义的时候进行赋值,否则编译器将不予通过。
import java.util.Random;
public class Test {
static Random r = new Random();
final int k = r.nextInt(10);
static final int k2 = r.nextInt(10);
public static void main(String[] args) {
Test t1 = new Test();
System.out.println("k="+t1.k+" k2="+t1.k2);
Test t2 = new Test();
System.out.println("k="+t2.k+" k2="+t2.k2);
}
}上面代码某次输出结果:
k=2 k2=7
k=8 k2=7可以发现对于不同的对象k的值是不同的,但是k2的值却是相同的,这是为什么呢? 因为static关键字所修饰的字段并不属于一个对象,而是属于这个类的。也可简单的理解为static final所修饰的字段仅占据内存的一个一份空间,一旦被初始化之后便不会被更改。
blank final
Java允许生成空白final,也就是说被声明为final但又没有给出定值的字段,但是必须在该字段被使用之前被赋值,这给予两种选择:
- 在定义处进行赋值(这不叫空白final)
- 在构造器中进行赋值,保证了该值在被使用前赋值。
这增强了final的灵活性。
看下面代码:
public class Test {
final int i1 = 1;
final int i2;//空白final
public Test() {
i2 = 1;
}
public Test(int x) {
this.i2 = x;
}
}可以看到i2的赋值更为灵活。但是请注意,如果字段由static和final修饰,仅能在定义处赋值,因为该字段不属于对象,属于这个类。
final 域重排序规则
上面聊的final使用,应该属于Java基础层面的,当理解这些后就真的算是掌握了final吗? 有考虑过final在多线程并发的情况吗? 在java内存模型中知道java内存模型为了能让处理器和编译器底层发挥他们的最大优势,对底层的约束就很少,也就是说针对底层来说java内存模型就是一弱内存数据模型。同时,处理器和编译为了性能优化会对指令序列有编译器和处理器重排序。那么,在多线程情况下,final会进行怎样的重排序? 会导致线程安全的问题吗? 下面,就来看看final的重排序。
final 域为基本类型
先看一段示例性的代码:
public class FinalDemo {
private int a; //普通域
private final int b; //final域
private static FinalDemo finalDemo;
public FinalDemo() {
a = 1; // 1. 写普通域
b = 2; // 2. 写final域
}
public static void writer() {
finalDemo = new FinalDemo();
}
public static void reader() {
FinalDemo demo = finalDemo; // 3.读对象引用
int a = demo.a; //4.读普通域
int b = demo.b; //5.读final域
}
}假设线程A在执行writer()方法,线程B执行reader()方法。
写 final 域重排序规则
写final域的重排序规则禁止对final域的写重排序到构造函数之外,这个规则的实现主要包含了两个方面:
- JMM禁止编译器把final域的写重排序到构造函数之外;
- 编译器会在final域写之后,构造函数return之前,插入一个storestore屏障。这个屏障可以禁止处理器把final域的写重排序到构造函数之外。
再来分析writer方法,虽然只有一行代码,但实际上做了两件事情:
- 构造了一个FinalDemo对象;
- 把这个对象赋值给成员变量finalDemo。
来画下存在的一种可能执行时序图,如下:

由于a,b之间没有数据依赖性,普通域(普通变量)a可能会被重排序到构造函数之外,线程B就有可能读到的是普通变量a初始化之前的值(零值),这样就可能出现错误。而final域变量b,根据重排序规则,会禁止final修饰的变量b重排序到构造函数之外,从而b能够正确赋值,线程B就能够读到final变量初始化后的值。
因此,写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域就不具有这个保障。比如在上例,线程B有可能就是一个未正确初始化的对象finalDemo。
读 final 域重排序规则
读final域重排序规则为:在一个线程中,初次读对象引用和初次读该对象包含的final域,JMM会禁止这两个操作的重排序。(注意,这个规则仅仅是针对处理器),处理器会在读final域操作的前面插入一个LoadLoad屏障。实际上,读对象的引用和读该对象的final域存在间接依赖性,一般处理器不会重排序这两个操作。但是有一些处理器会重排序,因此,这条禁止重排序规则就是针对这些处理器而设定的。
read()方法主要包含了三个操作:
- 初次读引用变量finalDemo;
- 初次读引用变量finalDemo的普通域a;
- 初次读引用变量finalDemo的final与b;
假设线程A写过程没有重排序,那么线程A和线程B有一种的可能执行时序为下图:

读对象的普通域被重排序到了读对象引用的前面就会出现线程B还未读到对象引用就在读取该对象的普通域变量,这显然是错误的操作。而final域的读操作就“限定”了在读final域变量前已经读到了该对象的引用,从而就可以避免这种情况。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读这个包含这个final域的对象的引用。
final 域为引用类型
已经知道了final域是基本数据类型的时候重排序规则是怎么的了? 如果是引用数据类型了? 接着继续来探讨。
对 final 修饰的对象的成员域写操作
针对引用数据类型,final域写针对编译器和处理器重排序增加了这样的约束:在构造函数内对一个final修饰的对象的成员域的写入,与随后在构造函数之外把这个被构造的对象的引用赋给一个引用变量,这两个操作是不能被重排序的。注意这里的是“增加”也就说前面对final基本数据类型的重排序规则在这里还是使用。这句话是比较拗口的,下面结合实例来看。
public class FinalReferenceDemo {
final int[] arrays;
private FinalReferenceDemo finalReferenceDemo;
public FinalReferenceDemo() {
arrays = new int[1]; //1
arrays[0] = 1; //2
}
public void writerOne() {
finalReferenceDemo = new FinalReferenceDemo(); //3
}
public void writerTwo() {
arrays[0] = 2; //4
}
public void reader() {
if (finalReferenceDemo != null) { //5
int temp = finalReferenceDemo.arrays[0]; //6
}
}
}针对上面的实例程序,线程线程A执行wirterOne方法,执行完后线程B执行writerTwo方法,然后线程C执行reader方法。下图就以这种执行时序出现的一种情况来讨论(耐心看完才有收获)。
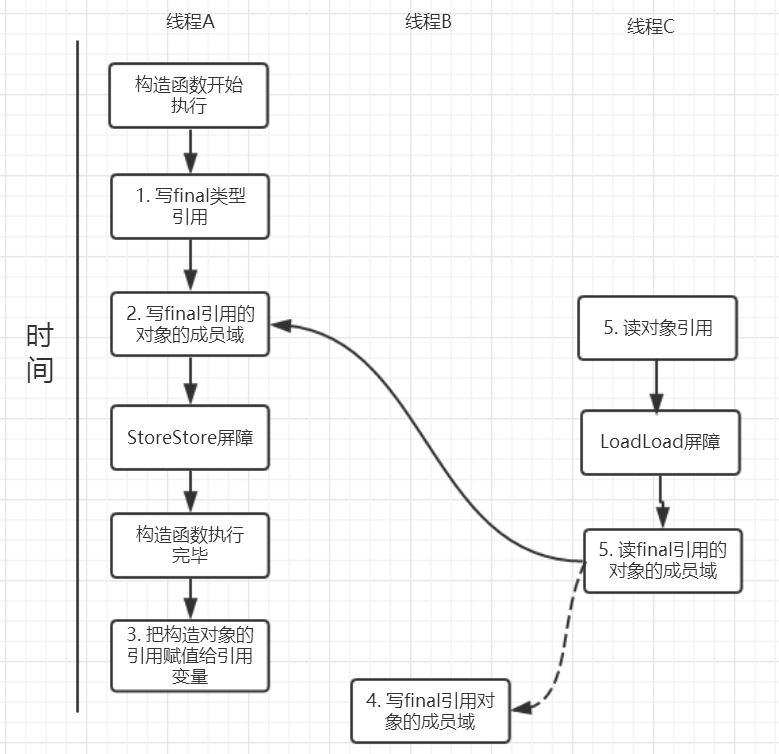
由于对final域的写禁止重排序到构造方法外,因此1和3不能被重排序。由于一个final域的引用对象的成员域写入不能与随后将这个被构造出来的对象赋给引用变量重排序,因此2和3不能重排序。
对 final 修饰的对象的成员域读操作
JMM可以确保线程C至少能看到写线程A对final引用的对象的成员域的写入,即能看下arrays[0] = 1,而写线程B对数组元素的写入可能看到可能看不到。JMM不保证线程B的写入对线程C可见,线程B和线程C之间存在数据竞争,此时的结果是不可预知的。如果可见的,可使用锁或者volatile。
关于final重排序的总结
按照final修饰的数据类型分类:
- 基本数据类型:
final域写:禁止final域写与构造方法重排序,即禁止final域写重排序到构造方法之外,从而保证该对象对所有线程可见时,该对象的final域全部已经初始化过。final域读:禁止初次读对象的引用与读该对象包含的final域的重排序。
- 引用数据类型:
额外增加约束:禁止在构造函数对一个final修饰的对象的成员域的写入与随后将这个被构造的对象的引用赋值给引用变量 重排序
final 再深入理解
final 的实现原理
上面提到过,写final域会要求编译器在final域写之后,构造函数返回前插入一个StoreStore屏障。读final域的重排序规则会要求编译器在读final域的操作前插入一个LoadLoad屏障。
很有意思的是,如果以X86处理为例,X86不会对写-写重排序,所以StoreStore屏障可以省略。由于不会对有间接依赖性的操作重排序,所以在X86处理器中,读final域需要的LoadLoad屏障也会被省略掉。也就是说,以X86为例的话,对final域的读/写的内存屏障都会被省略!具体是否插入还是得看是什么处理器。
为什么 final 引用不能从构造函数中“溢出”
这里还有一个比较有意思的问题:上面对final域写重排序规则可以确保在使用一个对象引用的时候该对象的final域已经在构造函数被初始化过了。但是这里其实是有一个前提条件的,也就是:在构造函数,不能让这个被构造的对象被其他线程可见,也就是说该对象引用不能在构造函数中“溢出”。以下面的例子来说:
public class FinalReferenceEscapeDemo {
private final int a;
private FinalReferenceEscapeDemo referenceDemo;
public FinalReferenceEscapeDemo() {
a = 1; //1
referenceDemo = this; //2
}
public void writer() {
new FinalReferenceEscapeDemo();
}
public void reader() {
if (referenceDemo != null) { //3
int temp = referenceDemo.a; //4
}
}
}可能的执行时序如图所示:
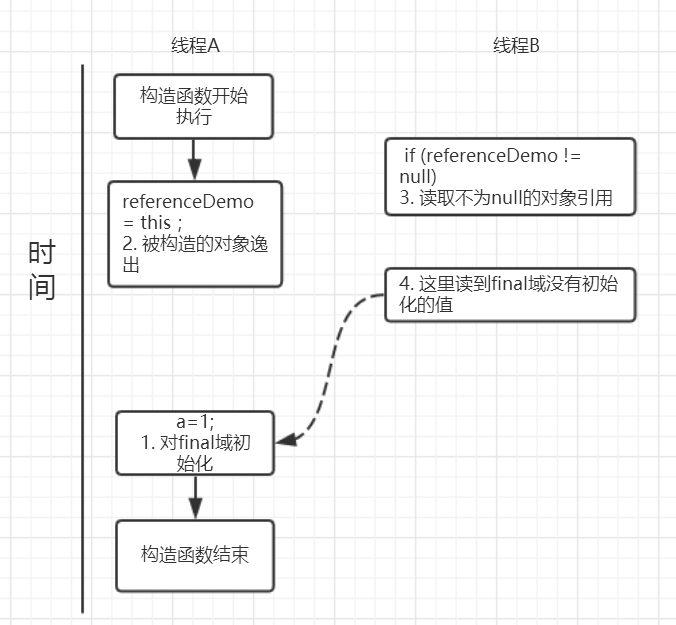
假设一个线程A执行writer方法另一个线程执行reader方法。因为构造函数中操作1和2之间没有数据依赖性,1和2可以重排序,先执行了2,这个时候引用对象referenceDemo是个没有完全初始化的对象,而当线程B去读取该对象时就会出错。尽管依然满足了final域写重排序规则:在引用对象对所有线程可见时,其final域已经完全初始化成功。但是,引用对象“this”逸出,该代码依然存在线程安全的问题。
使用 final 的限制条件和局限性
当声明一个 final 成员时,必须在构造函数退出前设置它的值。
public class MyClass {
private final int myField = 1;
public MyClass() {
...
}
}或者
public class MyClass {
private final int myField;
public MyClass() {
...
myField = 1;
...
}
}将指向对象的成员声明为 final 只能将该引用设为不可变的,而非所指的对象。
下面的方法仍然可以修改该 list。
private final List myList = new ArrayList();
myList.add("Hello");声明为 final 可以保证如下操作不合法
myList = new ArrayList();
myList = someOtherList;如果一个对象将会在多个线程中访问并且你并没有将其成员声明为 final,则必须提供其他方式保证线程安全。
" 其他方式 " 可以包括声明成员为 volatile,使用 synchronized 或者显式 Lock 控制所有该成员的访问。
再思考一个有趣的现象:
byte b1=1;
byte b2=3;
byte b3=b1+b2;//当程序执行到这一行的时候会出错,因为b1、b2可以自动转换成int类型的变量,运算时java虚拟机对它进行了转换,结果导致把一个int赋值给byte-----出错如果对b1 b2加上final就不会出错
final byte b1=1;
final byte b2=3;
byte b3=b1+b2;//不会出错,相信你看了上面的解释就知道原因了。ThreadLocal 详解
- ThreadLocal详解 [📄](./Java 多线程与并发/ThreadLocal 详解.md)
四、★JUC 锁
LockSupport 详解
JUC锁: LockSupport详解 [📄](./Java 多线程与并发/JUC 锁/LockSupport 详解.md)
锁核心类 AQS 详解
锁核心类AQS详解 [📄](./Java 多线程与并发/JUC 锁/锁核心类 AQS 详解.md)
ReentrantLock 详解
- ReentrantLock详解 [📄](./Java 多线程与并发/JUC 锁/ReentrantLock 详解.md)
ReentrantLock 相对于 synchronized 有以下特性:
可中断
可设置超时时间
可设置为公平锁
可设置多个条件变量(一个对象实例可以选择进入哪一个等待队列[不能分身])
与synchronized相同的是:都是支持可重入。
ReentrantLock 实例
/**
* 测试ReentrantLock锁中断
* 起个大早,去超市买菜。你要买三块鸡胸肉,发现只有一块,你让超市老哥帮你再那几块出来,但是他正在给其他的大妈大叔切鸡肉,
* 你等了很久,不耐烦了,拿了两份鸡腿代替了鸡胸肉
*/
public class TestInterruptLock {
public static void main(String[] args) {
ShopOldBro oldBro = new ShopOldBro();
List<String> yourShoppingList = new ArrayList<>();
yourShoppingList.add("三块鸡胸肉");
AngryYou you = new AngryYou(oldBro, yourShoppingList);
List<String> auntsShoppingList = new ArrayList<>();
auntsShoppingList.add("一只三黄鸡,帮忙切好");
AuntsAndUncles aunt = new AuntsAndUncles(oldBro, auntsShoppingList);
// 阿姨比你先
new Thread(() -> {
aunt.shopping();
}, "Aunt").start();
Thread youThread = new Thread(() -> {
you.shopping();
}, "You");
// 你后面来
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
youThread.start();
// 超市老哥在给阿姨切鸡肉呢,你等了很久,他就是一直不帮你拿鸡胸肉
System.out.println("你在等老哥帮你拿鸡胸肉。。。");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 你等了很久,那老哥一直不鸟你,一直在不停地给其他阿姨切鸡。。。你气愤地不买了
youThread.interrupt();
}
}
class AngryYou implements ICustomer {
List<String> shoppingLists;
ShopOldBro oldBro;
public AngryYou(ShopOldBro oldBro, List<String> shoppingLists) {
this.oldBro = oldBro;
this.shoppingLists = shoppingLists;
}
@Override
public void shopping() {
oldBro.doServing(shoppingLists.get(0));
}
}
class AuntsAndUncles implements ICustomer {
List<String> shoppingLists;
ShopOldBro oldBro;
public AuntsAndUncles(ShopOldBro oldBro, List<String> shoppingLists) {
this.oldBro = oldBro;
this.shoppingLists = shoppingLists;
}
@Override
public void shopping() {
oldBro.doServing(shoppingLists.get(0));
}
}
interface ICustomer {
void shopping();
}
class ShopOldBro {
private ReentrantLock lock = new ReentrantLock();
void doServing(String thing) {
try {
lock.lockInterruptibly(); // 只有lockInterruptibly()会抛出InterruptedException异常,lock()和tryLock()不会
System.out.println(Thread.currentThread().getName() + "-" + thing);
if (thing.contains("切")) { // 要切肯定花时间多啊
Thread.sleep(10 * 1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
System.out.println(Thread.currentThread().getName() + "-" + thing + "【中断,不买了】");
} finally {
lock.unlock();
}
}
}/**
* 测试ReentrantLock条件变量
* 简单示例:小明没有烟就不能干活,小芳没有饭就干不了活。还有两个小哥一个给小明送烟,一个给小芳送饭。
*/
public class Test_has {
static Boolean hascigarette=false;//是否有烟
static Boolean hasfood=false;//是否有饭
static ReentrantLock lock=new ReentrantLock();
static Condition cigarette_room = lock.newCondition();//等烟线程的休息室
static Condition food_room = lock.newCondition();//等饭线程的休息室
public static void main(String[] args) {
new Thread(()->{
lock.lock();
try {
while (!hascigarette){
try {
cigarette_room.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("小明有了烟开始干活");
}finally {
lock.unlock();
}
},"要烟的小明").start();
new Thread(()->{
lock.lock();
try {
while (!hasfood){
try {
food_room.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("小芳吃到饭开始干活");
}finally {
lock.unlock();
}
},"要饭的小芳").start();
try {
Thread.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(()->{
lock.lock();
try {
System.out.println("我来给小明送烟");
hascigarette=true;
cigarette_room.signalAll();//唤醒在无烟休息室的线程
}finally {
lock.unlock();
}
},"送烟小哥").start();
new Thread(()->{
lock.lock();
try {
System.out.println("我来给小芳送饭");
hasfood=true;
food_room.signalAll();//唤醒在无饭休息室的线程
}finally {
lock.unlock();
}
},"送饭小哥").start();
}
}ReentrantReadWriteLock 详解
ReentrantReadWriteLock详解 [📄](./Java 多线程与并发/JUC 锁/ReentrantReadWriteLock 详解.md)
重入锁、乐观锁、悲观锁、公平锁、非公平锁及锁的粒度
可重入锁
可重入锁也叫递归锁,它俩等同于一回事,指的是同一线程外层函数获得锁之后,内层递归函数仍然能获得该锁的代码,同一线程在外层方法获取锁的时候,再进入内层方法会自动获取锁。ReentrantLock 和 synchronized 就是典型的可重入锁。
可重入的前提条件:
监视器对象为同一个
内层方法的锁没有被其他线程占用,如果被占用,同样还要等待
/**
* 测试可重入锁
*/
public class TestReentrantLock {
public static void main(String[] args) {
IPhone phone1 = new IPhone12();
IPhone phone2 = new IPhone12();
new Thread(() -> {
phone1.sendSms();
}).start();
new Thread(() -> {
phone2.sendWeChatMsg();
}).start();
}
}
interface IPhone {
void sendSms();
void sendWeChatMsg();
}
class Mi10 implements IPhone {
@Override
public synchronized void sendSms() {
System.out.println(Thread.currentThread().getName() + "-sendSms~~~");
// 调用另一个加锁方法
sendWeChatMsg();
}
@Override
public synchronized void sendWeChatMsg() {
try {
Thread.sleep(2000); // synchronized 固定使用的是非公平锁,线程唤醒顺序由CPU调度决定
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "-sendWeChatMsg...");
}
}
class IPhone12 implements IPhone {
ReentrantLock lock = new ReentrantLock();
@Override
public void sendSms() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "-sendSms~~~");
// 调用另一个加锁方法
sendWeChatMsg();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
@Override
public void sendWeChatMsg() {
lock.lock();
try {
Thread.sleep(2000); // ReentrantLock 默认也是使用非公平锁,可以配置改变
System.out.println(Thread.currentThread().getName() + "-sendWeChatMsg...");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
乐观锁与悲观锁的区别对比
响应效率:如果需要非常高的响应速度,建议采用乐观锁方案,成功就执行,不成功就失败,不需要等待其他并发去释放锁。乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。
冲突频率:如果冲突频率非常高,建议采用悲观锁,保证成功率。冲突频率大,选择乐观锁会需要多次重试才能成功,代价比较大。
重试代价:如果重试代价大,建议采用悲观锁。悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
乐观锁如果有人在你之前更新了,你的更新应当是被拒绝的,可以让用户从新操作。悲观锁则会等待前一个更新完成。这也是区别。
随着互联网三高架构(高并发、高性能、高可用)的提出,悲观锁已经越来越少的被应用到生产环境中了,尤其是并发量比较大的业务场景。
乐观锁与悲观锁的使用场景
从上面对两种锁的介绍,知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
乐观锁常见的两种实现方式
版本号机制
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
简单例子:
假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。当需要对账户信息表进行更新的时候,需要首先读取version字段。
1) 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
2) 在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
3) 操作员 A 完成了修改工作,提交更新之前会先看数据库的版本和自己读取到的版本是否一致,一致的话,就会将数据版本号加1( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
4) 操作员 B 完成了操作,提交更新之前会先看数据库的版本和自己读取到的版本是否一致,但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,而自己读取到的版本号为1 ,不满足 “ 当前最后更新的version与操作员第一次读取的版本号相等 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。CAS 算法
即 compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数:
需要读写的内存值 V
进行比较的值 A
拟写入的新值 B
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
悲观锁的实现
传统的关系型数据库使用这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
Java里的synchronized同步锁、ReentrantLock锁的实现。
悲观锁的实现,往往依靠数据库提供的锁机制。在数据库中,悲观锁的流程如下:
在对记录进行修改前,先尝试为该记录加上排他锁(exclusive locks)。
如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。具体响应方式由开发者根据实际需要决定。
如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
期间如果有其他对该记录做修改或加排他锁的操作,都会等待解锁或直接抛出异常。
拿比较常用的 MySql Innodb 引擎举例,来说明一下在 SQL 中如何使用悲观锁。
要使用悲观锁,必须关闭 MySQL 数据库的自动提交属性。因为 MySQL 默认使用 autocommit 模式,也就是说,当执行一个更新操作后,MySQL 会立刻将结果进行提交。(sql语句:set autocommit=0)
以电商下单扣减库存的过程说明一下悲观锁的使用:
(手动管理的事务不会自动提交)
在对id = 1的记录修改前,先通过 for update 的方式进行加锁,然后再进行修改。这就是比较典型的悲观锁策略。
如果以上修改库存的代码发生并发,同一时间只有一个线程可以开启事务并获得id=1的锁,其它的事务必须等本次事务提交之后才能执行。这样可以保证当前的数据不会被其它事务修改。
上面提到,使用 select…for update 会把数据给锁住,不过需要注意一些锁的级别,MySQL InnoDB 默认行级锁。行级锁都是基于索引的,如果一条 SQL 语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
悲观锁主要分为共享锁和排他锁
共享锁(shared locks)又称为读锁,简称S锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
排他锁(exclusive locks)又称为写锁,简称X锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据行读取和修改。
公平锁
锁的公平与不公平:
公平锁是指线程获得锁的顺序按照FIFO的原则,先排队的先得。
非公平锁指每个线程都先要竞争锁,不管排队先后,所以后到的线程有可能无需进入等待队列直接竞争到锁。
非公平锁虽然可能导致某些线程饥饿,但是锁的吞吐量是公平锁好几倍。
synchronized是一个典型的非公平锁方案,而且没法做成公平锁。
3.6 ReentrantLock 公平锁实现
什么时候获取锁
获取锁成功时的操作
获取锁失败时操作
线程重入时操作
先判断在当前线程之前是否有其他线程在等待获取锁,如果没有先驱线程等待锁,就通过compareAndSetState()尝试获取锁;如果有先驱线程就直接返回false,因为是公平锁,遵循先到先得的原则,tryAcquire()返回false后,当前队列就会进入等待队列(acquire()方法)。
非公平锁
synchronized 非公平锁实现
synchronized监视器锁(Monitor)本质是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现。每个对象都对应于一个可称为" 互斥锁"的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
互斥锁:用于保护临界区,确保同一时间只有一个线程访问数据。对共享资源的访问,先对互斥量进行加锁,如果互斥量已经上锁,调用线程会阻塞,直到互斥量被解锁。在完成了对共享资源的访问后,要对互斥量进行解锁。
没有使用同步队列,一有新进程需要获取锁,将和之前等待的线程一起竞争。
ReentrantLock 非公平锁实现
什么时候获取锁
获取锁成功时的操作
获取锁失败时操作
线程重入时操作
线程一进来就通过CAS获取锁,如果获取成功就设置线程独占,获取失败则自旋。
五、JUC 集合 Map、List、Set、Queue
ConcurrentHashMap 详解
ConcurrentHashMap详解 [📄](./Java 多线程与并发/JUC 集合/ReentrantReadWriteLock 详解.md)
CopyOnWriteArrayList 详解
ConcurrentLinkedQueue 详解
BlockingQueue 阻塞队列
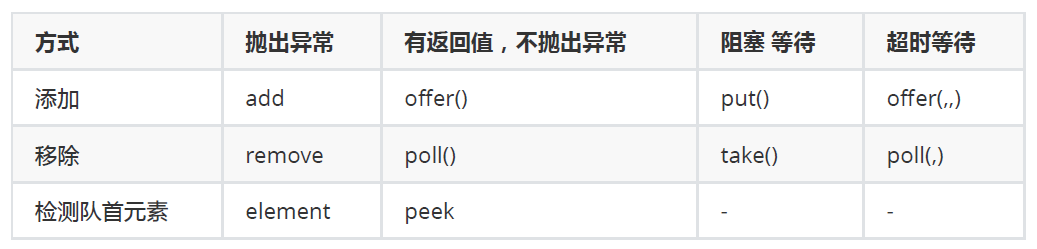
ArrayBlockingQueue 数组有界阻塞队列
LinkedBlockingQueue 链表有界阻塞队列
LinkedTransferQueue 链表无界阻塞队列
LinkedBlockingDeque 链表双向阻塞队列
PriorityBlockingQueue 优先级排序无界阻塞队列
DelayQueue 延时无界阻塞队列
SynchronousQueue 同步有界阻塞队列
只能存储一个元素,进去一个元素,必须等待取出来之后,才能再往里面放一个元素!
AbstractQueue 非阻塞队列
ConcurrentLinkedQueue 链表无界非阻塞队列
六、★JUC 线程池
FutureTask 详解
ThreadPoolExecutor 详解
三大方法、七大参数、四种拒绝策略
线程池的好处
减少线程创建和销毁的开销。
直接从线程池里取,提高响应的速度。
方便线程复用管理,及控制最大并发数。
三大方法

/**
* Executors 三大方法
*/
static void testThreeMethod() {
ExecutorService threadPool;
// Executors 创建单个线程的线程池
//threadPool = Executors.newSingleThreadExecutor();
// 创建指定线程数量的线程池
//threadPool = Executors.newFixedThreadPool(5);
// 创建可伸缩的线程池
threadPool = Executors.newCachedThreadPool();
try {
for (int i = 0; i < 10; i++) {
// 使用线程池创建并执行线程
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "-run");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 线程池用完,关闭线程池,不关闭程序不会结束
threadPool.shutdown();
}
}七大参数
Executors创建线程池的三种方法,本质都是调用new ThreadPoolExecutor(…)。
public ThreadPoolExecutor(int corePoolSize, // 线程池核心大小
int maximumPoolSize, // 线程池最大线程数量
long keepAliveTime, // 保持线程存活时间,超时将会被销毁
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 阻塞队列
ThreadFactory threadFactory, // 线程工厂,一般不用改动
RejectedExecutionHandler handler // 拒绝策略
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}四种拒绝策略
手动创建线程池
/**
* new ThreadPoolExecutor.AbortPolicy() // 银行满了,不接待后面进来的人,但可能会有个别人闹事,所以会抛出异常
* new ThreadPoolExecutor.CallerRunsPolicy() // 哪来的去哪里
* new ThreadPoolExecutor.DiscardPolicy() // 队列满了,在入口通知请到别的地方去办理,不会抛出异常
* new ThreadPoolExecutor.DiscardOldestPolicy() // 队列满了,尝试去和最早的竞争(你可以等,看看有没有人中途离开),也不会抛出异常
*/
ExecutorService createThreadPool() {
ExecutorService threadPool = new ThreadPoolExecutor(5, // 线程池核心大小
20, // 线程池最大容量
5, // 保持存活时间,超过时间,阻塞队列中的线程将会被结束掉,但核心线程不会结束
TimeUnit.MINUTES, // 时间单位
new LinkedBlockingQueue<>(15), // 阻塞队列,设置大小值为线程池最大容量-核心容量
Executors.defaultThreadFactory(), // 线程创建工厂,一般默认不改动
new ThreadPoolExecutor.DiscardOldestPolicy() // 拒绝策略
);
return threadPool;
}线程池大小设置

ThreadPoolExecutor 常见方法
execute()
方法实际上是Executor中声明的方法,在ThreadPoolExecutor进行了具体的实现,这个方法是ThreadPoolExecutor的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。
submit()
方法是在ExecutorService中声明的方法,在AbstractExecutorService就已经有了具体的实现,在ThreadPoolExecutor中并没有对其进行重写,这个方法也是用来向线程池提交任务的,但是它和execute()方法不同,它能够返回任务执行的结果,去看submit()方法的实现,会发现它实际上还是调用的execute()方法,只不过它利用了Future来获取任务执行结果。submit可以提交Runnable和 Callable。
shutdown()
将线程池状态置为SHUTDOWN。平滑的关闭ExecutorService,当此方法被调用时,ExecutorService停止接收新的任务并且等待已经提交的任务(包含提交正在执行和提交未执行)执行完成。当所有提交任务执行完毕,线程池即被关闭。所以手动调用shotdown方法,可以不必担心存在剩余任务没有执行的情况。
shutdownNow()
将线程池状态置为STOP。跟shutdown()一样,先停止接收外部提交的任务,忽略队列里等待的任务,尝试将正在跑的任务interrupt中断,返回未执行的任务列表。
对于那些正在执行的task,并不能保证他们就一定会直接停止执行,或许他们会暂停,或许会执行直到完成,但是ExecutorService会尽力关闭所有正在运行的task。
awaitTermination(long timeout, TimeUnit unit)
awaitTermination方法接收timeout和TimeUnit两个参数,用于设定超时时间及单位。当等待超过设定时间时,会监测ExecutorService是否已经关闭,若关闭则返回true,否则返回false。一般情况下会和shutdown方法组合使用。
第一个参数指定的是时间,第二个参数指定的是时间单位(当前是秒)。返回值类型为boolean型。
如果等待的时间超过指定的时间,但是线程池中的线程运行完毕,那么awaitTermination()返回true。执行分线程已结束。
如果等待的时间超过指定的时间,但是线程池中的线程未运行完毕,那么awaitTermination()返回false。不执行分线程已结束。
如果等待时间没有超过指定时间,等待!
可以用awaitTermination()方法来判断线程池中是否有继续运行的线程。
isShutdown()
线程池是否已关闭。
isTerminated()
线程池是否已终止。
实际开发中线程池的使用
ScheduledThreadPoolExecutor 详解
七、JUC 原子类
Atomic 原子类型
AtomicBoolean
AtomicInteger
AtomicIntegerArray
AtomicIntegerFieldUpdater<T>
AtomicLong
AtomicLongArray
AtomicLongFieldUpdater<T>
AtomicReference<V>
AtomicStampedReference<V>
LongAdder 原子累加器
比AtomicLong的性能要高几倍。
CAS(compare and swap)比较并交换
什么是 CAS
CAS(Compare And Swap),即比较并交换。是解决多线程并行情况下使用锁造成性能损耗的一种机制,CAS 操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值。CAS 有效地说明了“我认为位置V应该包含值A;如果包含该值,则将B放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。
在 Java 中,sun.misc.Unsafe 类提供了硬件级别的原子操作来实现这个 CAS。java.util.concurrent包下大量的类都使用了这个 Unsafe.java 类的 CAS 操作。
CAS 典型应用
java.util.concurrent.atomic 包下的类大多是使用 CAS 操作来实现的,比如,AtomicInteger、AtomicBoolean、AtomicLong。一般来说在竞争不是特别激烈的时候,使用该包下的原子操作性能比使用 synchronized 关键字的方式高效的多(查看getAndSet(),可知如果资源竞争十分激烈的话,这个 for 循环可能会持续很久都不能成功跳出。不过这种情况可能需要考虑降低资源竞争才是)。
CAS 底层实现原理
CAS通过调用sun.misc.unsafe类中JNI的代码实现(JNI:Java Native Interface),允许java调用其他语言,而【compareAndSwapXXX】系列的方法就是借助“C语言”来调用cpu底层指令实现的。
以常用的【Intel x86】平台来说,最终映射到cpu的指令为【cmpxchg】(compareAndChange),这是一个原子指令,cpu执行此命令时,实现比较替换操作。
那么问题来了,现在计算机动不动就上百核,【cmpxchg】怎么保证多核下的线程安全?
系统底层进行CAS操作时,会判断当前系统是否为多核系统,如果是,就给【总线】加锁,只有一个线程对总线加锁成功,加锁成功之后会执行CAS操作,也就是说CAS的原子性是平台级别的。
业务逻辑流程图:
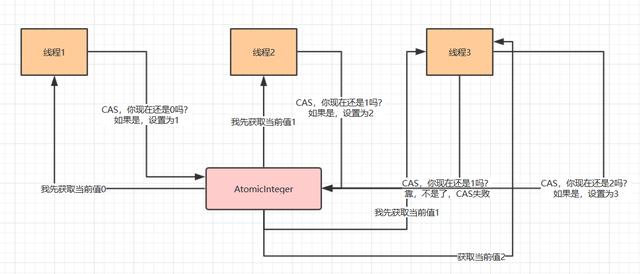
假如说有3个线程并发的要修改一个 AtomicInteger 的值,底层机制如下:
首先,每个线程都会先获取当前的值。接着走一个原子的 CAS 操作,原子的意思就是这个 CAS 操作一定是自己完整执行完的,不会被别人打断。
然后 CAS 操作里,会比较一下,现在的值是不是刚才获取到的那个值。如果是,说明没人改过这个值,那设置成累加1之后的一个值。
同理,如果有人在执行 CAS 的时候,发现之前获取的值跟当前的值不一样,会导致 CAS 失败。失败之后,进入一个无限循环,再次获取值,接着执行 CAS 操作。
CAS 的缺点
ABA 问题
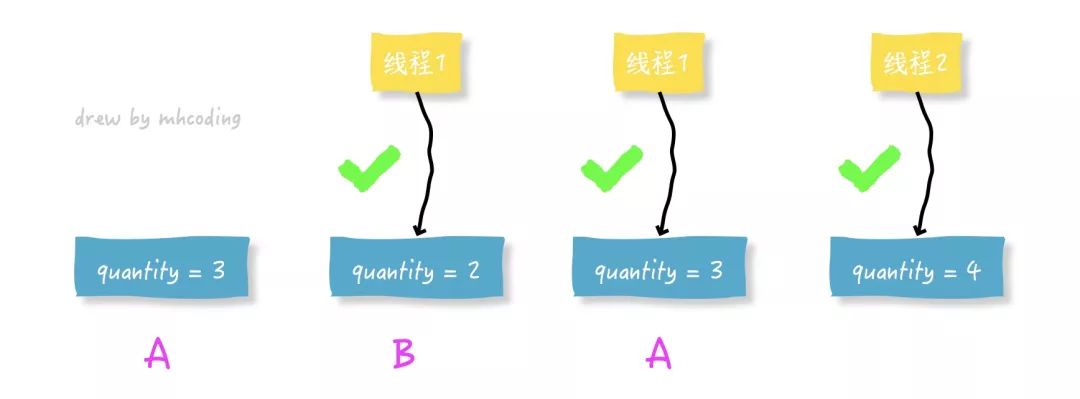
如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回A,那CAS操作就会误认为它从来没有被修改过。这个问题被称为CAS操作的 "ABA"问题。
如何解决ABA问题?
高并发下,其他线程自旋等待时间长开销大
自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。
如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
只能保证一个共享变量的原子操作
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作。所以可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作。
CAS 性能优化
从流程图其实可以看出来,比如说大量的线程同时并发修改一个 AtomicInteger,可能有很多线程会不停的自旋,进入一个无限重复的循环中。这些线程不停地获取值,然后发起 CAS 操作,但是发现这个值被别人改过了,于是再次进入下一个循环,获取值,发起 CAS 操作又失败了,再次进入下一个循环。在大量线程高并发更新 AtomicInteger 的时候,这种问题可能会比较明显,导致大量线程空循环,自旋转,性能和效率都不是特别好。那么如何优化呢?
Java8 有一个新的类,LongAdder,它就是尝试使用分段 CAS 以及自动分段迁移的方式来大幅度提升多线程高并发执行 CAS 操作的性能,这个类具体是如何优化性能的呢?如图:
LongAdder 核心思想就是热点分离,这一点和 ConcurrentHashMap 的设计思想相似。就是将 value 值分离成一个数组,当多线程访问时,通过 hash 算法映射到其中的一个数字进行计数。而最终的结果,就是这些数组的求和累加。这样一来,就减小了锁的粒度。
原子引用解决 ABA 问题
CAS对数据修改时,可能会出现对数据修改两次,修改后值与之前相同的情况,因此会认定为未修改,此类问题被称为ABA问题,为了解决此类问题可以使用乐观锁,对每次记录新增一个记录,每次修改记录+1。
JDK 1.5以后的AtomicStampedReference类就提供了此种能力,其中的compareAndSet方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
解决CAS中ABA问题的两种解决方案,他们的原理是相同的,就是添加一个标记来记录更改,两者的区别:
AtomicMarkableReference利用一个boolean类型的标记来记录,只能记录它改变过,不能记录改变的次数。
AtomicStampedReference利用一个int类型的标记来记录,它能够记录改变的次数,通常采用这种方式。
AtomicStampedReference 使用案例:
public class CasABADemo2 {
// 注意,compareAndSet比较的是引用,当Integer的值不在[-128, 127]范围时,==比较返回的是false。
private static AtomicStampedReference<Integer> count = new AtomicStampedReference<>(0, 1);
public static void main(String[] args) {
System.out.println("mainThread 当前count值为: " + count.getReference() + ",版本号为:" + count.getStamp());
Thread mainThread = new Thread(() -> {
try {
int expectStamp = count.getStamp();
int updateStamp = expectStamp + 1;
int expectCount = count.getReference();
int updateCount = expectCount + 1;
System.out.println("mainThread 期望值:" + expectCount + ", 修改值:" + updateCount);
Thread.sleep(2000);//休眠2000s ,释放cpu
boolean result = count.compareAndSet(expectCount, updateCount, expectStamp, updateStamp);
System.out.println("mainThread 修改count : " + result);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread otherThread = new Thread(() -> {
try {
Thread.sleep(20);//确保主线程先获取到cpu资源
} catch (InterruptedException e) {
e.printStackTrace();
}
count.compareAndSet(count.getReference(), count.getReference() + 1, count.getStamp(), count.getStamp() + 1);
System.out.println("其他线程先修改 count 为:" + count.getReference() + " ,版本号:" + count.getStamp());
count.compareAndSet(count.getReference(), count.getReference() - 1, count.getStamp(), count.getStamp() + 1);
System.out.println("其他线程又修改 count 为:" + count.getReference() + " ,版本号:" + count.getStamp());
});
mainThread.start();
otherThread.start();
}
}Unsafe 魔法类原理
Java中提供了对CAS操作的支持,具体在【sun.misc.unsafe】类中(官方不建议直接使用)。
Unsafe类中都是本地方法,使用JNI的代码实现(JNI:Java Native Interface),调用C语言代码。
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6)参数var1:表示要操作的对象
参数var2:表示要操作对象中属性地址的偏移量
参数var4:表示需要修改数据的期望的值
参数var5:表示需要修改为的新值
八、JUC 辅助工具类
CountDownLatch 减法计数器
等待多线程完成的 CountDownLatch
CountDownLatch允许一个或多个线程等待其他线程完成操作。也就是说通过使用CountDownLatch工具类,可以让一组线程等待彼此执行完毕后在共同执行下一个操作。具体流程如下图所示,箭头表示任务,矩形表示栅栏,当三个任务都到达栅栏时,栅栏后wait的任务才开始执行。
CountDownLatch维护有个int型的状态码,每次调用countDown时状态值就会减1;调用wait方法的线程会阻塞,直到状态码为0时才会继续执行。
在多线程协同工作时,可能需要等待其他线程执行完毕之后,主线程才接着往下执行。首先可能会想到使用线程的join方法(调用join方法的线程优先执行,该线程执行完毕后才会执行其他线程),显然这是可以完成的。
使用Thread.join()方法实现:
public class RunningRaceTest {
public static void main(String[] args) throws InterruptedException {
Thread runner1 = new Thread(new Runner(), "1号");
Thread runner2 = new Thread(new Runner(), "2号");
Thread runner3 = new Thread(new Runner(), "3号");
Thread runner4 = new Thread(new Runner(), "4号");
Thread runner5 = new Thread(new Runner(), "5号");
runner1.start();
runner2.start();
runner3.start();
runner4.start();
runner5.start();
runner1.join();
runner2.join();
runner3.join();
runner4.join();
runner5.join();
// 裁判等待5名选手准备完毕
System.out.println("裁判:比赛开始~~");
}
}
class Runner implements Runnable {
@Override
public void run() {
try {
int sleepMills = ThreadLocalRandom.current().nextInt(1000);
Thread.sleep(sleepMills);
System.out.println(Thread.currentThread().getName() + " 选手已就位, 准备共用时: " + sleepMills + "ms");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}Thread.join()完全可以实现这个需求,不过存在一个问题,如果调用join的线程一直存活,则当前线程则需要一直等待。这显然不够灵活,并且当前线程可能会出现死等的情况。
jdk1.5之后的并发包中提供了CountDownLatch并发工具了,也可以实现join的功能,并且功能更加强大。
// 参赛选手线程
class Runner implements Runnable {
private CountDownLatch countdownLatch;
public Runner(CountDownLatch countdownLatch) {
this.countdownLatch = countdownLatch;
}
@Override
public void run() {
try {
int sleepMills = ThreadLocalRandom.current().nextInt(1000);
Thread.sleep(sleepMills);
System.out.println(Thread.currentThread().getName() + " 选手已就位, 准备共用时: " + sleepMills + "ms");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 准备完毕,举手示意
countdownLatch.countDown();
}
}
}
public class RunningRaceTest {
public static void main(String[] args) throws InterruptedException {
// 使用线程池的正确姿势
int size = 5;
AtomicInteger counter = new AtomicInteger();
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(size, size, 1000, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100), (r) -> new Thread(r, counter.addAndGet(1) + " 号 "), new ThreadPoolExecutor.AbortPolicy());
CountDownLatch countDownLatch = new CountDownLatch(5);
for (int i = 0; i < size; i++) {
threadPoolExecutor.submit(new Runner(countDownLatch));
}
// 裁判等待5名选手准备完毕
countDownLatch.await(); // 为了避免死等,也可以添加超时时间
System.out.println("裁判:比赛开始~~");
threadPoolExecutor.shutdownNow();
}
}
输出结果:
5 号 选手已就位, 准备共用时: 20ms
4 号 选手已就位, 准备共用时: 156ms
1 号 选手已就位, 准备共用时: 288ms
2 号 选手已就位, 准备共用时: 519ms
3 号 选手已就位, 准备共用时: 945ms
比赛开始~~CyclicBarrier 循环同步屏障
CyclicBarrier可以实现CountDownLatch一样的功能,不同的是CountDownLatch属于一次性对象,声明后只能使用一次,而CyclicBarrier可以循环使用。
从字面意义上来看,CyclicBarrier表示循环的屏障,当一组线程全部都到达屏障时,屏障才会被移除,否则只能阻塞在屏障处。
public class RunningRace {
public static void main(String[] args) {
// 使用线程池的正确姿势
int size = 5;
AtomicInteger counter = new AtomicInteger();
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(size, size, 1000, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100), (r) -> new Thread(r, counter.addAndGet(1) + " 号 "), new ThreadPoolExecutor.AbortPolicy());
CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> System.out.println("裁判:比赛开始~~"));
for (int i = 0; i < 10; i++) {
threadPoolExecutor.submit(new Runner(cyclicBarrier));
}
}
}
class Runner implements Runnable {
private CyclicBarrier cyclicBarrier;
public Runner(CyclicBarrier countdownLatch) {
this.cyclicBarrier = countdownLatch;
}
@Override
public void run() {
try {
int sleepMills = ThreadLocalRandom.current().nextInt(1000);
Thread.sleep(sleepMills);
System.out.println(Thread.currentThread().getName() + " 选手已就位, 准备共用时: " + sleepMills + "ms" + cyclicBarrier.getNumberWaiting());
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}CountDownLatch 与 CyclicBarrier 区别
相同点:
- 它们的使用场景:允许一个或多个线程等待其他线程完成操作,即当指定数量线程执行完某个操作再继续执行下一个操作。
不同点:
CountDownLatch创建后只能使用一次,而CyclicBarrier可以循环使用,并且CyclicBarrier功能更完善。
CountDownLatch内部的状态是基于AQS中的状态信息,而CyclicBarrier中的状态值是单独维护的,使用ReentrantLock加锁保证并发修改状态值的数据一致性。
Semaphore 信号量
Semaphore [ˈseməfɔː(r)] 用于限制同一时间最大允许执行的线程数目上限。
海底捞排队:
private static final int MAX_COUNT = 5;
private static class Person implements Runnable {
private Semaphore semaphore;
public Person(Semaphore semaphore) {
this.semaphore = semaphore;
}
@Override
public void run() {
try {
System.out.println("Thread " + Thread.currentThread().getName() + " is waiting.");
semaphore.acquire();
System.out.println("Thread " + Thread.currentThread().getName() + " is eating.");
TimeUnit.SECONDS.sleep(RandomUtils.nextInt(1, 3));
System.out.println("Thread " + Thread.currentThread().getName() + " ate up.");
} catch (Exception e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}
}
public static void main(String[] args) {
// 使用公平锁,保证叫号尽量的公平
Semaphore semaphore = new Semaphore(MAX_COUNT, true);
for (int i = 0; i < 20; i++) {
new Thread(new Person(semaphore), String.valueOf(i)).start();
}
}Phaser
Exchanger
九、Fork/Join 原理及应用
什么是 ForkJoin
从JDK1.7开始,Java提供Fork/Join框架用于并行执行任务,它的思想就是将一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。
这种思想和大数据里面的MapReduce很像(input --> split --> map --> reduce --> output)
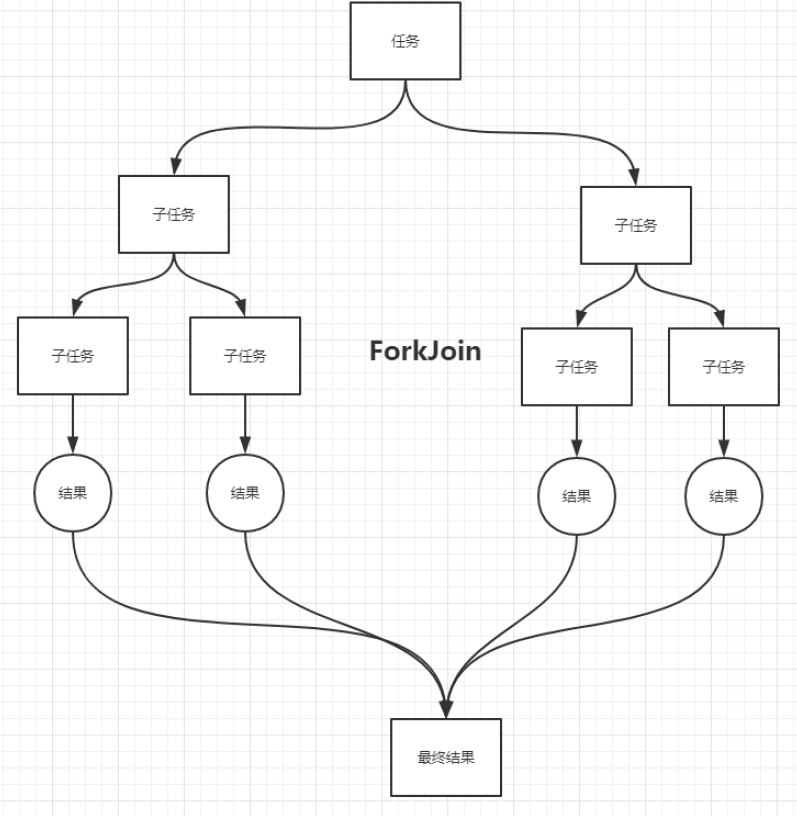
ForkJoin 特点:工作窃取。内部使用双端队列。
ForkJoin 测试实例
public class TestForkJoin {
public static void main(String[] args) throws ExecutionException, InterruptedException {
test1(); // 12224
test2(); // 10038
test3(); // 153
}
// 普通程序员
public static void test1() {
Long sum = 0L;
long start = System.currentTimeMillis();
for (Long i = 1L; i <= 10_0000_0000; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println("sum=" + sum + " 时间:" + (end - start));
}
// 会使用ForkJoin
public static void test2() throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinDemo(0L, 10_0000_0000L);
ForkJoinTask<Long> submit = forkJoinPool.submit(task); // 提交任务
Long sum = submit.get();
long end = System.currentTimeMillis();
System.out.println("sum=" + sum + " 时间:" + (end - start));
}
public static void test3() {
long start = System.currentTimeMillis();
// Stream并行流
long sum = LongStream.rangeClosed(0L,
10_0000_0000L).parallel().reduce(0, Long::sum);
long end = System.currentTimeMillis();
System.out.println("sum=" + sum + "时间:" + (end - start));
}
}
/**
* 求和计算的任务
* 3000 6000(ForkJoin) 9000(Stream并行流) 市场饱和了,仅仅会使用照样也难拿到高工资了,现在是面试造火箭,工作拧螺丝
* // 如何使用 forkjoin
* // 1、forkjoinPool 通过它来执行
* // 2、计算任务 forkjoinPool.execute(ForkJoinTask task)
* // 3. 计算类要继承 ForkJoinTask
*/
class ForkJoinDemo extends RecursiveTask<Long> {
private Long start; // 1
private Long end; // 1990900000
// 临界值
private Long temp = 10000L;
public ForkJoinDemo(Long start, Long end) {
this.start = start;
this.end = end;
}
// 计算方法
@Override
protected Long compute() {
if ((end - start) < temp) {
Long sum = 0L;
for (Long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else { // forkjoin 递归
long middle = (start + end) / 2; // 中间值
ForkJoinDemo task1 = new ForkJoinDemo(start, middle);
task1.fork(); // 拆分任务,把任务压入线程队列
ForkJoinDemo task2 = new ForkJoinDemo(middle + 1, end);
task2.fork(); // 拆分任务,把任务压入线程队列
return task1.join() + task2.join();
}
}
}十、CompletableFuture 异步回调
CompletableFuture设计的初衷:对将来的某个事件的结果进行建模。说白了就是对程序的各种运行结果做了方法封装。跟JavaScript里面的Ajax异步回调类似。
CompletableFuture 测试实例
/**
* 异步调用:CompletableFuture
* 类似Ajax
* 异步执行
* 成功回调
* 失败回调
*/
public class TestCompletableFuture {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 没有返回值的 runAsync 异步回调
CompletableFuture<Void> completableFuture =
CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "runAsync=>Void");
});
System.out.println("======================================");
System.out.println(completableFuture.get()); // 获取阻塞执行结果
// 有返回值的 supplyAsync 异步回调
// ajax,成功和失败的回调
// 返回的是错误信息;
CompletableFuture<Integer> completableFuture2 =
CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName() + "supplyAsync=>Integer");
int i = 10 / 0;
return 1024;
});
System.out.println(completableFuture2.whenComplete((t, u) -> {
System.out.println("t=>" + t); // 正常的返回结果
System.out.println("u=>" + u); // 错误信息 java.util.concurrent.CompletionException:java.lang.ArithmeticException: /by zero
}).exceptionally((e) -> {
System.out.println(e.getMessage());
return 233; // 可以获取到错误的返回结果
}).get());
/**
* succee Code 200
* error Code 404 500
*/
}
}